一篇運維老司機的大數據平臺監控寶典(1)-聯通大數據集群平臺監控體系進程詳解
如果你是一個經驗豐富的運維開發人員,那么你一定知道ganglia、nagios、zabbix、elasticsearch、grafana等組件。這些開源組件都有著深厚的發展背景及功能價值,但需要合理搭配選擇,如何配比資源從而達到性能的***,這里就體現了運維人的深厚功力。”
下文中,聯通大數據平臺維護團隊將對幾種常見監控組合進行介紹,并基于豐富的實戰經驗,對集群主機及其接口機監控進行系統性總結。
一、科普篇:幾種常見的監控工具選擇
目前常見的監控組合如下:
- Nagios+Ganglia
- Zabbix
- Telegraf or collect + influxdb or Prometheus or elasticsearch + Grafana +alertmanager
Nagios、Ganglia、Zabbix屬于較早期的開源監控工具,而grafana、prometheus則屬于后起之秀。下面,將分別介紹三種監控告警方式的背景及其優缺點:
1. Nagios+Ganglia
Nagios最早是在1999年以“NetSaint”發布,主要應用在Linux和Unix平臺環境下的監控告警,能夠監控網絡服務、主機資源,具備并行服務檢查機制。
其可自定義shell腳本進行告警,但隨著大數據平臺承載的服務、數據越來越多之后,nagios便逐漸不能滿足使用場景。例如:其沒有自動發現的功能,需要修改配置文件;只能在終端進行配置,不方便擴展,可讀性比較差;時間控制臺功能弱,插件易用性差;沒有歷史數據,只能實時報警,出錯后難以追查故障原因。
Ganglia是由UC Berkeley發起的一個開源監控項目,設計用于測量數以千計的節點。Ganglia的核心包含gmond、gmetad以及一個Web前端。主要用來監控系統性能,如:cpu 、mem、硬盤利用率,I/O負載、網絡流量情況等,通過曲線很容易見到每個節點的工作狀態,對合理調整、分配系統資源,提高系統整體性能起到重要作用。但隨著服務、業務的多樣化,ganglia覆蓋的監控面有限,且自定義配置監控比較麻煩,展示頁面查找主機繁瑣、展示圖像粗糙不精確是其主要缺點。
