













送給DBA,讓數據庫自己解決繁瑣調參!
數據庫有很多參數,比如MySQL有幾百個參數,Oracle有上千個參數。這些參數控制著數據庫的方方面面,很大程度的影響了數據庫的性能。比如緩存容量和檢查點頻次。
DBA會花大量時間根據經驗來調優數據庫的參數,而公司需要花很大的價錢來雇資深的DBA。但是對于不同的硬件配置,不同的工作負載,對應的參數文件都是不同的。DBA不能簡單的重復使用之前調好的參數文件。這些復雜性令數據庫調優變得更加困難。
為解決這些問題,卡內基梅隆大學數據庫小組的教授、學生和研究人員開發了一個數據庫自動調參工具OtterTune,它能利用機器學習對數據庫的參數文件自動化的調優,能利用已有的數據訓練機器學習模型,進而自動化的推薦參數。它能很好的幫助DBA進行數據庫調優,將DBA從復雜繁瑣的調參工作中解放出來。
以前網上就有對OtterTune的報道,標題都比較嚇人。比如這篇:運維要失業了? 機器學習可自動優化你的數據庫管理系統[1]。
OtterTune的目的是為了幫助DBA,讓數據庫部署和調優更加容易,用機器來代替數據庫調參這個冗繁但又很重要的工作,甚至不需要專業知識也能完成。
OtterTune現在完全開源,Github上的版本就可以使用[2]。這個文檔中有一個步驟較全的例子可以上手,在AWS的m5d.xlarge機子上調優PostgreSQL 9.6數據庫,吞吐量從默認參數文件的每秒約500個事務提高到每秒約1000個事務,有興趣的朋友不妨試一試。
不過驚喜的是,我們發現這個通用模型在業界的很多地方都有真實的應用,不僅能調優數據庫的參數,還能夠調優操作系統內核的參數,甚至可以嘗試調優機器學習模型的參數。比如以下場景:
- 某歐洲銀行需要自動化調優數據庫集群的參數以提高性能,減少人工成本。
- 某大型云廠商需要在不影響性能的前提下盡量調低分配的資源(如內存), 減少硬件成本。
- 某紐約高頻交易公司需要調優機器的操作系統參數以優化機器性能,減少延遲,從而增加利潤。
本文將介紹OtterTune的內部原理,以及OtterTune的一些進展和嘗試,如用深度強化學習來調優數據庫參數。
由于本人水平有限,寫的不對的地方歡迎大家指正。更多資料請參考2017年SIGMOD[3]和2018年VLDB的論文[4]。
一、客戶端和服務端
OtterTune分為客戶端和服務端。目標數據庫是用戶需要調優參數的數據庫:
- OtterTune的客戶端安裝在目標數據庫所在機器上,收集目標數據庫的統計信息,并上傳到服務端。
- 服務端一般配置在云上,它收到客戶端的數據,訓練機器學習模型并推薦參數文件。
客戶端接到推薦的參數文件后,配置到目標數據庫上,測量其性能。以上步驟可以重復進行直到用戶對OtterTune推薦的參數文件滿意。
當用戶配置好OtterTune時,它能自動的持續推薦參數文件并把所得結果上傳到服務端可視化出來,而不需要DBA的干預。這樣能很大簡化DBA的工作,比如DBA可以配置好OtterTune后回家睡覺,第二天早上OtterTune可能就在一晚上的嘗試中找到了好的參數文件。
