超高性能管線式HTTP請求(實踐·原理·實現)
這里的高性能指的就是網卡有多快請求發送就能有多快,基本上一般的服務器在一臺客戶端的壓力下就會出現明顯延時。
該篇實際是介紹pipe管線的原理,下面主要通過其高性能的測試實踐,解析背后數據流量及原理。***附帶一個簡單的實現。
實踐
先直接看對比測試方法:
測試內容單一客戶的使用盡可能快的方式向服務器發送一定量(10000條)請求,并接收返回數據。
對于單一客戶端對服務器進行http請求,一般我們的方式:
1:單進程或線程輪詢請求(這個效能自然很低,原因會講到,也不用測試)
2:多條線程提前準備數據等待信號(對客戶端性能要求較高)
3:提前準備一組線程同時輪詢操作
4:使用系統/平臺自帶異步發送機制(實際就是平臺線程池的方式,發送與接收使用從線程池中的不同線程)
對于測試方案1,及方案2測試中性能較低沒有可比性,后面測試不會展示其結果。
以下展示后面2種測試方法及當前要說的管線式的方式:
- 先講管線式(pipe)測試方案(原理在后面會講到),測試中使用100條管線(管道),實際上更少甚至一條管線也是能達到近似的性能,不過多數服務器nginx限制一條管可以持續發送request的數量(大部分是100也有部分會是200或是更高),每條管線發送100個請求。
- 然后是線程組的方式準備100條線程(100條線程并不是很多不會對系統本身有明顯影響),每條線程輪詢發送100個request。
- 異步方式的方式,10000全部提交發送線程,由線程池控制接收。
測試環境:普通家用PC,i5 4核,12G ,100Mb電信帶寬。
測試數據:
GET http://www.baidu.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Host: www.baidu.com
