基于梯度擾動探索對抗攻擊與對抗樣本
概述
近兩年研究人員通過對AI模型的安全性分析發現,機器學習模型和神經網絡模型都容易受到惡意用戶的對抗攻擊,攻擊者可以通過生成對抗樣本的方式攻擊AI模型并誤導AI模型做出錯誤的判斷,這一安全問題備受關注。
目前已有的機器學習模型和神經網絡模型都是通過提取數據特征,構建數學判別公式然后根據數學模型進行學習。提取數據特征的過程中容易提取到錯誤特征、而且判別公式也可能出現與真實決策面分布不同的問題,因此攻擊者可以利用AI模型的弱點,生成欺騙模型的對抗樣本。例如在圖像識別領域,可以通過在正常圖片上加入一個微小的噪聲從而使圖像識別分類器無法正常識別圖像,導致錯誤分類的效果。這一問題存在嚴重的安全隱患。
對抗攻擊往往是指攻擊者利用特定的模型算法對AI模型進行攻擊,其不僅包括攻擊者熟悉AI模型的條件下,對實際輸入進行修改從而誤導AI模型的判別結果,而且包括攻擊者在不了解AI模型的結構和參數的情況下,借助機器學習模型之間算法遷移的特性對AI模型進行攻擊。
對抗樣本通常是指經過特定的算法處理之后,模型的輸入發生了改變從而導致模型錯誤分類。假設輸入的樣本是一個自然的干凈樣本。那么經過攻擊者精心處理之后的樣本則稱為對抗樣本,其目的是使該樣本誤導模型做出判斷。
對抗攻擊
對抗攻擊可以從幾個維度進行分類。例如可以通過攻擊者對AI模型的了解程度進行分類。
- 白盒攻擊。攻擊者擁有模型的全部知識,包括模型的類型,模型結構,所有參數和可訓練權重的值。
- 有探針的黑盒攻擊。攻擊者只了解模型的部分知識,可以探測或者查詢模型,比如使用一些輸入,觀察模型的輸出結果。這種場景有很多的變種,比如攻擊者知道模型結構,但是不知道參數的值,或者攻擊者甚至連模型架構都不知道;攻擊者可能能夠觀測到模型輸出的每個類別的概率,或者攻擊者只能夠看到模型輸出最可能的類別名稱。
- 無探針的黑盒攻擊。在沒有探針的黑盒攻擊中,攻擊者只擁有關于模型有限的信息或者根本沒有信息,同時不允許使用探測或者查詢的方法來構建對抗樣本。在這種情況下,攻擊者必須構建出能夠欺騙大多數機器學習模型的對抗樣本。
此外還可以通過攻擊者攻擊的目標將對抗攻擊分類。
- 無目標攻擊(non-targeted attack)。在這種情況下,攻擊者的目標僅僅是使得分類器給出錯誤預測,具體是哪種類別產生錯誤并不重要。
- 有目標攻擊(targeted attack)。在這種情況下,攻擊者想要將預測結果改變為某些指定的目標類別中。
1. 白盒攻擊
傳統的白盒攻擊是指在我們已知神經網絡模型的網絡結構以及模型參數的情況下,我們針對該神經網絡生成對抗樣本實現誤導該模型的效果。攻擊者能夠獲取機器學習所使用的算法以及算法所使用的參數。攻擊者在產生對抗性攻擊數據的過程中能夠和機器學習的系統有所交互。這種“透明”的攻擊方式稱之為白盒攻擊,通常是利用模型的梯度、logits輸出等模型本身的知識來設計對抗性擾動生成對抗樣本對該模型進行攻擊。白盒攻擊流程示意圖如下所示。
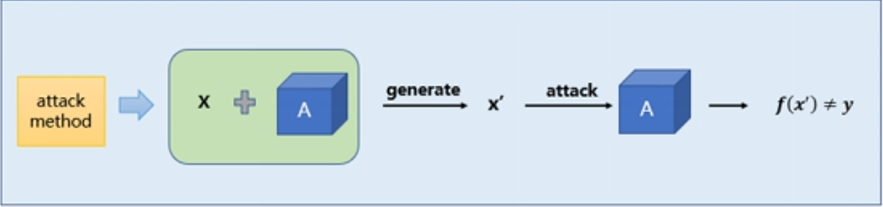
白盒攻擊示意圖
根據對抗樣本生成原理的不同,白盒攻擊通常可以分為三類:基于梯度(gradient-based)的攻擊、基于優化(optimization-based)的攻擊、基于模型(model-based)的攻擊。根據生成對抗樣本是否對類別有針對性分為有目標攻擊和無目標攻擊。
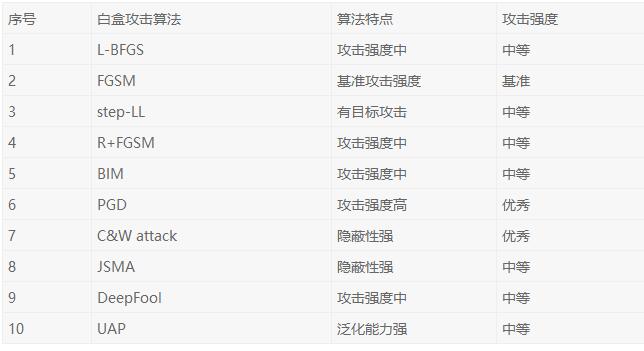
下表中總結了當前常用的十種白盒攻擊算法的特點,以作為白盒攻擊算法的比較參考。
常用的十種白盒攻擊算法總結
2. FGSM白盒攻擊算法
FGSM(Fast gradient sign method)是一種常見的白盒攻擊算法。該攻擊方法的思路非常簡單,主要是利用模型損失函數對輸入求梯度得到對抗性擾動,然后將對抗性擾動添加到原始樣本中生成對抗樣本。通過在原始樣本的鄰域中線性化損失函數,并通過如下閉合形式的方程找到精確的線性化函數的最大值。