而OtterTune嘗試的所有參數文件及對應的數據庫性能和統計信息都能在服務端的可視化界面上輕易找到。
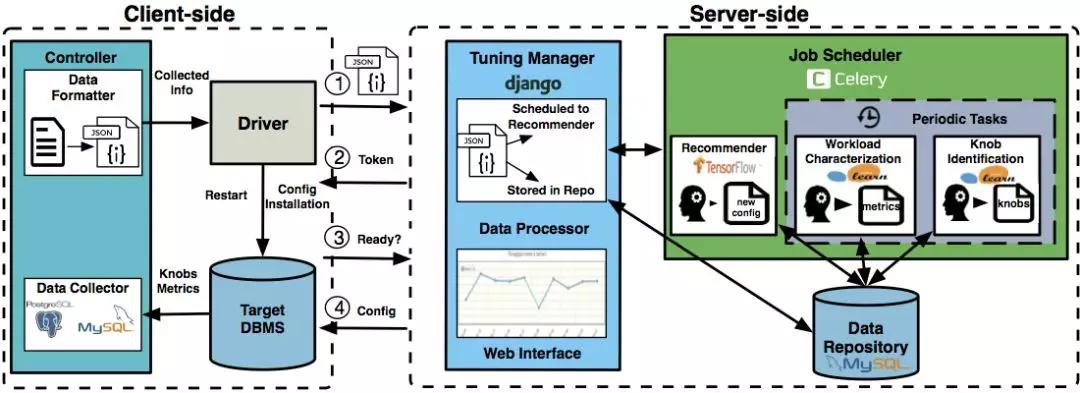
上圖是OtterTune的整體架構:
- 客戶端中controller由Java實現,用JDBC訪問目標數據庫來收集其統計信息;driver則用了Python的fabric,主要與服務端交互。
- 服務端用了Django來構建網站,并用Celery來調度機器學習任務;機器學習則調了tensorflow和sklearn。
關于OtterTune架構更詳細的內容可以參考2018 VLDB的demo paper[4].
二、隨機采樣
為了敘述方便,我們不妨假設參數文件中有10個重要參數需要調優。
我們將參數文件表示為:X=(x1,x2,…x10)
對應的數據庫性能為Y。Y可以是吞吐量,延遲時間,也可以是用戶自己定義的測量量。
我們假設目標測量量是延遲時間。則我們需要做的是調整這10個數據庫參數的值,使得數據庫的延遲盡可能少。即找到合適的X,使Y盡可能小。一個好的參數文件會降低數據庫的延遲,即X對應的Y越小,我們說X越好。
最簡單和直觀的方法便是隨機的進行嘗試,即給這10個要調的參數較大和較小值,在這范圍內隨機地選擇值進行嘗試。顯然這樣隨機的方法并不高效,可能需要試很多次才能得到好的參數文件。OtterTune也支持這種隨機方法以在沒有訓練數據時收集數據。
相比隨機采樣,還有一種更有效率的采樣方法叫做拉丁超立方采樣。
比如在0到3之間隨機找3個數,簡單隨機抽樣可能找的三個數都在0到1之間。而拉丁超立方采樣則在0到1間找一個數,1到2間找一個數,2到3間找一個數,更加分散。
推到高維也是類似的情況。如下圖是二維的情形,x1和x2取值都在0到1之間,用拉丁超立方采樣來取5個樣本點,先將x1和x2分成不同的范圍,再取樣本點使得每一行中只有一個樣本點,每一列中也只有一個樣本點。這樣能避免多個樣本點出現在相近的范圍內,使其更加分散。
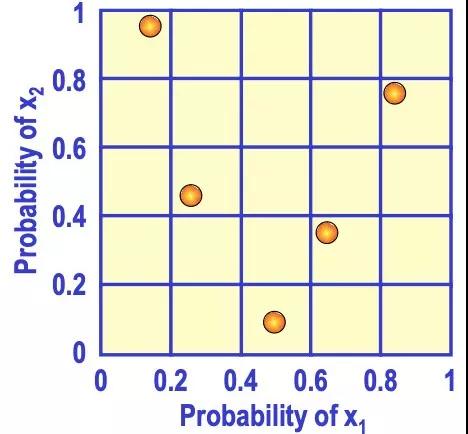
對于OtterTune來說,簡單隨機采樣嘗試的參數文件可能更集中和相似,而拉丁超立方采樣嘗試的參數文件更分散和不同。顯然后者能給我們更多的信息,因為嘗試相似的參數文件很可能得到的數據庫性能也相似,信息量少,而嘗試很不同的參數文件能更快的找到效果好的一個。
三、高斯過程回歸
上述的采樣方法并沒有利用機器學習模型對參數文件的效果進行預測。
- 當OtterTune沒有數據來訓練模型時,可以利用上述方法收集初始數據。
- 當我們有足夠的數據(X,Y)時,OtterTune訓練機器學習模型進行回歸,即估計出函數f:X→Y,使得對于參數文件X,用f(X)來估計數據庫延遲Y的值。則問題變為尋找合適的X,使f(X)的值盡量小。這樣我們在f上面做梯度下降即可找出合適的X。
如下圖所示,橫坐標是兩個參數——緩存大小和日志文件大小,縱坐標是數據庫延遲(越低越好):
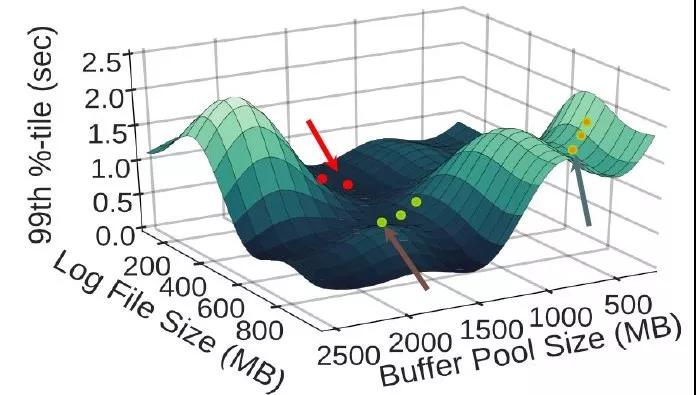
