百度智能云天工物聯網平臺TSDB又添利器,SQL挖掘更多數據價值
經過二十多年的發展,伴隨著AI、大數據、云計算等技術的突飛猛進,物聯網的價值逐漸凸顯,成為了互聯網和傳統公司爭相布局之地。而作為物聯網領域數據存儲的首選,時序數據庫也進入人們的視野。
百度智能云在時序數據庫領域布局較早。早在2016年7月,百度智能云就在其天工物聯網平臺上發布了TSDB,這是國內首個多租戶的分布式時序數據庫產品,能夠支持制造、交通、能源、智慧城市等多個產業領域。2018年5月,百度智能云天工平臺在TSDB上加持了SQL引擎,成為首個支持SQL的云上時序數據庫服務,至此用戶可以更加熟悉方便地對數據進行操作,同時充分利用SQL函數的計算能力,挖掘數據價值。
本月,百度智能云天工TSDB的SQL引擎正式對外開放,所有套餐用戶均可使用SQL查詢功能。接下來,本文會從以下幾個方面帶你全方位的了解百度智能云天工TSDB上的SQL生態。
為什么TSDB需要SQL支持?
百度智能云天工TSDB一直有完整的API接口查詢支持,在此基礎上,現在又正式開放了SQL引擎,其中的原因有以下幾個方面:
首先,SQL的學習成本較低,對于技術人員而言,更符合日常使用習慣;即使是非技術人員,學習起來也很容易上手,可以省去熟悉API的學習成本。
其次,從可支持查詢的場景而言,因為API接口的格式相對固定,雖然可以支持絕大部分的查詢場景,但是相對來說,不如SQL可表達的語義豐富,一個典型的場景是TSDB中多個metric的聯合查詢,使用SQL中的join即可很方便的實現。
再者,SQL生態可以更方便的對接BI系統,通過SQL查詢功能,TSDB數據庫可以和現有的BI平臺實現無縫對接。
最后,無論是傳統的數據存儲服務或者計算框架,都有自己對應的SQL生態,例如HiveSql,SparkSql。百度智能云天工TSDB作為專注于時序數據的存儲服務,也應該有對應的SQL生態。
TSDB SQL引擎能做什么?
TSDB支持標準ANSI SQL語義,查詢數據的體驗與傳統的SQL體驗一樣簡潔明了。用戶使用TSDB的SQL引擎,可以像API接口一樣訪問TSDB的時序數據,同時還可以利用SQL強大的計算函數能力。
讓我們先通過一個簡單的示例,來了解下如何在TSDB上使用SQL:
假設有一個智能電表監控的物聯網集成方案,采集了智能電表的各個監控點的數據。在TSDB中這樣組織(如下圖),metric為SmartMeter,表示TSDB存的是智能電表的數據,每個電表有power和current兩個域(field),用兩個tag,即meterID和city,來代表每個數據點來自哪個電表ID和城市。電表每5s上傳一次功率值和電流值。
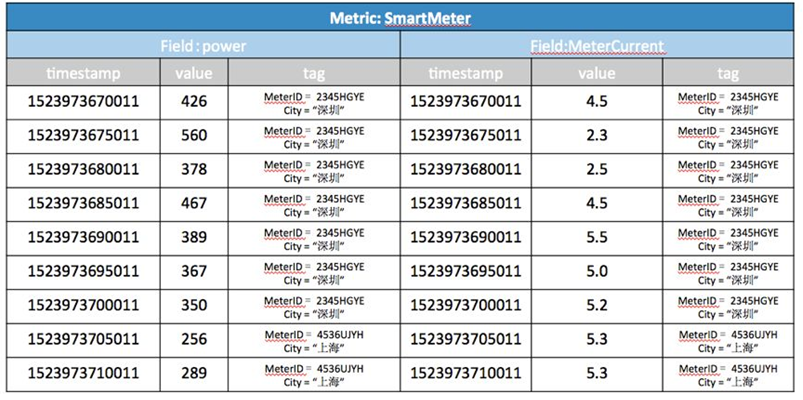
可以將上表看成一個二維表,針對二維表來寫SQL語句。
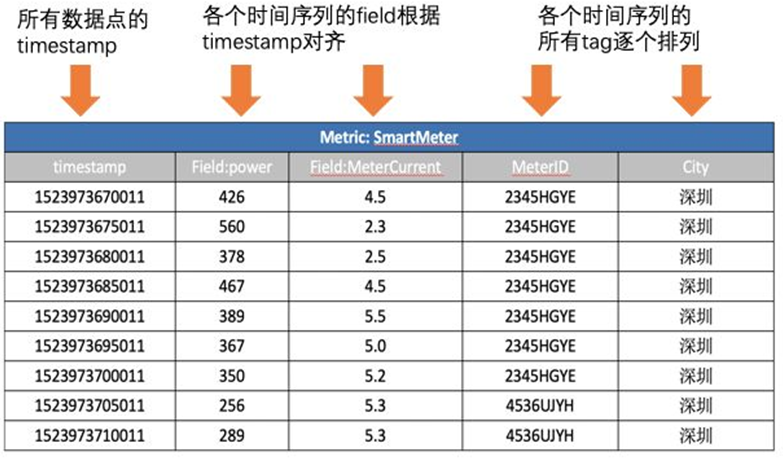