2. Zabbix
Zabbix是近年來興起的監控系統,易于入門,能實現基礎的監控,但是深層次需求需要非常熟悉Zabbix并進行大量的二次定制開發,難度較大;此外,系統級別報警設置相對比較多,如果不篩選的話報警郵件會很多;并且自定義的項目報警需要自己設置,過程比較繁瑣。
3. jmxtrans or Telegraf or collect + influxdb or Prometheus or elasticsearch + Grafana +alertmanager
這套監控系統的優勢在于數據采集、存儲、監控、展示、告警各取所長。性能、功能可擴展性強,且都有活躍的社區支持。缺點在于其功能是松耦合的,較為考驗使用者對于使用場景的判斷與運維功力。畢竟,對于運維體系來說,沒有“***”,只有“最適合”。
早期,聯通大數據平臺通過ganglia與nagios有效結合,發揮ganglia的監控優勢和nagios的告警優勢,做到平臺的各項指標監控。但隨著大數據業務的突增、平臺復雜程度的增加,nagios與ganglia對平臺的監控力度開始稍顯不足,并且開發成本過高。主要體現在配置繁瑣,不易上手;開發監控采集腳本過于零散,不好統一配置管理,并且nagios沒有歷史數據,只能實時報警,出錯后難以追查故障原因。
中期,我們在部分集群使用了zabbix,發現其對于集群層、服務層、角色層及角色實例監控項的多維度監控開發管理相對繁瑣,并且如果想要把平臺所有機器及業務的監控和告警集成到zabbix上,對于zabbix的性能將是很大的挑戰。