Connection: Keep-Alive
這里就是測試最常用的baidu,如果測試接口性能不佳,大部分請求會在應用服務器排隊,難以直觀提現pipe的優勢(其實就是還沒有用到pipe的能力,服務器就先阻塞了)。
下文中所有關于pipe的測試都是使用PipeHttpRuner (http://www.cnblogs.com/lulianqi/p/8167843.html 為該測試工具的下載地址,使用方法及介紹)。
先直接看管道式的表現:(截圖全部為windows自帶任務管理器及資源管理器)
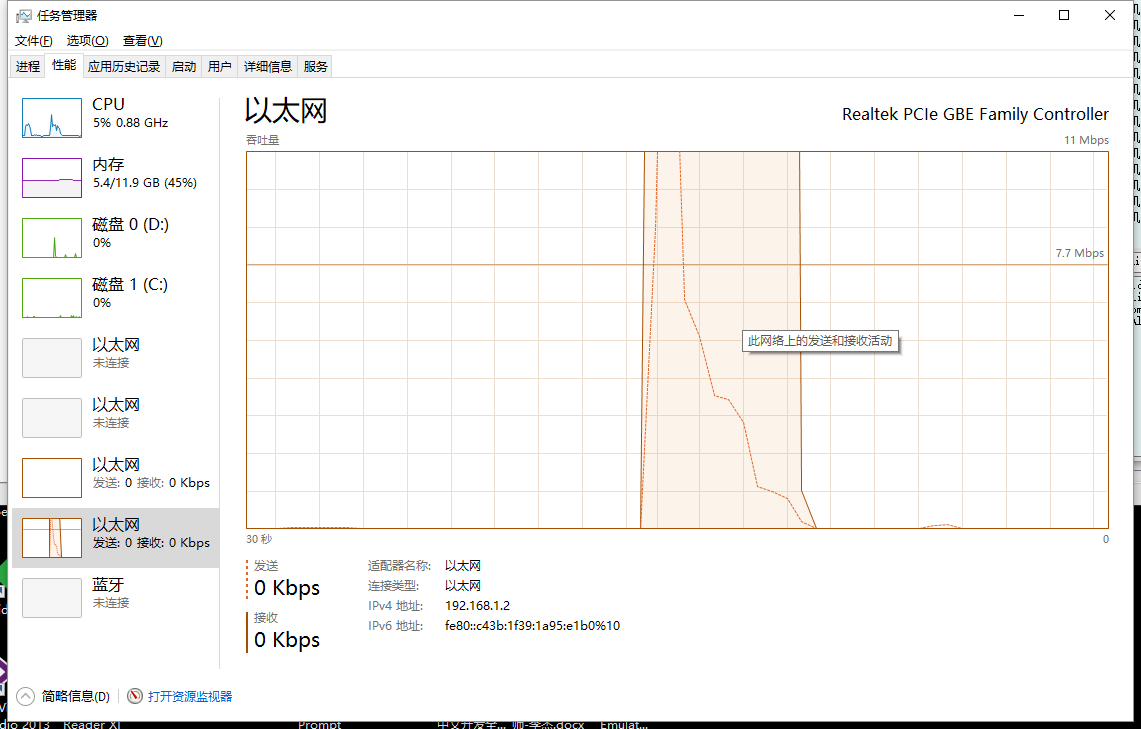
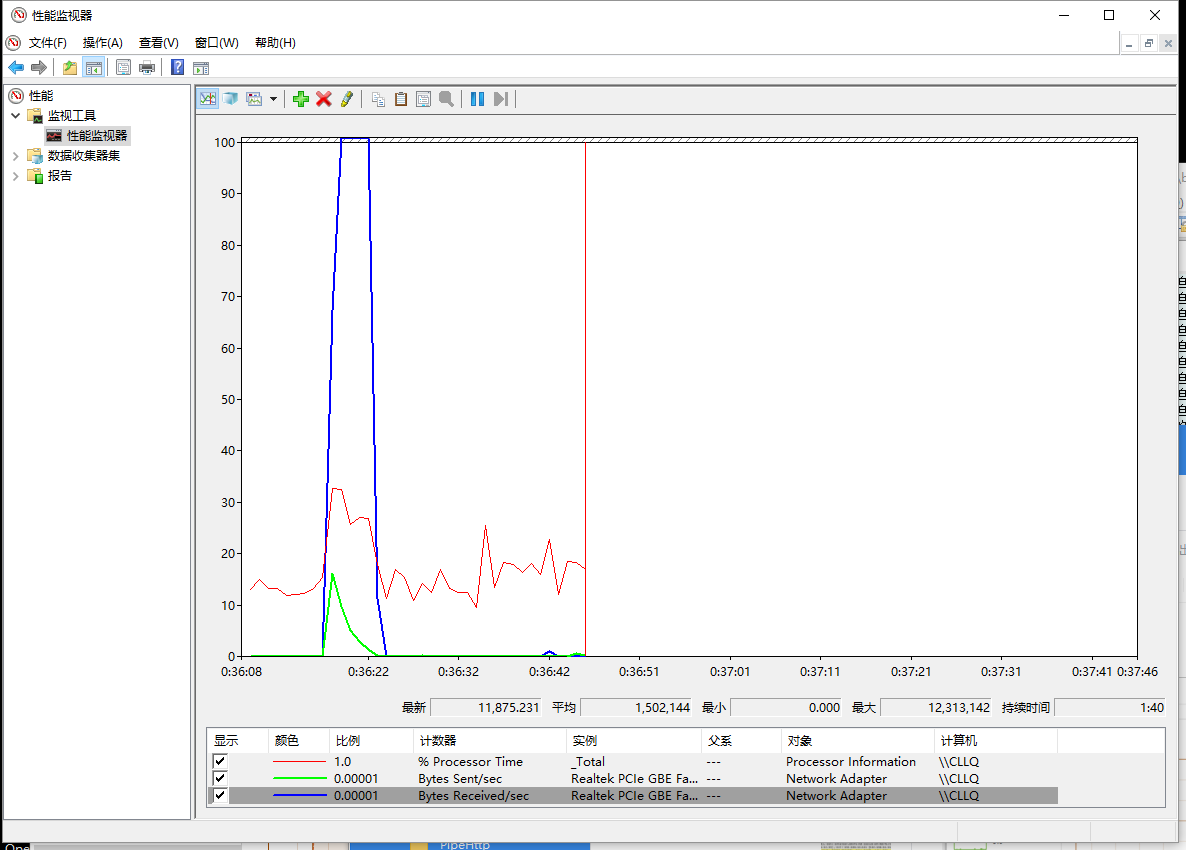
先解釋下截圖含義,后面的截圖也都是同樣的含義:
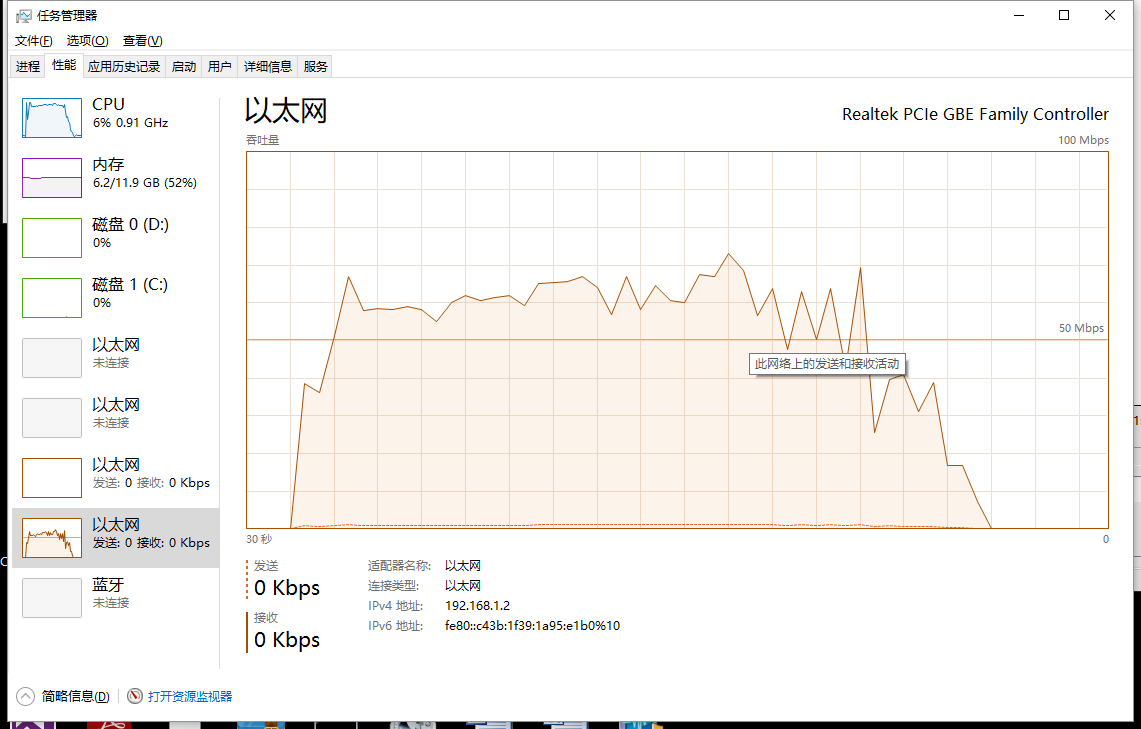
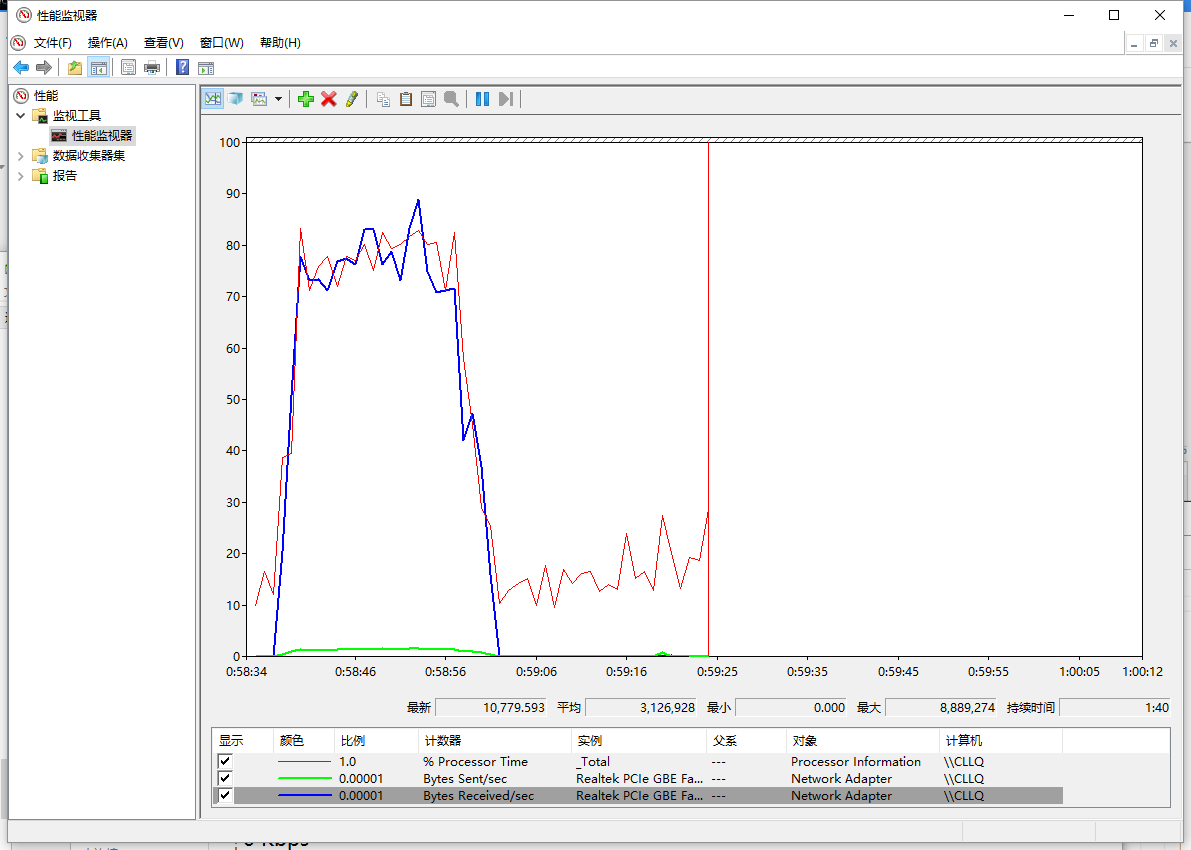
***副為任務管理器的截圖實線為接收數據,虛線為發送數據,取樣0.5s,每一個正方形的刻度為1.5s(因為任務管理器繪圖策略速率上升太快過高的沒有辦法顯示,不過還是可以看到時間線)。
第二副為資源管理器,添加了3個采樣器,紅色為CPU占用率,藍色為網絡接收速率,綠色為網絡發送速率。
測試中 一次原始請求大概130字節,加上tcp,ip包頭,10000條大概也只有1.5Mb(包頭不會太多因為管道式請求里會有多個請求放到一個包里的情況,不過大部分服務器無法有這么快的響應速度會有大量重傳的情況,實際上傳流量可能遠大于理論值)。
一次的回包大概在60Mb左右(因為會有部分連接中途中斷所以不一定每次測試都會有10000個完整回復)。