OtterTune用回歸模型估計出了f,即給定這兩個參數值,估計出其對應的數據庫延遲。接著用梯度下降找到合適的參數值使延遲盡可能低。
OtterTune用高斯過程回歸來估計上述的函數f。用高斯回歸的好處之一是它不僅能在給定X時估計對應的Y值,還能估計它的置信區間。
這能恰當的刻畫調參的情況:對于同樣的參數文件X, 在數據庫上多次跑相同的查詢時,由于誤差緣故,每次得到的數據庫性能也可能不一樣。比如同樣的參數文件和查詢語句,這次執行的數據庫延遲是1.8秒,下次執行的延遲可能是2秒,但每次得到的延遲很大概率是相近的。
高斯過程回歸能估計出均值m(X)和標準差s(X),進而能求出置信區間。比如上述例子中,通過回歸我們估計其延遲的均值是1.9秒,標準差是0.1秒,則其95%的概率在1.7秒和2.1秒之間。
再來說說探索(exploration)和利用(exploitation):
- 探索即在數據點不多的未知區域探索新的點。
- 利用即在數據點足夠多的已知區域利用這些數據訓練機器學習模型進行估計,再找出好的點。
比如說我們已知10個數據點(X,Y),有9個點的X在0到1之間,有1個點的X在1到2之間。X在0到1之間的數據點較多,可以利用這些數據點進行回歸來估計f:X->Y,再利用f來找到合適的X使估計的Y值盡量好,這個過程即為利用。
而探索則是嘗試未知區域新的點,如X在1到2間的點只有一個已知點,信息很少,很難估計f。我們在1到2間選一個X點進行嘗試,雖然可能得到的效果不好,但能增加該區域內的信息量。當該區域內已知點足夠多時便能利用回歸找到好的點了。
OtterTune推薦的過程中,既要探索新的區域,也要利用已知區域的數據進行推薦。即需要平衡探索和利用,否則可能會陷入局部較優而無法找到全局較優的點。比如一直利用已知區域的數據來推薦,雖然能找到這個區域較好的點,但未知區域可能有效果更好的點未被發現。
如何很好的平衡探索和利用一直是個復雜的問題,既要求能盡量找到好的點,又要求用盡量少的次數找到這個點。
而OtterTune采用的高斯過程回歸能很好的解決這個問題。核心思想是當數據足夠多時,我們利用這些數據推薦;而當缺少數據時,我們在點最少的區域進行探索,探索最未知的區域能給我們的信息量。
以上利用了高斯過程回歸的特性:它會估計出均值m(X)和標準差s(X),若X周圍的數據不多,則它估計的標準差s(X)會偏大,直觀的理解是若數據不多,則不確定性會大,體現在標準差偏大。反之,數據足夠時,標準差會偏小,因為不確定性減少。
而OtterTune用置信區間上界Upper Confidence Bound來平衡探索和利用。
不妨假設我們需要找X使Y值盡可能大。則U(X) = m(X) + k*s(X), 其中k > 0是可調的系數。我們只要找X使U(X)盡可能大即可。
- 若U(X)大,則可能m(X)大,也可能s(X)大。
- 若s(X)大,則說明X周圍數據不多,OtterTune在探索未知區域新的點。
- 若m(X)大,即估計的Y值均值大, 則OtterTune在利用已知數據找到效果好的點。公式中系數k影響著探索和利用的比例,k越大,越鼓勵探索新的區域。
