













如履薄冰:Redis懶惰刪除的巨大犧牲
大家都知道 Redis 是單線程的,但是 Redis 4.0 增加了懶惰刪除功能,懶惰刪除需要使用異步線程對已刪除的節點進行內存回收,這意味著 Redis 底層其實并不是單線程,它內部還有幾個額外的鮮為人知的輔助線程。
這幾個輔助線程在 Redis 內部有一個特別的名稱,就是“BIO”,全稱是 Background IO,意思是在背后默默干活的 IO 線程。
不過內存回收本身并不是什么 IO 操作,只是 CPU 的計算消耗可能會比較大而已。
01.懶惰刪除的最初實現不是異步線程
Redis 大佬 Antirez 實現懶惰刪除時,它并不是一開始就想到了異步線程。它最初的嘗試是在主線程里,使用類似于字典漸進式搬遷的方式來實現漸進式刪除回收。
比如對于一個非常大的字典來說,懶惰刪除是采用類似于 scan 操作的方法,通過遍歷第一維數組來逐步刪除回收第二維鏈表的內容,等到所有鏈表都回收完了,再一次性回收第一維數組。這樣也可以達到刪除大對象時不阻塞主線程的效果。
但是說起來容易做起來卻很難。漸進式回收需要仔細控制回收頻率,它不能回收得太猛,這會導致 CPU 資源占用過多,也不能回收得像蝸牛那么慢,因為內存回收不及時可能導致內存消耗持續增長。
Antirez 需要采用合適的自適應算法來控制回收頻率。他首先想到的是通過檢測內存增長的趨勢是增長“+1”還是下降“-1”,來漸進式調整回收頻率系數,這樣的自適應算法實現也很簡單。
但是測試后發現在服務繁忙的時候,QPS 會下降到正常情況下 65% 的水平,這點非常致命。
所以 Antirez 才使用了如今的方案——異步線程。異步線程這套方案就簡單多了,釋放內存不用為每種數據結構適配一套漸進式釋放策略,也不用搞個自適應算法來仔細控制回收頻率,只是將對象從全局字典中摘掉,然后往隊列里一扔,主線程就干別的去了。異步線程從隊列里取出對象來,直接走正常的同步釋放邏輯就可以了。
不過使用異步線程也是有代價的,主線程和異步線程之間在內存回收器(jemalloc)的使用上存在競爭。
這點競爭消耗是可以忽略不計的,因為 Redis 的主線程在內存的分配與回收上花的時間相對整體運算時間而言是極少的。
02.異步線程方案其實也相當復雜
上文筆者剛說異步線程方案很簡單,為什么在這里又說它很復雜呢?因為有一點,筆者之前沒有提到,這點非常可怕,嚴重阻礙了異步線程方案的改造,那就是 Redis 的內部對象有共享機制。
比如集合的并集操作 sunionstore 用來將多個集合合并成一個新集合。
- > sadd src1 value1 value2 value3
- (integer) 3
- > sadd src2 value3 value4 value5
- (integer) 3
- > sunionstore dest src1 src2
- (integer) 5
- > smembers dest
- 1) "value2"
- 2) "value3"
- 3) "value1"
- 4) "value4"
- 5) "value5"
我們看到新的集合包含了舊集合的所有元素。但是這里有一個我們沒看到的 trick,那就是底層的字符串對象被共享了,如下圖所示。
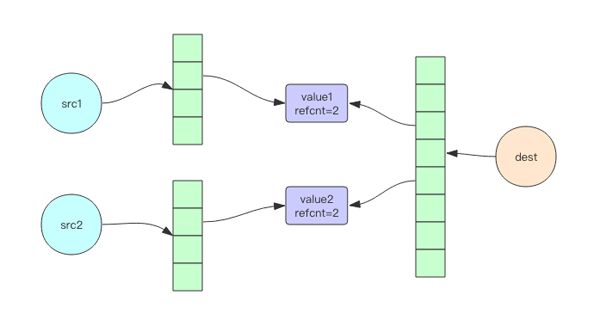
為什么對象共享是懶惰刪除的巨大障礙呢?因為懶惰刪除相當于徹底砍掉某個樹枝,將它扔到異步刪除隊列里去。
注意這里必須是徹底刪除,不能藕斷絲連。如果底層對象是共享的,那就做不到徹底刪除。如圖 2 所示的刪除就不是徹底刪除。
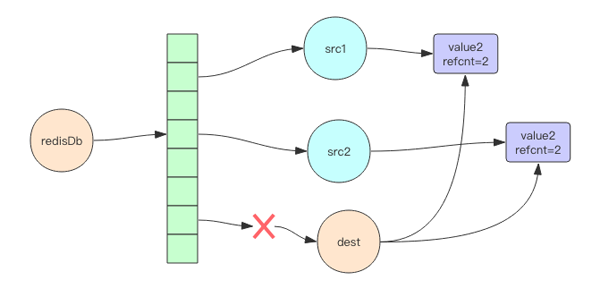
所以 Antirez 為了支持懶惰刪除,將對象共享機制徹底拋棄,它將這種對象結構稱為“share-nothing”,也就是無共享設計。
但是甩掉對象共享談何容易!這種對象共享機制散落在源代碼的各個角落,牽一發而動全身,改起來猶如在布滿地雷的道路上小心翼翼地行走。
不過 Antirez 還是決心改了,它將這種改動描述為“絕望而瘋狂”,可見改動之大、之深、之險,前后花了好幾周時間才改完。
不過這次修改的效果也是很明顯的,對象的刪除操作再也不會導致主線程卡頓了。
03.異步刪除的實現
主線程需要將刪除任務傳遞給異步線程,它是通過一個普通的雙向鏈表來傳遞的。因為鏈表需要支持多線程并發操作,所以它需要有鎖來保護。
執行懶惰刪除時,Redis 將刪除操作的相關參數封裝成一個 bio_job 結構,然后追加到鏈表尾部。異步線程通過遍歷鏈表摘取 job 元素來挨個執行異步任務。
- struct bio_job {
- time_t time; // 時間字段暫時沒有使用,應該是預留的
- void *arg1, *arg2, *arg3;
- };
我們注意到這個 job 結構有三個參數。為什么刪除對象需要三個參數呢?我們看如下代碼。
- /* What we free changes depending on what arguments are set:
- * arg1 -> free the object at pointer.
- * arg2 & arg3 -> free two dictionaries (a Redis DB).
- * only arg3 -> free the skiplist. */
- if (job->arg1)
- // 釋放一個普通對象,string/set/zset/hash 等,用于普通對象的異步刪除
- lazyfreeFreeObjectFromBioThread(job->arg1);
- else if (job->arg2 && job->arg3)
- // 釋放全局 redisDb 對象的 dict 字典和 expires 字典,用于 flushdb
- lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
- else if (job->arg3)
- // 釋放 Cluster 的 slots_to_keys 對象,請參見第 5.7 節
- lazyfreeFreeSlotsMapFromBioThread(job->arg3);
可以看到,通過組合這三個參數可以實現不同結構的釋放邏輯。
接下來我們繼續追蹤普通對象的異步刪除 lazyfreeFreeObjectFromBioThread 是如何進行的,請仔細閱讀代碼注釋。
- void lazyfreeFreeObjectFromBioThread(robj *o) {
- decrRefCount(o); // 降低對象的引用計數,如果為零,就釋放
- atomicDecr(lazyfree_objects,1); // lazyfree_objects 為待釋放對象的數量,用于統計
- }
- // 減少引用計數
- void decrRefCount(robj *o) {
- if (o->refcount == 1) {
- // 該釋放對象了
- switch(o->type) {
- case OBJ_STRING: freeStringObject(o); break;
- case OBJ_LIST: freeListObject(o); break;
- case OBJ_SET: freeSetObject(o); break;
- case OBJ_ZSET: freeZsetObject(o); break;
- case OBJ_HASH: freeHashObject(o); break; // 釋放 hash 對象,繼續追蹤
- case OBJ_MODULE: freeModuleObject(o); break;
- case OBJ_STREAM: freeStreamObject(o); break;
- default: serverPanic("Unknown object type"); break;
- }
- zfree(o);
- } else {
- if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
- if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--; // 引用計數減 1
- }
- }
- // 釋放 hash 對象
- void freeHashObject(robj *o) {
- switch (o->encoding) {
- case OBJ_ENCODING_HT:
- // 釋放字典,我們繼續追蹤
- dictRelease((dict*) o->ptr);
- break;
- case OBJ_ENCODING_ZIPLIST:
- // 如果是壓縮列表可以直接釋放
- // 因為壓縮列表是一整塊字節數組
- zfree(o->ptr);
- break;
- default:
- serverPanic("Unknown hash encoding type");
- break;
- }
- }
- // 釋放字典,如果字典正在遷移中,ht[0] 和 ht[1] 分別存儲舊字典和新字典
- void dictRelease(dict *d)
- {
- _dictClear(d,&d->ht[0],NULL); // 繼續追蹤
- _dictClear(d,&d->ht[1],NULL);
- zfree(d);
- }
- // 這里要釋放 hashtable 了
- // 需要遍歷第一維數組,然后繼續遍歷第二維鏈表,雙重循環
- int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
- unsigned long i;
- /* Free all the elements */
- for (i = 0; i < ht->size && ht->used > 0; i++) {
- dictEntry *he, *nextHe;