于是我們采用以Prometheus+ Grafana+ alertmanager為核心組件的監控告警方式,搭建開發以完成對現有大規模集群、強復雜業務的有效監控。采用PGA(Prometheus+ Grafana+ alertmanager)監控告警平臺的原因是其在數據采集選型、存儲工具選型、監控頁面配置、告警方式選擇及配置方面更加靈活,使用場景更加廣泛,且功能性能更加全面優秀。
二、實戰篇:平臺搭建、組件選型、監控配置的技巧
1. 采集、存儲工具的選型
(1) 采集器選擇
常見的采集器有collect、telegraf、jmxtrans(對于暴露jmx端口的服務進行監控)。筆者在經過對比之后選擇了telegraf,主要原因是其比較穩定,并且背后有InfluxData公司支持,社區活躍度不錯,插件版本更新周期也不會太長。Telegraf是一個用Go語言編寫的代理程序,可采集系統和服務的統計數據,并寫入InfluxDB、prometheus、es等數據庫。Telegraf具有內存占用小的特點,通過插件系統,開發人員可輕松添加支持其他服務的擴展。
(2) 數據庫選型
對于數據庫選擇,筆者***使用influxdb,過程中需要注意調整增加influxdb的并發能力,并且控制數據的存放周期。對于上千臺服務器的集群監控,如果存儲到influxdb里,通過grafana界面查詢時,會產生大量的線程去讀取influxdb數據,很可能會遇到influxdb讀寫數據大量超時。
遇到這種情況,可以先查看副本存儲策略:SHOW RETENTION POLICIES ON telegraf
再修改副本存儲的周期:
- ALTER RETENTION POLICY "autogen" ON "telegraf" DURATION 72h REPLICATION 1 SHARD DURATION 24h DEFAULT
需理解以下參數:
- duration:持續時間,0代表***制
- shardGroupDuration:shardGroup的存儲時間,shardGroup是InfluxDB的一個基本儲存結構,大于這個時間的數據在查詢效率上有所降低。