可以看到使用pipe形式性能表現非常突出,總體完成測試僅僅使用了5s左右。
發送本身壓力比較小,可以看到0.5秒即到達峰值,其實這個時候基本10000條request已經發送出去了,后面的流量主要來自于服務器端緩存等待(TCP window Full)來不及處理而照成是重傳,后面會講到。
再來看看response的接收,基本上也僅僅使用了0.5s即達到了接收峰值,使用大概5s 即完成了全部接收,因為測試中cpu占用上升并不明顯,而對于response的接收基本上是從tcp緩存區讀出后直接就存在了內容里,也沒有涉及磁盤操作(所以基本上可以說對于pipe這個測試并沒有發揮出其全部性能,瓶頸主要在網絡帶寬上)。
再來看下線程組的方式(100條線程每條100次):
下面是異步接收的方式:
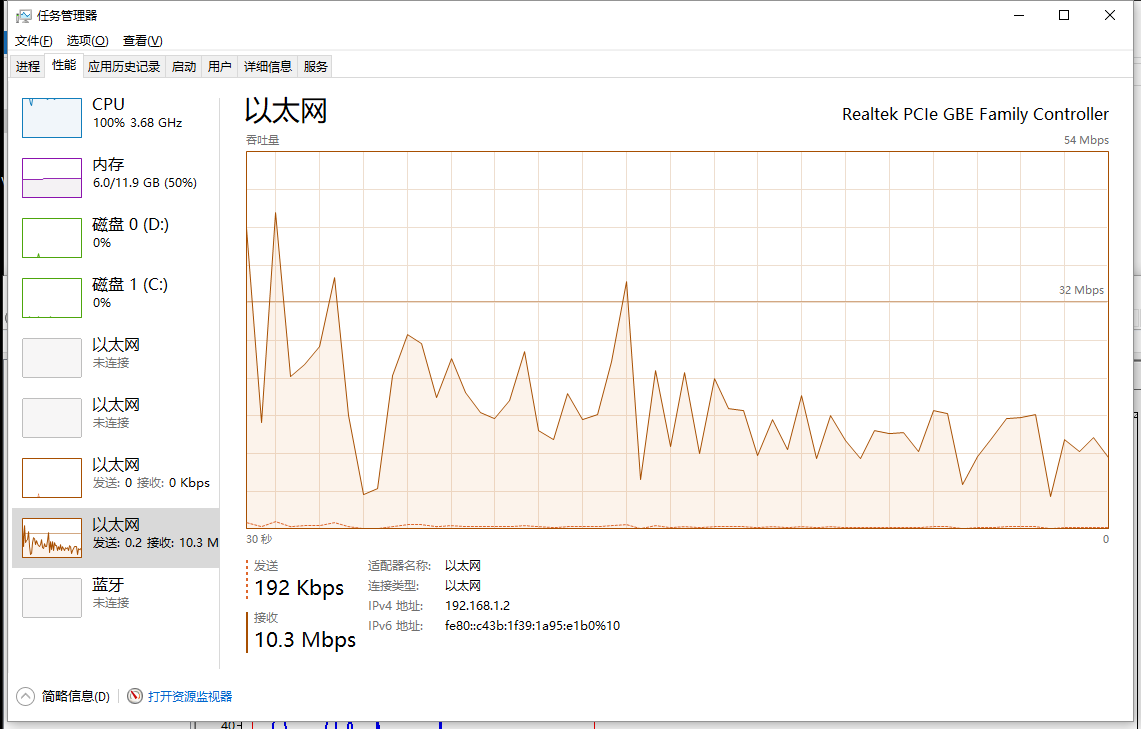
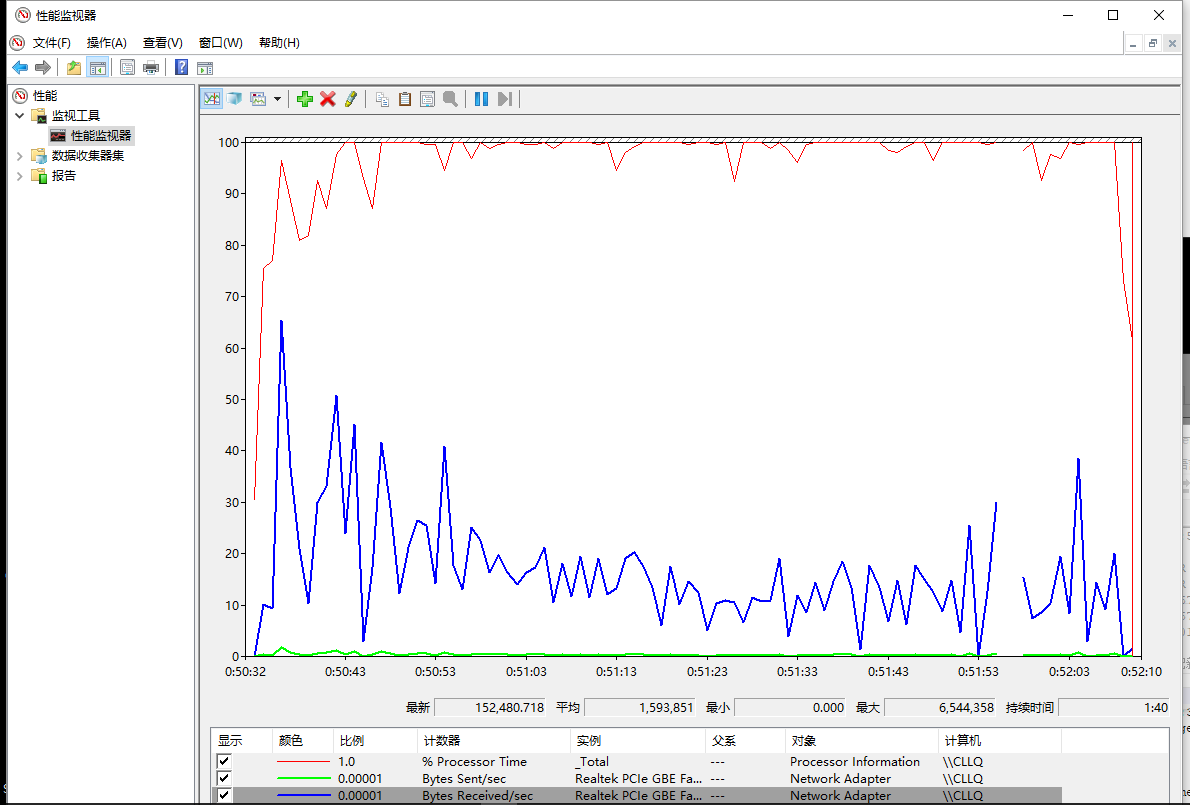
很明顯的差距,對于線程組的形式大概使用了25秒,而異步接收使用了超過1分鐘的時間(異步接收的模式是平臺推薦的發送模式,正常應用情況下性能是十分優越的,而對于過高的壓力不如自定義的線程組,主要還是因為其使用了默認的線程池,而默認線程池不可能在短時間開100條線程出來用來接收數據,所以大量的回復對線程池里的線程就會有大量的切換,通過設置默認線程池數量可以提高測試中的性能)。更為重要的是這2者中的無論哪一種方式在測試中,cpu的占用都幾乎是滿的(即是說為了完成測試計算機已經滿負荷工作了,很難再有提高)。
后面其實還針對jd,toabao,youku,包括公司自己的服務器進行過測試,測試結果都是類似的,只要服務器不出問題基本上都有超過10倍的差距(如果客戶端帶寬足夠這個差距會更大)。
