













用Select * 進行SQL查詢的七宗罪
譯文【51CTO.com快譯】如今,網上許多文章都已明確地指出:使用“SELECT * ”作為SQL查詢方式是一種極其危險的代碼書寫習慣。開發人員應該盡量在自己的程序中避免出現此類查詢,取而代之的應該是明確地指定要查詢的列名。不過,大家可能只是“知其然,而不知其所以然”。在本文中,讓我向各位初級開發人員詳細解釋,此類SQL查詢***實踐背后的具體原因。
首先,我們經常面對的客觀情況是:在Oracle數據庫中,許多SQL開發人員都是從接觸“SELECT * from EMP”(EMP為表的名稱)之類的查詢語句,開始學習SQL語言的。因此,除非能夠給出充分的理由,否則我們很難撼動他們使用此類便捷查詢語句的習慣。
下面,我將根據自己在應用編程中的實際經驗,向大家證明使用Select * from table進行SQL查詢的“七宗罪”。

1. 不必要的I/O(輸入/輸出)
通過使用SELECT * ,您雖然可以獲得一些完全可以被忽略的返回數據,但是該獲取過程可并不是免費的。那些本來可能只需要從索引頁面中讀取的數據檢索,如今您卻不得不從各個頁面中以全量的方式讀取出來。顯然,此舉會導致數據庫端白白浪費各種有限的I/O周期。
另外,該方式也可能會拖慢您的查詢速度。如果您好奇并想探究數據庫后臺的查詢執行過程,以及查詢引擎是如何順次處理查詢語句的話,我建議您參考:Markus Winand的《SQL Performance Explained》(請參見http://www.amazon.com/Performance-Explained-Everything-Developers-about/dp/3950307826/?tag=javamysqlanta-20),以及Udemy的《The Complete SQL BootCamp》(請參見https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fthe-complete-sql-bootcamp%2F)課程。
2. 增加的網絡流量
SELECT * 雖然能返回比用戶預期更多的數據,但是相應地,這些數據的傳輸勢必會消耗更多的網絡帶寬資源。與此同時,網絡帶寬的增加也就意味著:那些真正為用戶所需要的數據將會花費更長的時間,才能被傳送到客戶端的應用程序上。例如:如果您可能是在本地計算機上運行由SQL Server Management Studio(請詳見http://bit.ly/2CXPyBB)、Toad或SQL Developer for Oracle(請參見http://bit.ly/2xQzAsd)提供的查詢編輯器,或是在某個Java應用服務器上運行此類查詢,這都會耗費您不少的網絡流量與資源。
3.更多的應用內存
隨著業務數據的猛增,您的應用程序可能需要使用更多的內存,來保存由此類查詢方式所產生的,可能來自Microsoft SQL Server(請參見http://www.java67.com/2018/01/top-4-free-microsoft-sql-server-books.html)的各種無用數據。
4.產生依賴于列排序的結果集(ResultSet)
當您在應用程序中使用SELECT * 查詢后,您會得到一些依賴于數據表的列排序的結果集。因此,一旦有新的列被添加,或者是列排序被修改了,它們都會對查詢的結果集產生不同的影響。
5.新增列會破壞既有的視圖
如果您在視圖(請參見http://www.java67.com/2012/11/what-is-difference-between-view-vs-materialized-view-database-sql.html)中使用了SELECT * ,那么一旦有新的列被添加,同時舊的列從表中被去除時,您所構建的原有視圖就會被破壞,進而返回給用戶錯誤的結果。
為避免此類情況的發生,您應該始終在SQL Server數據庫(請參見http://javarevisited.blogspot.sg/2013/11/difference-between-char-varchar-nchar-nvarchar-sql-database.html#axzz5CSnhvSWV)里,對于視圖的定義中,包含WITH SCHEMABINDING選項。
6. 連接查詢中的沖突
如果您在連接查詢(JOIN Query,請參見https://javarevisited.blogspot.com/2012/11/how-to-join-three-tables-in-sql-query-mysql-sqlserver.html#axzz5az3hfsHW)中使用了SELECT * ,那么一旦在多個表中出現了具有相同名稱的列,例如status、active和name等,就可能會產生各種并發式的沖突。
雖說在直接查詢中,出現問題的可能性不大,但是當您試著按其中的某一列進行排序、或是在公用表表達式(Common Table Expression,CTE)、以及派生表(derived table)中使用查詢的時候,您就需要進行各種進一步的調整,以避免產生沖突了。
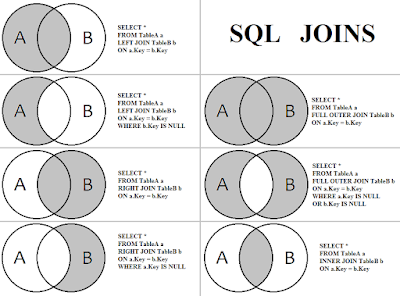
7.在表間復制數據時的風險
您可能會經常使用“SELECT * into INSERT . . .”之類的語句,以實現將某些數據從一張表復制到另一張表。如果在兩張表中,各個列的排列順序略有不同,那么就可能會出現將不正確的數據復制到錯誤列中的情況。
一些程序員可能會認為:由于查詢解析器必須額外地驗證某些靜態值,因此導致了在EXISTS語句(譯者注:即檢驗查詢的結果是否返回數據,請參見https://javarevisited.blogspot.com/2016/01/sql-exists-example-customers-who-never-ordered.html)中使用SELECT * 要比SELECT 1的速度更快一些。此觀點擱在過去可能會有幾分道理。但是現在,各種數據庫解析器已經發展得相當智能了,它們判斷EXISTS語句的效率,與產生SELECT結果列表(請參見https://javarevisited.blogspot.com/2016/04/how-to-convert-result-of-select-command-to-comma-separated-String-in-SQL-Server.html)將毫無關系。
結論
通過上述七點分析,相信您應該明白了為什么不能在SQL查詢中濫用SELECT * 的原因吧?可見,您應該盡可能地在查詢中,使用顯式的列名稱,而不是那些星號通配符。此舉不但能夠提高您的代碼效率,也可以使您的程序更加清晰。與此同時,該方法還能夠幫助您創建各種具有可維護性的代碼。而且,如果后期在表中有新的一列被添加的話,您的代碼也不會因此受到影響,您仍然會擁有來自原始數據表的參考視圖。
原文標題:7 Reasons Why Using SELECT * FROM TABLE in SQL Query Is a Bad Idea,作者:Javin Paul
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】