- replicaN:全稱是REPLICATION,副本個數
- default:是否是默認策略
但是,由于influxdb開源版對于分布式支持不穩定,單機版的influxdb服務器對于上千臺的服務器監控存在性能瓶頸(數據存儲使用的普通sata盤,非ssd)。筆者后來選擇使用es 或 promethaus聯邦來解決(關于es的相關權限控制、搭建、調優、監控維護,以及promethaus的相關講解將在后續文章具體闡述)。
2. Grafana展示技巧
Grafana是近年來比較受歡迎的一款監控配置展示工具,其優點在于能對接各種主流數據庫,并且能在官網及社區上下載精致的模板,通過導入json模板做到快速的展示數據。
(1) 主機監控項
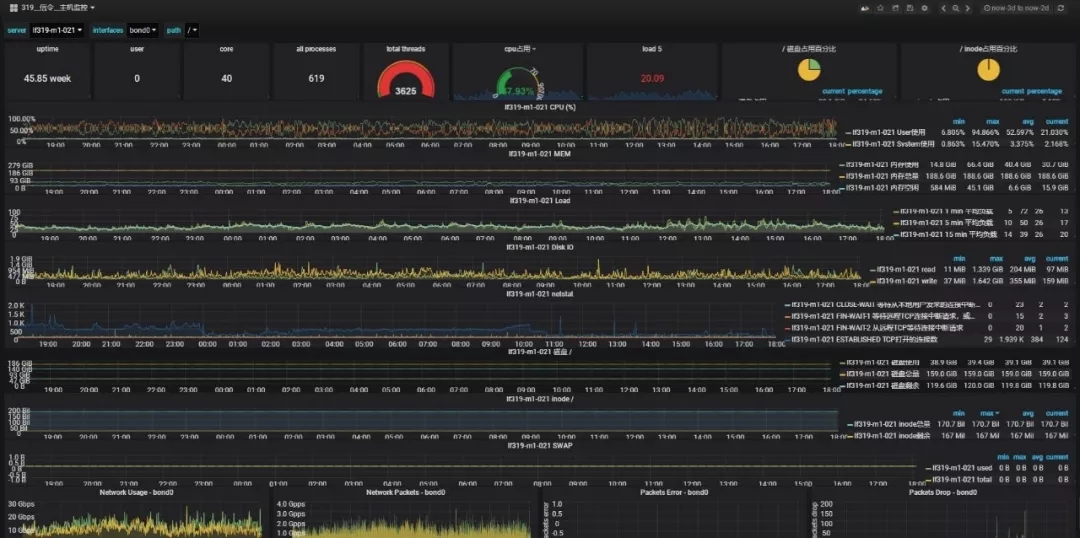
- 主機監控項概覽:內核、內存、負載、磁盤io、網絡、磁盤存儲、inode占用、進程數、線程數。
- 主機監控大屏:以一臺主機監控展示為樣例,大家先看下效果圖。
- 主機用途分類:聯通大數據公司作為專業的大數據服務運營商,后臺支持的主機數量規模龐大,各主機用途大不相同,那么就需要做好主機分類。用盒子的概念來說,機房是父類盒子,里面放置集群計算節點子盒子和接口機子盒子。集群主機、接口機分離,這樣當一臺主機故障時,方便更快的查找定位。
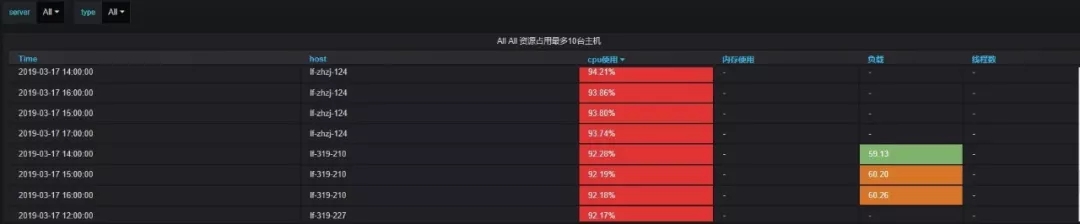
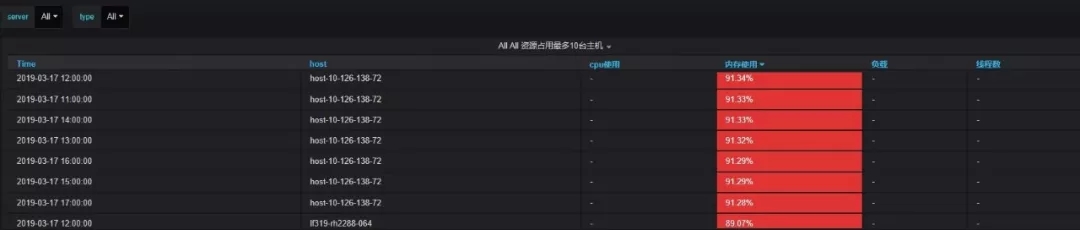
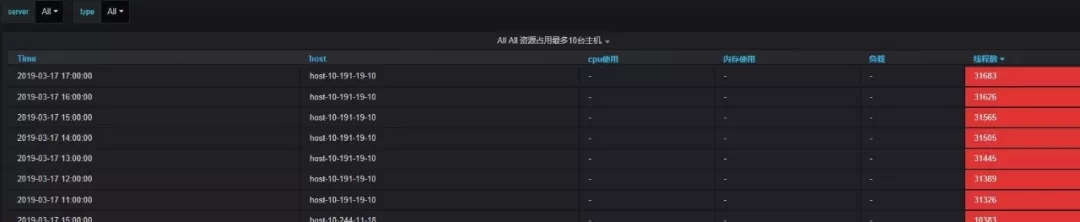
- 主機資源占用top10:主要從cpu占用、內存占用、負載、線程數多個維度統計同一主機群體(如:A機房接口機是一個主機群體,B機房計算節點是一個主機群體)占用資源最多的前十臺機器。