FGSM是通過計算單步梯度快速生成對抗樣本。基于梯度的攻擊方法的原理在于絕大多數神經網絡模型中都是通過梯度下降算法最小化損失函數來進行訓練的,因此利用損失函數對輸入求梯度,沿著梯度上升方向是使樣本朝著損失增大的方向移動,就有可能導致預測輸出改變。
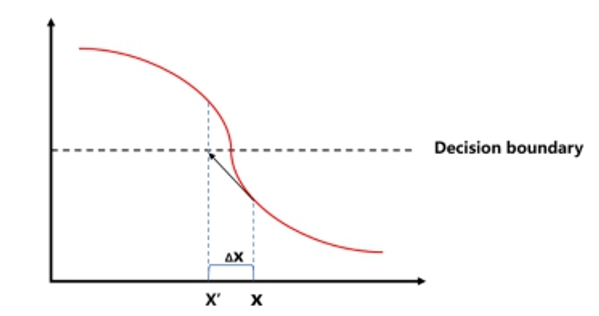
FGSM原理示意圖
FGSM方法優點是計算成本低、生成速度快,缺點是攻擊能力較弱,適用于對攻擊效率有較高要求的應用場景。
3. C&W白盒攻擊算法
C&W攻擊算法是一種基于迭代優化的低擾動對抗樣本生成算法。該算法設計了一個損失函數,它在對抗樣本中有較小的值,但在原始樣本中有較大的值,因此通過最小化該損失函數即可搜尋到對抗樣本。
C&W算法主要對多步迭代攻擊中的優化函數進行重新設計,采用以下目標函數:

上式中第一項ξ 是一個需要經驗確定的權重參數,用來平衡攻擊的隱蔽性與攻擊強度。第一項的最小化意味著需要盡量使樣本在模型中的輸出不為其對應標簽。第二項中的τ 初始化為最大允許的擾動幅度,通常為數據最大變化量的無窮范數的6.25%,每當第二項優化到0時,τ會以0.9x的速度遞減。如下圖所示逐步更新第二項的意義在于逐漸限制最大允許擾動幅度,從而增強對抗攻擊的隱蔽性。
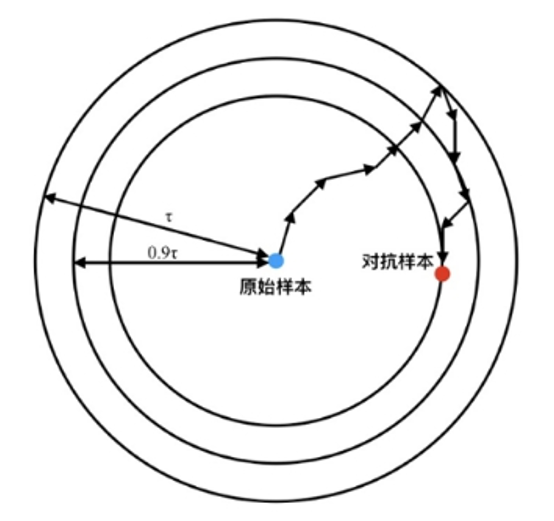
綜上所述, C&W算法在繼承簡單多步迭代攻擊的基礎之上,改進其目標優化函數,使其逐步收緊對擾動幅度的限制,從而達到減小對抗樣本擾動幅度的要求,進而使對抗樣本的隱蔽性提升。
4. 基于集成的黑盒攻擊算法
在實際的應用場景中,攻擊者可能無法獲取到AI模型的一些詳細信息,例如模型的參數和神經網絡的結構,但是攻擊者可以利用神經網絡模型之間具有遷移特性的特點,采用黑盒攻擊算法對目標進行攻擊。
基于logits集成的黑盒攻擊算法是利用集成學習思路的一種黑盒攻擊方法。基于logits集成是通過集成多個模型的logits輸出,以生成能夠使得多個模型分類錯誤的對抗樣本為目標進行訓練,從而使得對抗樣本能夠對另外的零知識的模型具有黑盒攻擊能力。常用的對抗攻擊方法是利用單個模型的梯度進行快速生成或者利用logits輸出進行優化來找到對抗樣本。而基于logits集成是利用多個模型的logits輸出,以得到對所有模型都具備攻擊能力的對抗樣本為目的,即這個對抗樣本是所有模型的對抗樣本,實現上通過攻擊多個模型的集成模型來實現。另外還可以考慮給各個模型賦上權重,權衡不同模型之間的相對重要性,以適用于不同的實際應用場景。集成后的logits表達式如下式所示。