做完這些基礎工作后,我們來看具體場景下如何應用SQL語句來解決問題。
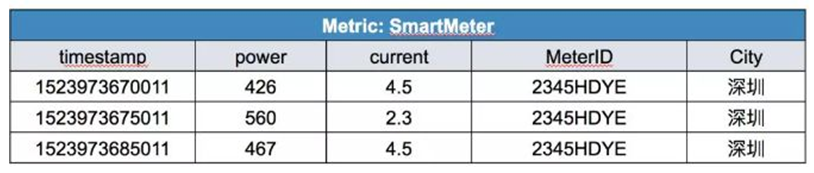
- 應用場景一:要過濾功率值大于400、電流值小于5,電表ID為2345HDYE的數據:
select timestamp, power, current,MeterID, City from SmartMeter where power > 400 and current<5 and MeterID= ' 2345HDYE'。
得到數據如下:
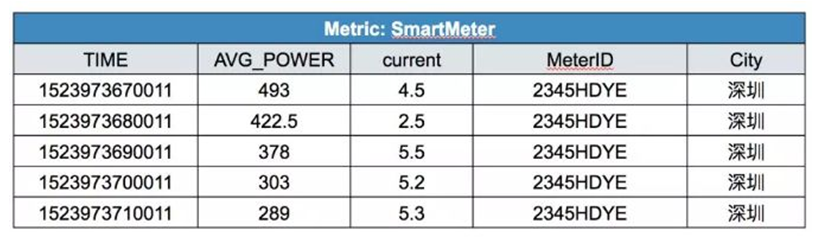
- 應用場景二:電表ID為2345HDYE的電表中,返回每10秒的功率平均值:
- select time_bucket(timestamp, '10seconds') as TIME, avg(power) as AVG_POWER, current, City from SmartMeter groupby time_bucket(timestamp, '10 seconds') order by TIME;
得到數據如下:
從上面的示例可以看到,用戶可以像訪問RDS一樣使用SQL訪問TSDB,支持字段過濾,排序,分組,聚合等常用操作。同時因為時序數據的特性,還可以使用time_bucket來計算帶時間窗口的聚合函數。
除了以上示例中所提到的,TSDB SQL的查詢功能盡可能的和API查詢接口對齊,這樣用戶就可以在兩種查詢方式上靈活切換,具體包括:
- 所有類型的域的查詢:TSDB現在支持整型、浮點型、字符串類型和Bytes類型。
- 對于原始數據的掃描、支持filter、orderBy、limit等常用語義。
- 對于函數計算場景,支持SUM、AVG、COUNT等常用聚合函數,并支持按照tag、時間窗口等分組;同時支持包括floor、abs等常用的計算函數。
除了以上和API接口保持一致的功能之外,TSDB SQL還支持:多metric的join操作,可用于不同metric之間的聯合查詢。
TSDB SQL引擎性能優化
數據查詢引擎的架構一般分為存儲層和計算層,前者負責對接數據源和原始數據的讀取;后者負責生成查詢計劃并做優化,以便更高效地從存儲層獲取數據。在這一部分,我們將介紹TSDB SQL引擎在計算層進行的查詢優化方面的工作。
計算層對查詢計劃的優化主要分為:基于成本的優化(Cost-Based Optimization)和基于規則的優化(Rule-Based Optimization)。使用CBO時,計算層會在多個查詢計劃間挑選一個成本最低的查詢計劃執行,在評估成本時可能需要用到存儲層提供的一些數據相關信息。而使用RBO更多的是使用一些規則,在對原始查詢計劃做等價變換的基礎上,不斷優化出性能更優的查詢計劃,其中比較常見的規則有謂詞下推,列裁剪等等,這里以謂詞下推為例作下簡要介紹。