- 進程資源占用top10:通過主機監控大屏和主機資源占用top10定位故障主機的故障時間段和異常指標,只能初步的幫助運維人員排查機器故障的原因。例如,當機器負載過高時,在主機監控大屏中往往能看出主機的cpu使用,讀寫io、網絡io會發生急速增長,卻不能定位是哪個進程導致。當重啟故障主機之后,又無法排查歷史故障原因。因此對于主機層面監控,增加了進程資源占用top10,能獲取占用cpu,內存***的進程信息(進程開始運行時間、已運行時長、進程pid、cpu使用率、內存使用率等有用信息)。這樣,當主機因為跑了未經測試的程序,或者因運行程序過多,或程序線程并發數過多時,就能有效的通過歷史數據定位機器故障原因。

總結:主機層面可監控項還有很多,關鍵點在于對癥下藥,把排查故障的運維經驗轉化為采集數據的合理流程,再通過數據關聯來分析排查故障。
(2) 平臺監控項
平臺監控項種類繁多,有hdfs、yarn、zookeeper、kafka、storm、spark、hbase等平臺服務。每個服務下有多種角色類別,如hdfs服務中包括Namenode、Datenode、Failover Controller、JournalNode 。每個角色類別下又有多個實例。如此產生的監控指標實例達幾十萬個。目前聯通大數據使用的CDH版本大數據平臺,基礎監控指標全面多樣。根據現狀,平臺層面我們主要配置比較關鍵的一些監控項。
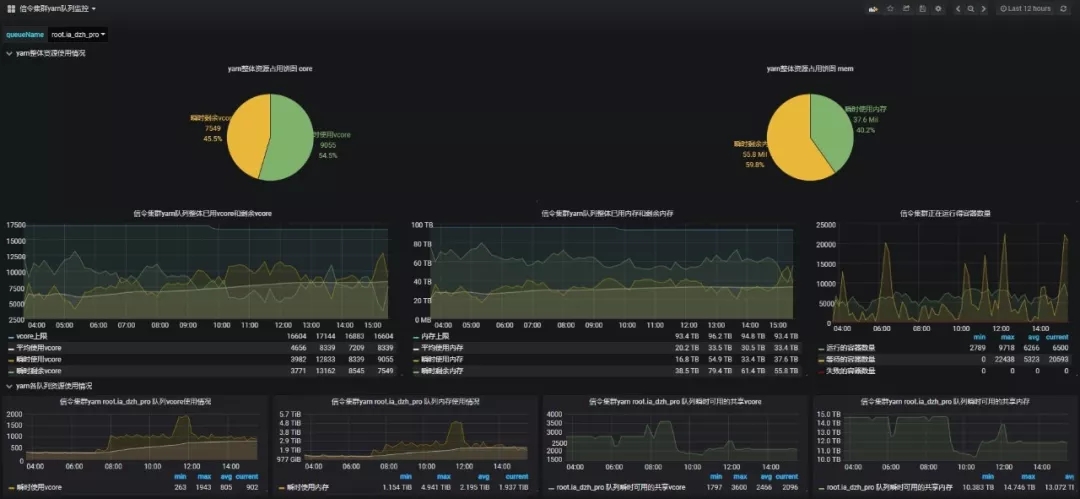
- 集群yarn隊列資源占用多維畫像:幫助平臺管理人員合理評估個隊列資源使用情況,快速做出適當調整。
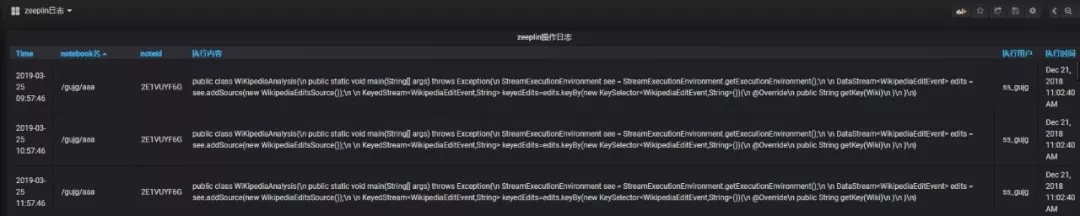
- zeeplin操作日志:zeepline并沒有相關的可視化審計日志,通過實時的獲取zeeplin操作日志來展現zeeplin操作,方便運維人員審計。
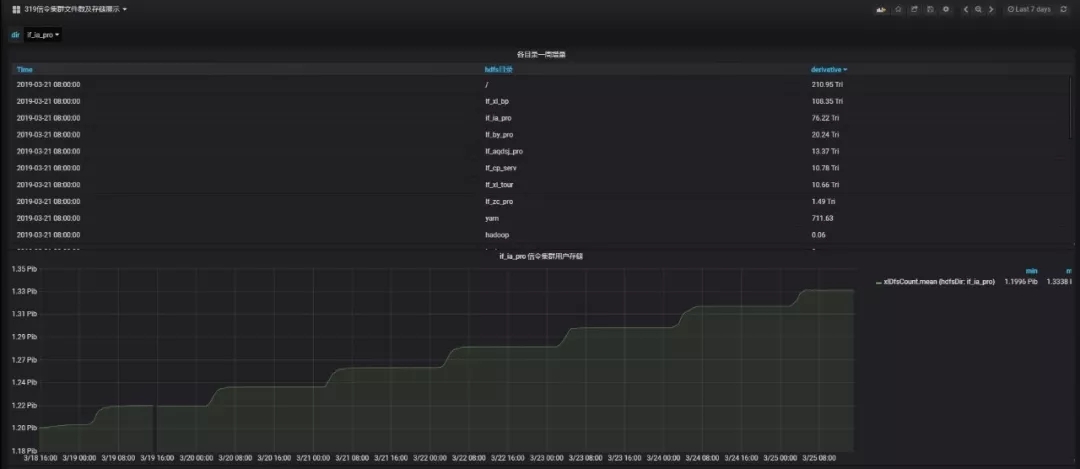
- hdfs各目錄文件數及存儲多維畫像:實時統計各業務用戶的數據目錄存儲,便于分析hdfs存儲增量過大的目錄。