下面我們再對接口形式的HTTP進行簡單一次測試:
這里選用網易電商的接口(電商的接口一般可承受的壓力比較大,這里前面已經確認測試不會對其正常使用造成實質的影響)。
http://you.163.com/xhr/globalinfo/queryTop.json?__timestamp=1514784144074 (這里是一個獲取商品列表的接口)。
測試數據設置如下:
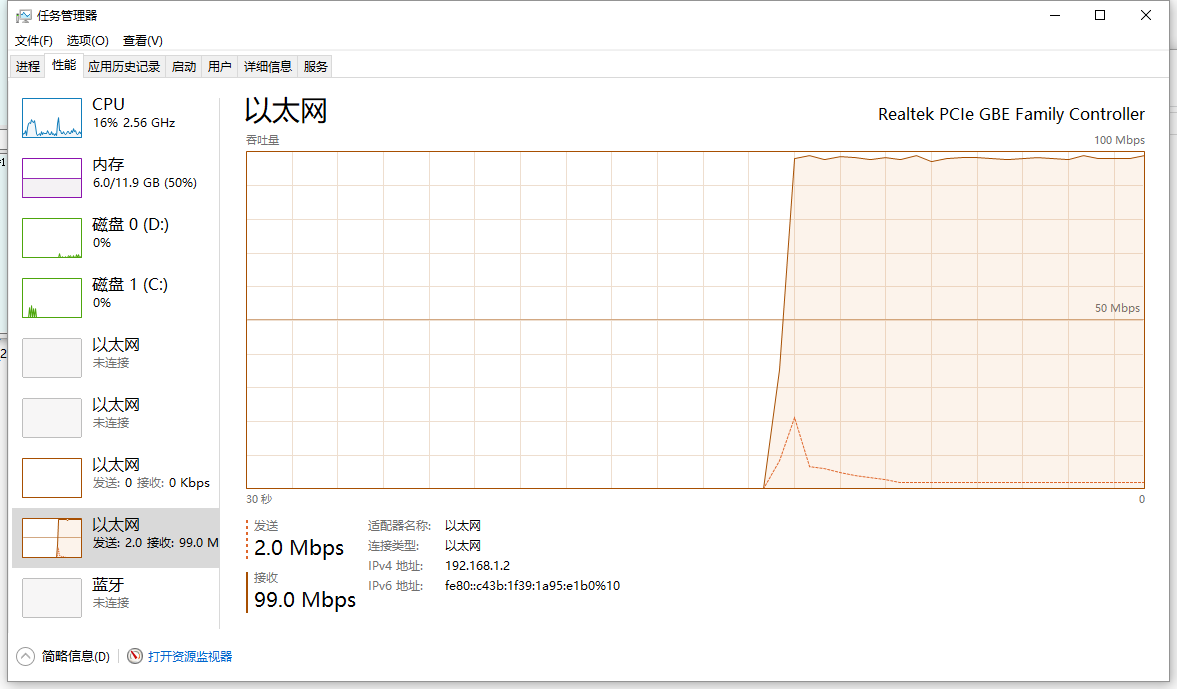
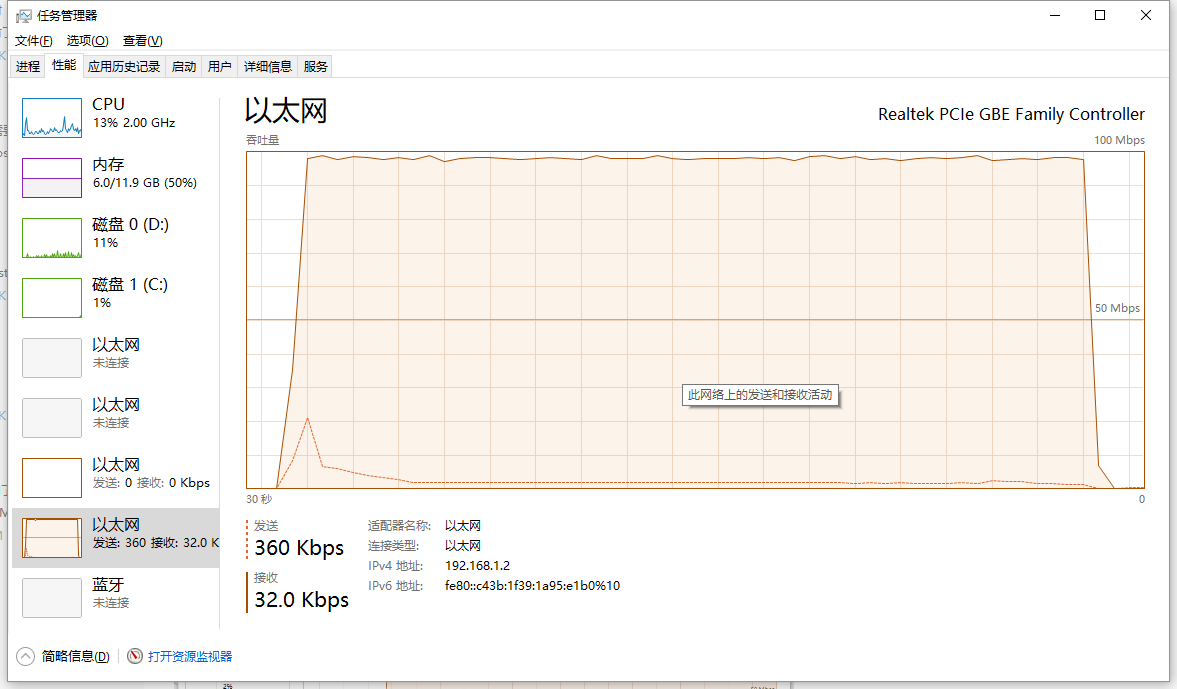

請求量還是10000條接收的response數據大概有326Mb 30s之內完成。基本上是網絡的極限,此時cpu也基本無然后壓力(100條管線,每條100個請求)。
這里其實請求是帶時間戳的,因為測試時使用的是同一個時間戳,所以實際對應用服務器的影響不大,真實測試時可以為每條請求設置不同時間戳(這里是因為要演示使用了線上公開服務,測試時請使用測試服務)。
注意,這里的測試如果選擇了性能較低的測試對象,大部分流量會在服務器端排隊等候,導致吞吐量不大,這實際是服務器端處理過慢,與客戶端關系不大。
一般情況下一臺普通的pc在使用pipe進行測試時就可以讓服務器出現明顯延時。
原理
正常的http一般實現都是連接完成后(tcp握手)發生request流向服務器,然后及進入等待,收到response后才算結束(如下圖):
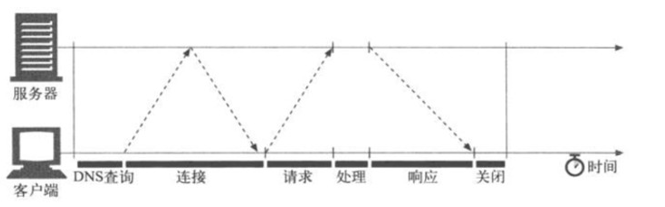
當然http1.1 即支持keep alive,完成一次收發后完全可以不關閉連接使用同一個鏈接發生下一個請求(如下圖):
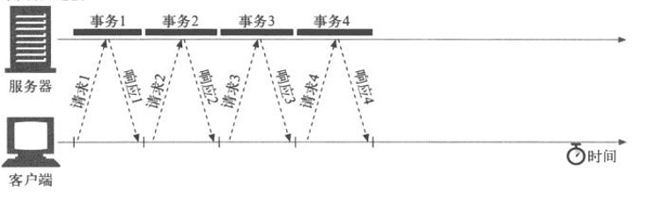