四、有數據和沒數據
OtterTune用來訓練模型的數據好壞很大程度上影響了其最終效果。只要有合適的訓練數據,一般OtterTune前幾次推薦的參數文件就能得到理想的效果。
而當缺少訓練數據(或數據集中),甚至沒有任何之前的數據時,OtterTune又該如何處理?
當OtterTune沒有任何數據時,高斯過程回歸也能有效的在盡量少的次數內找到好的參數文件。當數據少時,OtterTune傾向探索而非利用,而每次探索新的參數文件時都能盡量的增加信息量,從而減少探索的次數。
這種方法比隨機采樣和拉丁超立方采樣都要高效。同時OtterTune也可先用拉丁超立方采樣選取少量的一些參數文件進行嘗試作為初始數據,之后再用高斯過程回歸進行推薦。
其實在OtterTune之前,有系統iTuned[5]就用高斯過程回歸在沒有數據時推薦參數文件。
而OtterTune的改進是利用之前收集的數據進行推薦以大幅度減少嘗試的次數和等待時間,提高推薦效果。
想想看當OtterTune的一個服務端配置到云上,而多個客戶端進行訪問時,OtterTune會將所有用戶嘗試的參數文件和對應的性能數據存下來進行利用。這意味著用OtterTune的人越多,用的時間越長,它收集的訓練數據越多,推薦效果越好。
除此之外,OtterTune還利用Lasso回歸來自動的選取需要調整的重要參數。數據庫有成百上千的參數,而我們只要調其中重要的幾個,需要調整哪些參數可以根據DBA的經驗,同時OtterTune也利用機器學習將參數的重要性排序,從而選出最重要的幾個參數。
另外對于不同的工作負載,對應的參數文件也不同。如OLTP工作負載通常是很多個簡單的查詢(如insert,delete),而OLAP工作負載通常是幾個復雜查詢(通常有多個表的join)。對于OLAP和OLTP,他們需要調整的參數和優值都不相同。
OtterTune現在的做法是用一些系統的統計量(如讀/寫的字節數)來刻畫工作負載,在已有數據中找到和用戶工作負載最相似的一個,然后用最相似的工作負載對應的數據進行推薦。
五、深度強化學習
在OtterTune的進展中,我們嘗試了深度強化學習的方法來進行數據庫調參,因為我們發現數據庫調參的過程能很好的刻畫成強化學習的問題。
強化學習問題中有狀態、動作,以及環境所給予的反饋。
如下圖所示,整個過程是在當前狀態(st)和環境的反饋(rt)下做動作(at),然后環境會產生下一狀態(st+1)和反饋(rt+1),再進行下一個動作(at+1)。
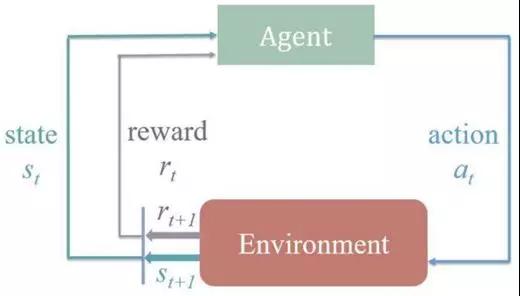
數據庫調參過程中,狀態即是參數文件,動作即是調整某個參數的值,而反饋即是參數文件下數據庫的性能。
所以我們對于當前的參數文件,調整某個參數的值,而得到新的參數文件,對這個新的參數文件做測試得到對應的數據庫性能,再根據性能的好壞繼續調整參數的值。
這樣數據庫調參的過程就被很好的刻畫成強化學習的問題,而深度強化學習即是其中的狀態或動作由神經網絡來表示。