- if (callback && (i & 65535) == 0) callback(d->privdata);
- if ((he = ht->table[i]) == NULL) continue;
- while(he) {
- nextHe = he->next;
- dictFreeKey(d, he); // 先釋放 key
- dictFreeVal(d, he); // 再釋放 value
- zfree(he); // 最后釋放 entry
- ht->used--;
- he = nextHe;
- }
- }
- /* Free the table and the allocated cache structure */
- zfree(ht->table); // 可以回收第一維數組了
- /* Re-initialize the table */
- _dictReset(ht);
- return DICT_OK; /* never fails */
- }
這些代碼散落在多個不同的文件,我將它們湊到了一塊便于讀者閱讀。從代碼中我們可以看到釋放一個對象要深度調用一系列函數,每種對象都有它獨特的內存回收邏輯。
04.5.9.4 隊列安全
前面提到任務隊列是一個不安全的雙向鏈表,需要使用鎖來保護它。當主線程將任務追加到隊列之前需要給它加鎖,追加完畢后,再釋放鎖,還需要喚醒異步線程——如果其在休眠的話。
- void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3) {
- struct bio_job *job = zmalloc(sizeof(*job));
- job->timetime = time(NULL);
- job->arg1arg1 = arg1;
- job->arg2arg2 = arg2;
- job->arg3arg3 = arg3;
- pthread_mutex_lock(&bio_mutex[type]); // 加鎖
- listAddNodeTail(bio_jobs[type],job); // 追加任務
- bio_pending[type]++; // 計數
- pthread_cond_signal(&bio_newjob_cond[type]); // 喚醒異步線程
- pthread_mutex_unlock(&bio_mutex[type]); // 釋放鎖
- }
異步線程需要對任務隊列進行輪詢處理,依次從鏈表表頭摘取元素逐個處理。摘取元素的時候也需要加鎖,摘出來之后再解鎖。如果一個元素都沒有,它需要等待,直到主線程來喚醒它繼續工作。
- // 異步線程執行邏輯
- void *bioProcessBackgroundJobs(void *arg) {
- ...
- pthread_mutex_lock(&bio_mutex[type]); // 先加鎖
- ...
- // 循環處理
- while(1) {
- listNode *ln;
- /* The loop always starts with the lock hold. */
- if (listLength(bio_jobs[type]) == 0) {
- // 對列空,那就睡覺吧
- pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]);
- continue;
- }
- /* Pop the job from the queue. */
- ln = listFirst(bio_jobs[type]); // 獲取隊列頭元素
- job = ln->value;
- /* It is now possible to unlock the background system as we know have
- * a stand alone job structure to process.*/
- pthread_mutex_unlock(&bio_mutex[type]); // 釋放鎖
- // 這里是處理過程,為了省紙,就略去了
- ...
- // 釋放任務對象
- zfree(job);
- ...
- // 再次加鎖繼續處理下一個元素
- pthread_mutex_lock(&bio_mutex[type]);
- // 因為任務已經處理完了,可以放心從鏈表中刪除節點了
- listDelNode(bio_jobs[type],ln);
- bio_pending[type]--; // 計數減 1
- }
研究完這些加鎖解鎖的代碼后,筆者開始有點擔心主線程的性能。我們都知道加鎖解鎖是一個相對比較耗時的操作,尤其是悲觀鎖最為耗時。如果刪除很頻繁,主線程豈不是要頻繁加鎖解鎖。
所以這里肯定還有優化空間,Java 的 ConcurrentLinkQueue 就沒有使用這樣粗粒度的悲觀鎖,它優先使用 cas 來控制并發。那就讓我們就期待 Redis 在未來的版本里對它進一步改造優化吧!