其中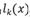 表示第k個模型的logits輸出,
表示第k個模型的logits輸出,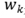 表示第k個模型的logits的權重。模型的損失函數如下:
表示第k個模型的logits的權重。模型的損失函數如下:
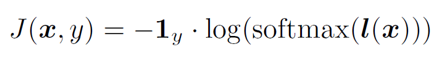
基于logits集成的思想借鑒了集成學習的思想,從原來的單模型對抗樣本目標,升級為多模型集成對抗樣本目標。基于logits線性加權集成的結構如下圖所示。
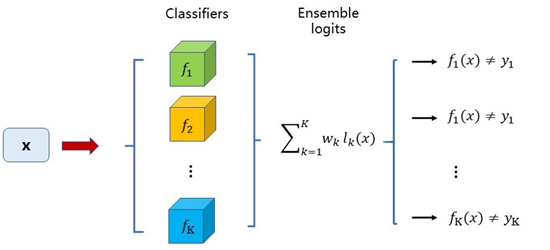
這種方法的優點在于,首先在大規模數據集上具有好的遷移能力;其次既可以遷移無目標攻擊,也可以對有目標攻擊進行遷移,即可以帶著目標標簽一起遷移。此外,理論表明,基于logits集成的攻擊能力明顯優于預測集成和損失函數集成的攻擊能力。
對抗樣本
通過上面介紹了對抗攻擊的幾種算法,我們可以借助這些對抗攻擊算法來生成對抗樣本。目前對抗樣本應用最多的領域是圖像識別方向,攻擊者可以利用攻擊算法對圖像中的像素點進行修改,改變了輸入圖像之后可以誤導AI模型識別系統做出錯誤的判斷。
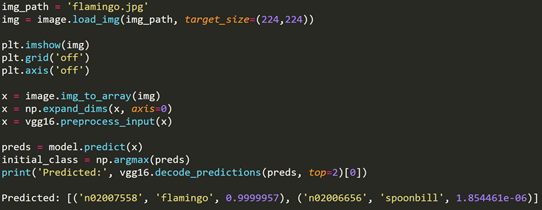
我們利用FGSM算法對VGG模型進行攻擊,生成對抗樣本的關鍵過程如下。
首先我們載入一張火烈鳥的圖片,并利用VGG模型進行預測。結果發現VGG模型可以正常識別火烈鳥的圖片。

當我們在火烈鳥圖片的梯度上升方向上增加一個噪聲信號之后,迭代增加400次并限制噪聲信號的幅度范圍。再次用VGG模型識別圖片是發現模型會將火烈鳥識別成鶴。根據FGSM算法的原理對火烈鳥圖片進行修改,在原始圖像上疊加的噪聲就是在限制幅度范圍內對圖像的梯度進行上升計算。
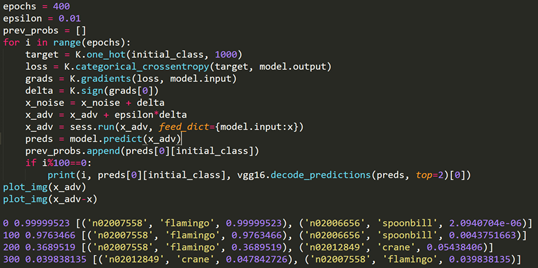

注意到疊加了噪聲信號的對抗樣本和原始樣本實際上肉看觀察不到區別,利用程序繪制出噪聲信號也會發現噪聲幅度很小幾乎可以忽略。但是對于VGG模型而言是別的結果卻是完全不同的。隨著梯度上升迭代次數的增加,噪聲信號越來越大、生成的對抗樣本迷惑性越來越強,最終導致VGG模型受到了FGSM算法的攻擊。
總結
經過對對抗攻擊的調研發現,對抗攻擊受到越來越多的研究人員和大眾的關注。雖然已經有不少研究提出了許多新穎的攻擊算法用于產生對抗樣本,但是與攻擊對應的防御問題一直沒有得到很好地解決。
目前的對抗攻擊防御解決方法主要包括對抗學習過程加入對抗樣本進行訓練,以及引入膠囊網絡等集成的方式對攻擊方法進行防御。然而這些方法都還不成熟,而且沒有形成完整的體系,至于防御效果也不明顯。可以說目前還沒有一個完善的抵御對抗攻擊的模型或者方法產生。因此無論是對抗攻擊領域還是防御方法都還存在著很大的發展空間。
【本文是51CTO專欄作者“綠盟科技博客”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】