我們用了Deep Deterministic Policy Gradient (DDPG)算法,主要是因為DDPG能允許動作可以在連續的區間上取值。對于調參來說,動作即是調整某個參數的值,比如調整內存容量,DDPG允許我們嘗試128MB到16GB的任意值,這個區間是連續的。
而很多別的算法只允許動作在離散區間上,比如只允許取幾個值中的一個值。通過實現和優化DDPG,最終深度強化學習推薦出的參數文件與高斯過程回歸推薦出的效果相似。但我們發現之前的高斯過程回歸(GPR)更有優勢,能用更少的時間和次數找到滿意的參數文件。
如下圖中所示,我們跑了TPC-H基準中的一條查詢(Query 13),OtterTune一次次的推薦參數文件直到其達到好的效果(即對應的數據庫延遲變低)。
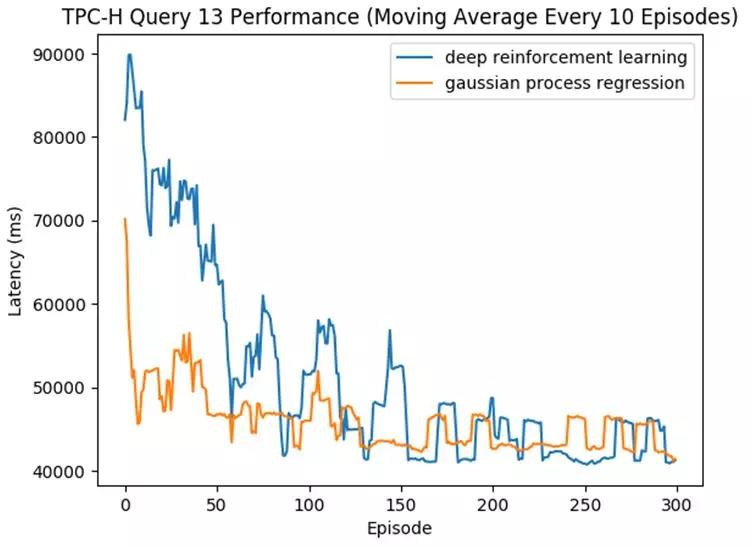
該圖橫坐標是推薦的次數,縱坐標是數據庫的延遲,延遲越低越好。藍線是深度強化學習,而黃線代表高斯過程回歸模型。
可見兩個模型最終推薦出的文件效果相似,但高斯過程回歸用了更少的次數便收斂,推薦出了好的參數文件。而深度強化學習需要嘗試更多的次數才能達到類似效果。
我們發現:
- DDPG算法模型有一些參數也需要調整,而這些參數對效果的影響很大。調整算法模型的參數也是個費時費力的過程。這樣就陷入尷尬的局面,OtterTune是用來自動調整數據庫參數的工具,而OtterTune自己算法模型的參數也需要調整。相比而言,GPR的模型參數可以自動的進行調整,從而實現OtterTune真正的自動化。
- GPR能用Upper Confidence Bound更好的平衡探索(exploration)和利用(exploitation),相比DDPG更加高效。 這在沒有或缺少數據的情況下,GPR能用更少的次數找到好的參數文件。
- DDPG是更加復雜的模型,其中還有神經網絡,可解釋性差。需要更多的數據和更長的時間來訓練和收斂。雖然能達到和GPR一樣的推薦效果,但往往需要更多的次數和更長的時間,意味著用戶需要等更久才能得到滿意的參數文件。
六、展望
對于數據庫來說,有很多部分都能嘗試與機器學習結合。比如預測數據庫一段時間的工作負載,如通過挖掘數據庫的日志來做自動預警,再到更核心的部分,如學習數據庫索引,甚至幫助優化器做查詢優化。
OtterTune專注的參數文件調優只是其中的一部分。由于OtterTune和數據庫的交互只是一個參數文件,這使得該工具更加通用,理論上能適用于所有的數據庫。
當要調參一個新的數據庫時,我們只需要給OtterTune該數據庫的一些參數和統計量信息即可,不需要去改動這個數據庫的任何代碼。
再者,OtterTune的通用框架也可以用于其他系統的調參,如我們嘗試用OtterTune來調優操作系統的內核參數也取得了不錯的效果。
現在的OtterTune仍有要改進的地方:
- 比如假定了硬件配置需要一樣,而我們希望OtterTune能利用在不同的硬件配置上的數據來訓練模型進行推薦。
- 再比如現在OtterTune每次只推薦一個文件,當有多個相同機器時,我們希望一次推薦多個文件并行的去嘗試,這樣能加快推薦速度。