這種方式對性能的提升還是比較明顯的,特別早些年服務器性能有限,網絡資源匱乏,RTT大(網絡時延大)。不過對如今的情況,其實這些都已經不是最主要的問題了。
可以明顯看到上面的模式,是一定要等到response到達后,客戶端才能發起下一個request的,如果應用服務器需要時間處理,所有后面的請求都需要等待,即使不需要任何處理直接回復給客戶端,請求,回復在網絡上的時間也是必須完整的等下去,而且由于tcp傳輸本身的特性,速率是逐步上升的,這樣斷斷續續的發送接收十分影響tcp迅速達到線路性能***值。
pipe (管線式)正是回避了上面的問題,他不需要等回復達到即可直接發送(事實上http1.1協議也從來沒有講過必須要等response到達后客戶端才能發送下一個請求,只是為了方便應用層業務實現,一般的http庫都是這樣實現的,而現在看到的絕大多少http服務器都是默認支持pipe的),這樣發送與接收即可以分離開來(如下圖):
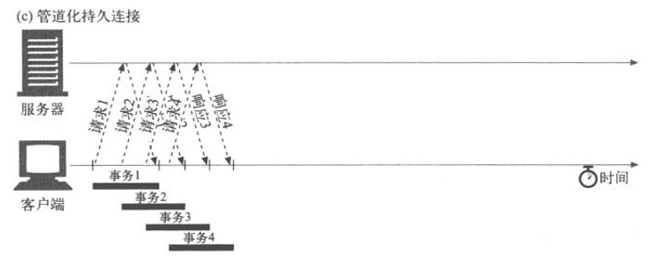
在事實情況下,發生可能會比這個圖表現的更快,請求1,2,3,4很可能被放到一個tcp包里被一次性全部發出去(這種模式也給部分應用帶來了麻煩,后面會講到)。
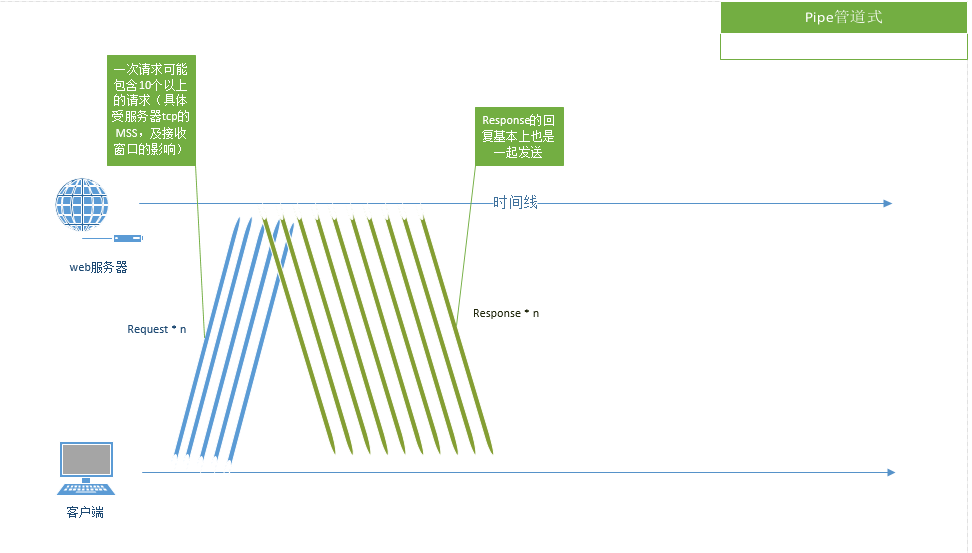
對于pipe相對真實的情況如上圖,多個請求會被打包在一起被發送,甚至有時是所有request發送完成后,服務器才開始回復***個response。
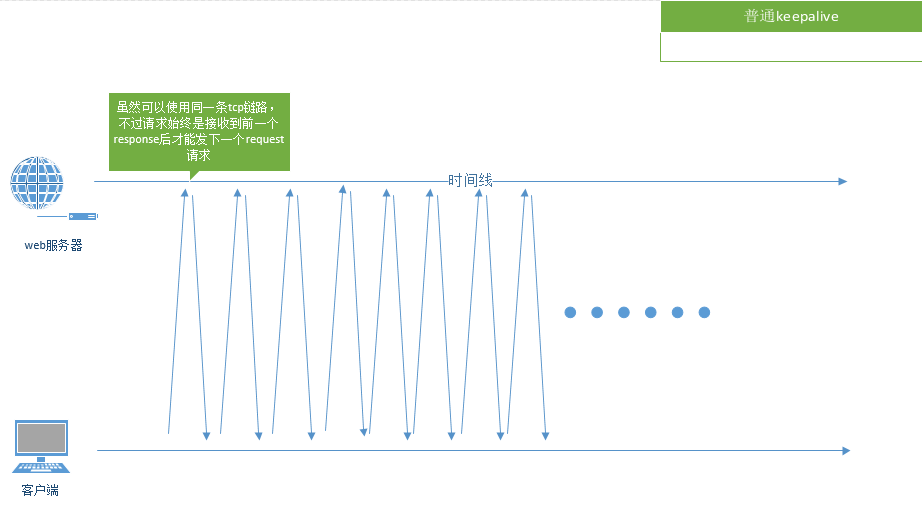
而普通的keepalive的模式如上圖,一條線代表一個請求,不僅一次只能發送一個,而且必須等待回復后才能發下一個。