謂詞下推(Predicate Pushdown)的思路是通過將SQL語句中WHERE 子句中的謂詞移到盡可能離數據源靠近的位置,從而能夠提早進行數據過濾并有可能更好地利用索引。下面通過一個例子來說明:
繼續利用上一章節中的場景,假設我們除了SmartMeter這個metric之外,還有另外一個metric來記錄電表的溫度:
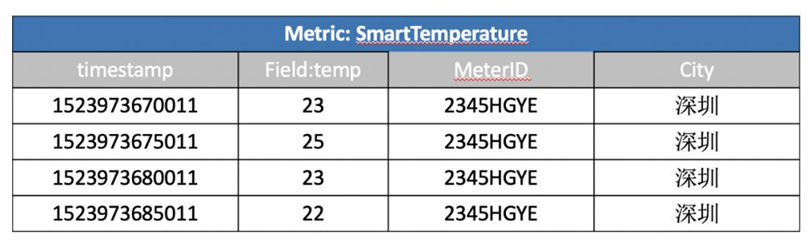
現在需要join這兩個metric來對特定的電表進行聯合查詢,SQL語句如下:
- select * from martMeter joinSmartTemperature on SmartMeter.MeterID = SmartTemperature.MeterID where MeterID= ' 2345HDYE';
針對上述的SQL語句,會生成如下左圖的原始查詢計劃:虛線以上可以認為是計算層生成的查詢計劃,虛線以下對應存儲層的數據源。這個查詢計劃使用TableScan算子將兩個metric的數據掃描出來,然后完成join操作,并在join之后的結果上做“MeterID= ' 2345HDYE”的條件過濾,最后輸出結果。
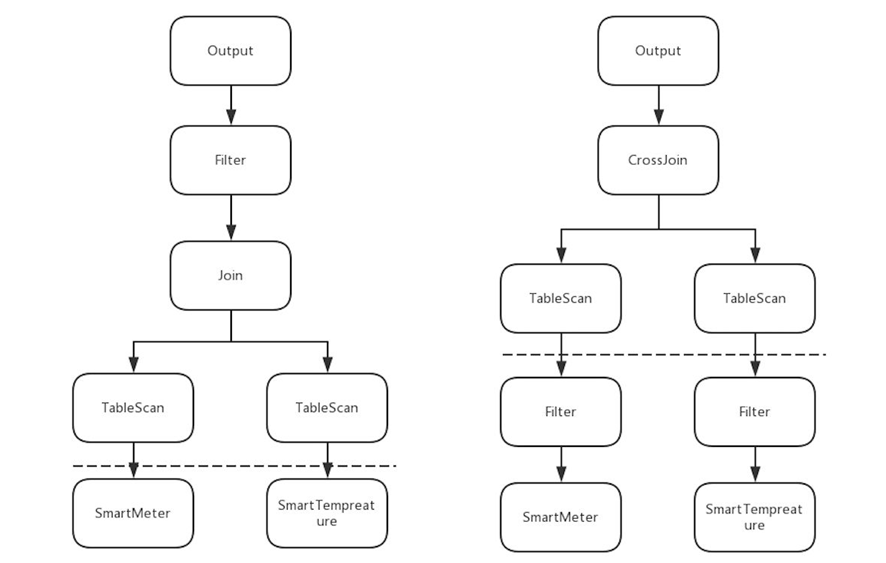
而右圖是經過"謂詞下推"優化之后的查詢計劃,可以看到,filter算子也就是“MeterID = ' 2345HDYE”的過濾,被下推到了TableScan算子下面,這樣的調整有什么好處呢?
首先,TableScan算子不再需要對原始數據進行全表掃描,只需要獲取經過“MeterID = ' 2345HDYE”過濾之后的數據,從數據量來說得到了縮減。
其次,如果SmartMeter和SmartTempreture作為數據源,本身就對MeterID這個字段的過濾有優化的話,查詢性能就能得到進一步的提升,這也就是上面提到的更好的利用數據源的索引。
最后,由于TableScan輸出的數據量減少了,需要join的數據量也就減少了。
可以看到,謂詞下推是通過盡可能移動過濾表達式至靠近數據源的位置,來減少算子之間需要傳遞的數據量,進而優化查詢計劃。TSDBSQL現已支持timestamp,field以及tag上絕大部分的謂詞下推,并且實現了OrderBy,Limit下推等一系列優化規則;同時在一些聚合函數場景下,SQL支持通過分布式計算來優化查詢計劃的執行,這里暫不一一展開。
相信通過本文的介紹,大家已經對使用SQL引擎訪問百度智能云天工TSDB有了一定的了解。目前,百度智能云團隊仍在不斷完善TSDB上的SQL生態,比如通過JDBC/ODBC來連接TSDB等。未來,SQL生態將延伸到天工的其他產品上,比如物管理服務等,從而實現天工產品的多數據源一站式SQL查詢。