另外還可以嘗試與其他部分的機器學習方法結合,比如可以先用機器學習方法預測工作負載,再根據預測的工作負載提前調優參數文件。
用機器學習來優化系統是最近很火很前沿的一個話題,無論是在工業界還是在學術界。
全球數據庫廠商Oracle如今的賣點便是autonomous database[6] ,即自適應性數據庫,利用機器學習來自動優化數據庫來減少DBA的干預,要知道在美國雇一個資深的DBA是多么困難的一件事。Oracle投入大量的專家和資金來做這件事便證明了它的工業價值。
學術上,一些ML和系統的大佬在前兩年開了一個新的會議叫SysML[7],專注于機器學習和系統的交叉領域。更不用說越來越多的相關論文,比如卡內基梅隆大學的OtterTune,再如MIT和谷歌開發的用神經網絡學習數據庫的索引[8]。
以谷歌Jeff Dean在演講中的話結尾:
計算機系統中充滿了經驗性的規則,到處是在用啟發式的方法來做決定,而用機器學習來學系統的核心部分會讓其變得更好更加自適應,這個領域充滿著機會[9]。
參考
[1]運維要失業了? 機器學習可自動優化你的數據庫管理系統
www.sohu.com/a/146016004_465914
[2]https://github.com/cmu-db/ottertune
[3]Automatic Database Management System Tuning Through Large-scale Machine Learning. Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, Bohan Zhang. SIGMOD 2017
[4]A Demonstration of the OtterTune Automatic Database Management System Tuning Service. Bohan Zhang, Dana Van Aken, Justin Wang, Tao Dai, Shuli Jiang, Siyuan Sheng, Andrew Pavlo, Geoffrey J. Gordon. VLDB 2018
[5]Tuning Database Configuration Parameters with iTuned. Songyun Duan, Vamsidhar Thummala, Shivnath Babu. VLDB 2009
[6]https://www.oracle.com/database/what-is-autonomous-database.html
[7]https://www.sysml.cc/
[8]The Case for Learned Index Structures. Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, Neoklis Polyzotis. SIGMOD 2018
[9]http://learningsys.org/nips17/assets/slides/dean-nips17.pdf