下面看下實際測試中pipe的模式具體是什么模樣的。
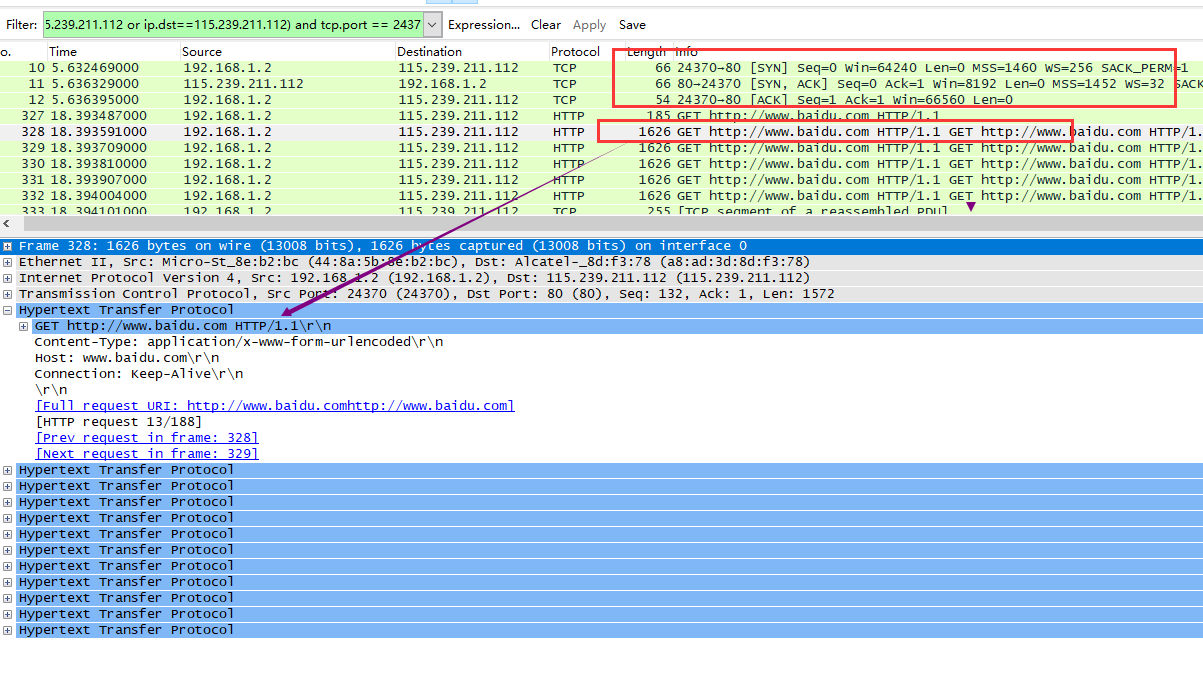
可以看到握手完成后(實際上握手時間也不長只用了4ms),隨后即直接開始了request的發送,可以看到后面的一個tcp包里直接包含了完整的12個請求。在沒有收到任何一個回復的情況下,就可以把所有要發送的請求提前全部發出(服務器已經關閉了Nagle算法)。
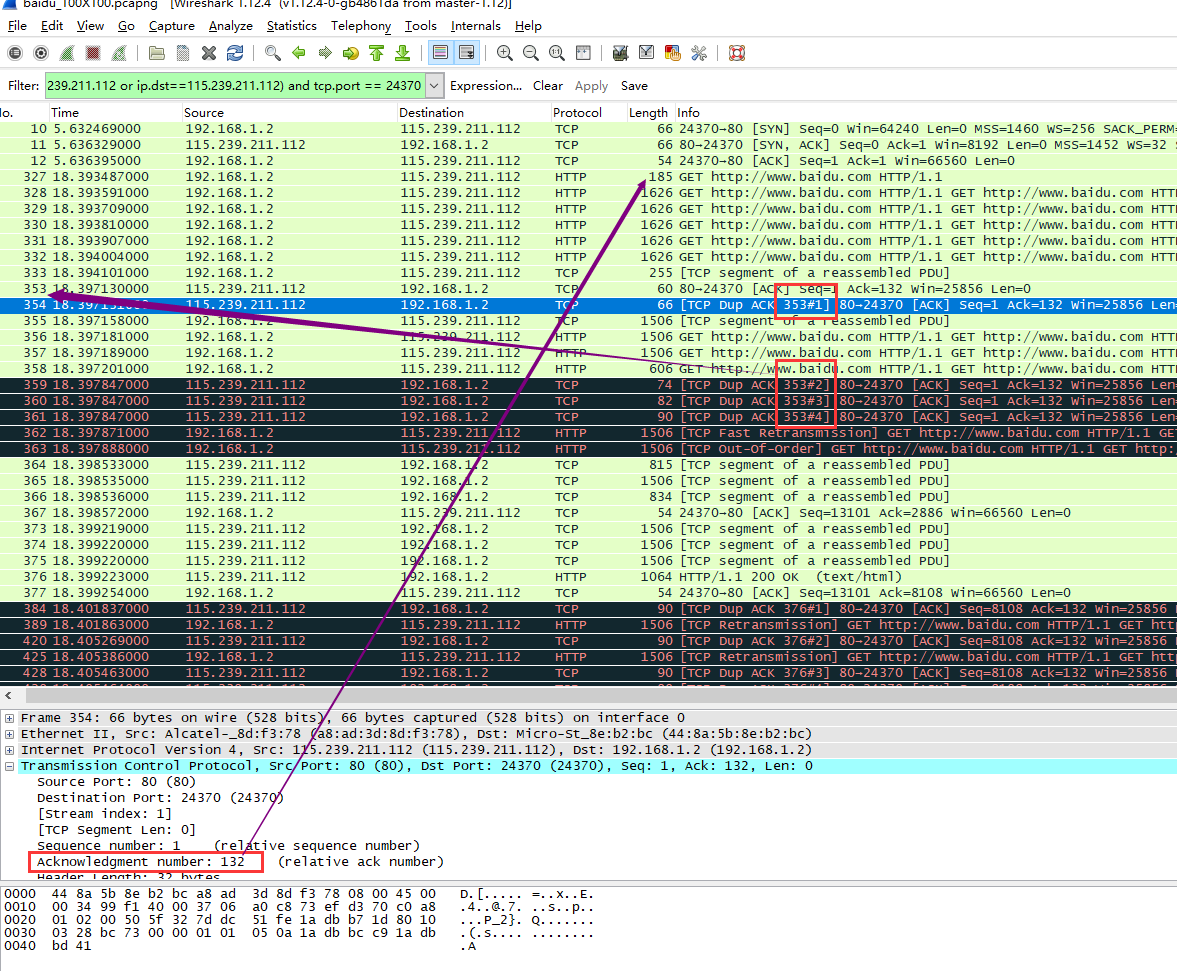
由于發送速度過快直到發出一大半近70個request的時候***個tcp確認包序號為353的包(只是確認包不是response)才發出(327的ack),而且服務器很快就發現下一個包出問題了并引發了TCP DUP ACK (https://ask.wireshark.org/questions/29216/why-are-duplicate-tcp-acks-being-seen-in-wireshark-capture 產生原因可以參考這里)。
【TCP DUP ACK 出現在接收方發現數據包缺口時(數據包失序),這種情況就會發送重復的ACK,這不僅用于快重傳,會觸發比快重傳更快的恢復機制(Fast Retransmission)如果發現重復的ACK,但是報文中未發現缺口,這表示你捕獲的是數據來源(而不是接收方),這是十分正常的如果數據在發往接收方的時候發生了丟失。你應該會看到一個重傳包】。
其實就是說服務器沒有發現下一個包后面又發了3次(一共4次·)TCP DUP ACK 都是針對353的,所以后面客戶端很快就重傳了TCP DUP ACK 所指定的丟失的包(即下面看到的362)