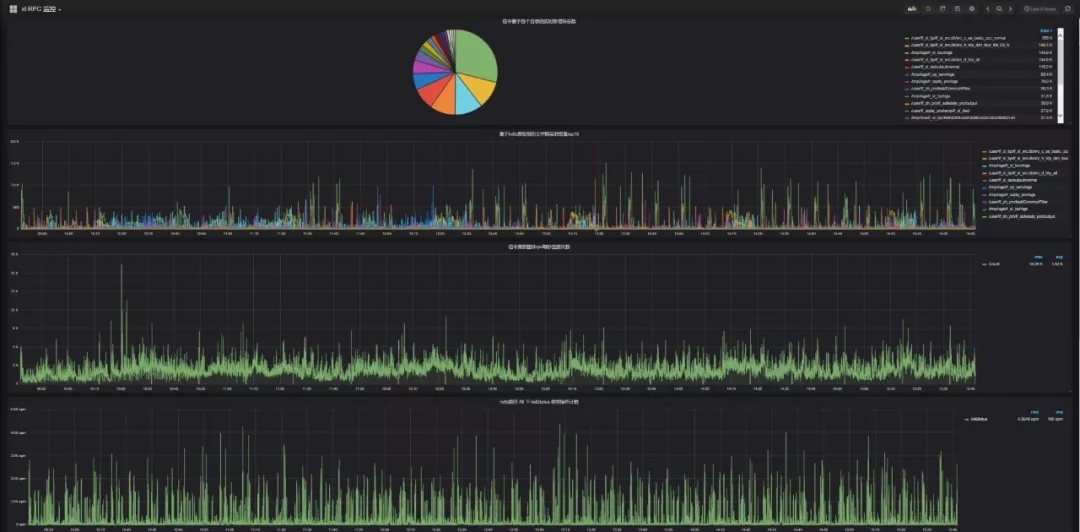
- 集群namenode RPC 實時多維畫像:當hadoop集群節點數達到千臺左右時,集群業務對于yarn隊列資源使用達到百分之八十以上,且集群寫多讀少,很容易造成namenode-rpc等待隊列深度過大,造成namenode-rpc延遲,這將會嚴重影響集群整體業務的運行。半小時能跑完的任務,可能會跑數個小時。根本原因還是集群承載業務數量過多,并且業務邏輯設計不合理,造成yarn任務執行過程頻繁操作hdfs文件系統,產生了大量的rpc操作。更底層的,每個dn節點的磁盤負載也會過高,造成數據讀寫io超時。
通過提取namenode日志、hdfs審計日志,多維度分析,可通過hdfs目錄和hdfs操作類型兩個方面確認rpc操作過多的業務。并且根據具體是哪種類型的操作過多,來分析業務邏輯是否合理來進行業務優化。例如有某大數據業務的邏輯是每秒往hdfs目錄寫入上千個文件,并且每秒遍歷下hdfs目錄。但觸發加工是十分鐘觸發一次,因此該業務產生了大量的rpc操作,嚴重影響到集群性能,后調優至5分鐘遍歷次hdfs目錄,集群性能得到極大優化。
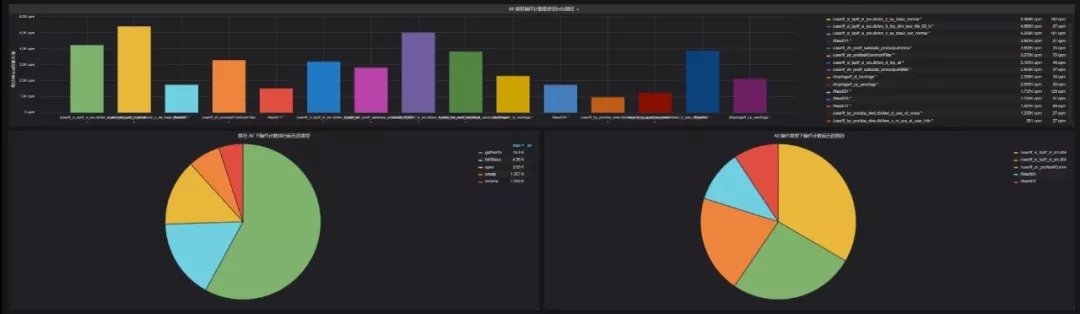
(3) 日常生產監控項
生產報表:由于聯通大數據平臺承載業務體量很大,通過后臺查詢繁瑣,而通過可視化展示能方便生產運維人員快速了解日生產情況,定位生產延遲原因。
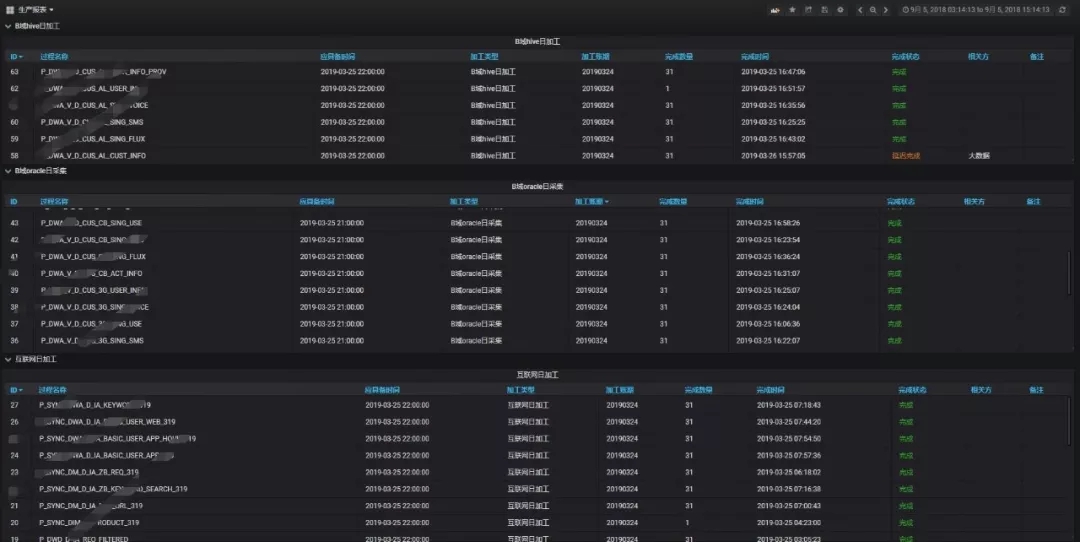
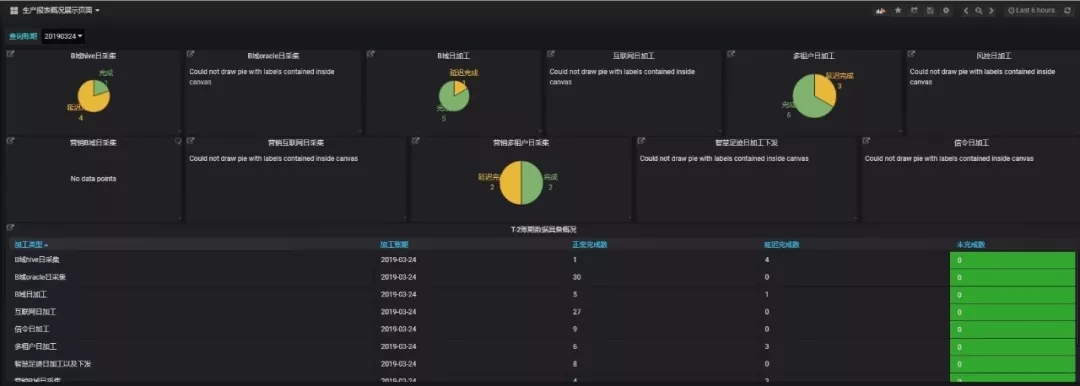
結語:關于平臺監控的內容在本文中就先介紹到這里,在下一篇中,筆者將針對平臺告警做出經驗分享,介紹如何建立統一采集模板、告警各集群的全量監控指標、進行分組告警并自動化恢復等內容。
【本文是51CTO專欄機構中國聯通大數據的原創文章,微信公眾號“中國聯通大數據( id: unibigdata)”】