后面還可以看到由于過快的速度,還造成了部分的失序列(out of order)。不過需要說明的是,這些錯誤在tcp的傳輸中是很常見的,tcp有自己的一套高效的機制對這些錯誤進行恢復,即便有這些錯誤的存在也不會對pipe的實際性能造成影響。
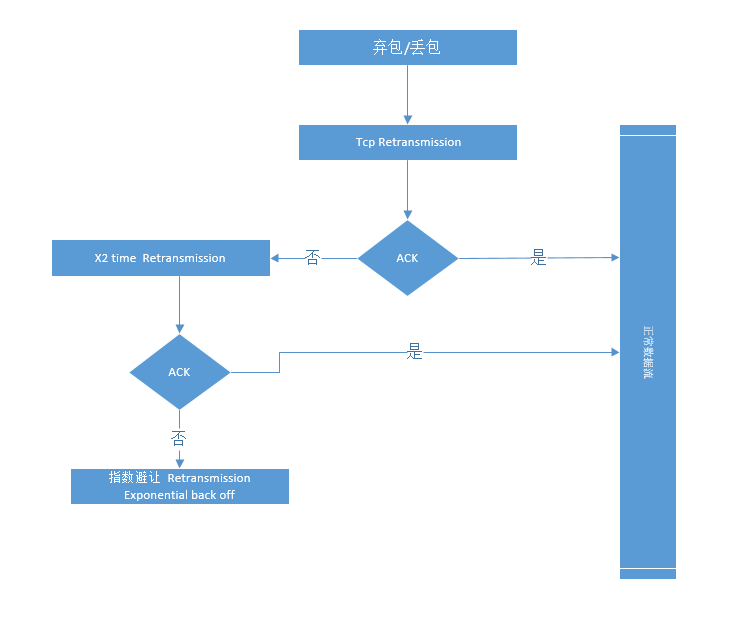
如果服務器異常誤包不能馬上被恢復可能會造成指數退避的情況如下圖:
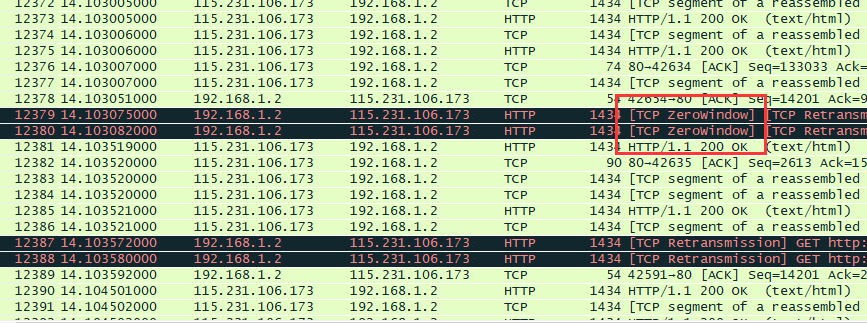
高速收發帶來的問題,不僅有丟包,失序,重傳,無論是客戶端還是服務器都會有接收窗口耗盡的情況,如果接收端窗口耗盡會出現TCP ZeroWIndow / Window full。 所以無論是客戶端還是服務器都需要快速讀取tcp緩沖區數據。
通過對TCP流的檢查可以確定在本次測試中的部分管道的100條request是全部發出后,response才逐步被服務器發出。
現在看一下response的回復情況:
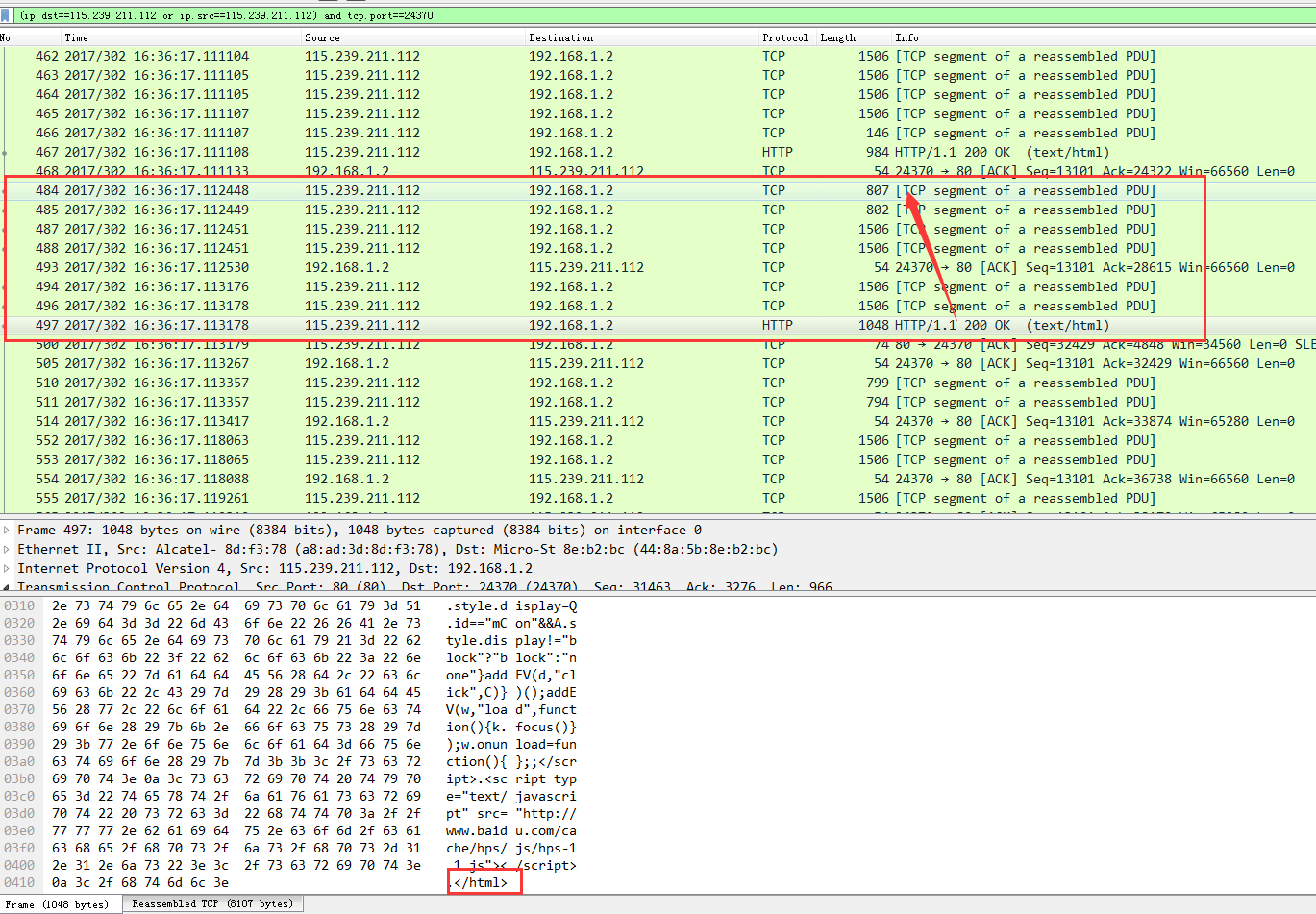
因為response本身很大,而客戶端的MSS只有1460 (上面看到的1506不是超過了MSS的意思,實際該數據包只有1424,加上48個字節的TCP包頭,20字節的ip包頭,14字節的以太網包頭一共是1506,正常tcp包頭為20字節因為這個tcp包被拆包了,所以包頭里多了28個字節的options)所以一個response被拆成了多個包。
通過報文不難看出這個response在網絡中傳輸大概花了1ms不到的時間(大概730微秒),因為看到是過濾掉過端口(指定管道)的流量,實際上在這不到1ms的時間里另外的管道也是可能同時在接收數據的。
pipe之所以能比常規請求方式性能高出這么多,主要有以下幾點:
1:管線式發送,每條request不要等response回復即可直接發送下一個(重點不在于使用的是同一條線路,而且不約等待回復)
2:多條請求打包發送,在網絡條件合適的情況下一個包可以包含多條request
3:只要服務器允許只需要創建極少tcp鏈接 (因為非局域網的TCP線路一般都遵循慢啟動,網絡正常情況下需要一定時間后效率才能達到***)
現在我們可以來說下pipe弊端:
實際pipe早就被http1.1所支持,并且大部分nginx服務器也支持并開啟了這一功能。
相比普通的http keepalive傳輸 pipe http 解決了HOL blocking (Head-of-Line Blocking),而正是不再遵循一發一收的模式,使得應用層不能直接將每個請求與回復一一對應起來,對部分需要提交并區分返回結果的POST一類的請求,這種方式顯的不是很友好。
解決方法其實也很簡單,在應用服務上為request于response加上唯一標簽即可以區分,或者直接使用HTTP2.0(https://tools.ietf.org/pdf/rfc7540.pdf)(這也是2.0的一個重要改進,http2.0也是通過類似的方式為其每個幀添加標識當前stream的id來實現區分的)。
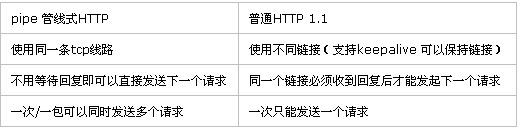
下面是pipe與常規http的簡單對比:
實現
如下為pipe的.NET簡單實現類庫,及應用該類庫的deom 測試工具。
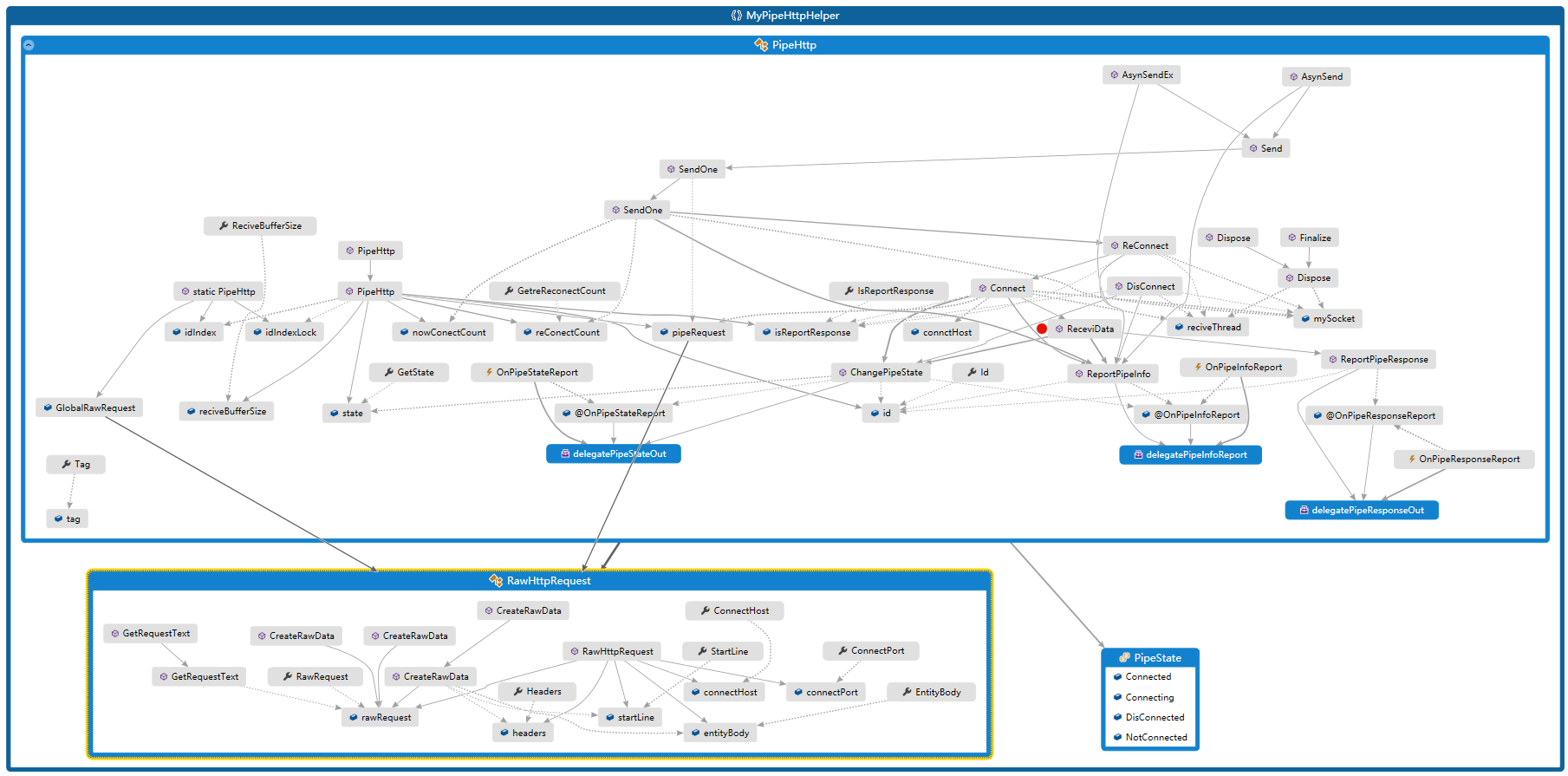
實現過程還是比較簡單的可直接參看GitHub工程,MyPipeHttpHelper為實現pipe的工具類(代碼中有較詳細的注釋),PipeHttpRuner為使用該工具類編寫的測試工具。