再有人問你分布式鎖是什么,就把這篇文章發給他
現在面試,一般都會聊聊分布式系統這塊的東西。通常面試官都會從服務框架(Spring Cloud、Dubbo)聊起,一路聊到分布式事務、分布式鎖、ZooKeeper 等知識。
所以咱們就來聊聊分布式鎖這塊的知識,先具體的來看看 Redis 分布式鎖的實現原理。
說實話,如果在公司里落地生產環境用分布式鎖的時候,一定是會用開源類庫的,比如 Redis 分布式鎖,一般就是用 Redisson 框架就好了,非常的簡便易用。
大家如果有興趣,可以去 Redisson 的官網,看看如何在項目中引入 Redisson 的依賴,然后基于 Redis 實現分布式鎖的加鎖與釋放鎖。
下面給大家看一段簡單的使用代碼片段,先直觀的感受一下:
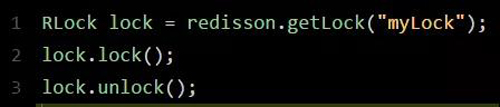
怎么樣,上面那段代碼,是不是感覺簡單的不行!此外,人家還支持 Redis 單實例、Redis 哨兵、Redis Cluster、redis master-slave 等各種部署架構,都可以給你***實現。
Redisson 實現 Redis 分布式鎖的底層原理
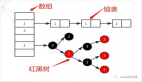
好的,接下來就通過一張手繪圖,給大家說說 Redisson 這個開源框架對 Redis 分布式鎖的實現原理。

加鎖機制
咱們來看上面那張圖,現在某個客戶端要加鎖。如果該客戶端面對的是一個 Redis Cluster 集群,他首先會根據 Hash 節點選擇一臺機器。
這里注意,僅僅只是選擇一臺機器!這點很關鍵!緊接著,就會發送一段 Lua 腳本到 Redis 上,那段 Lua 腳本如下所示:
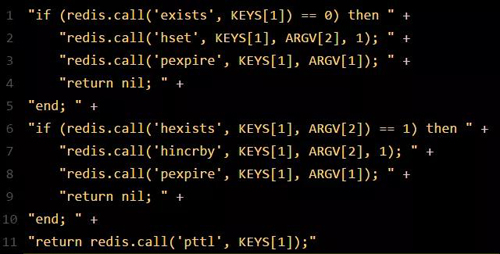
為啥要用 Lua 腳本呢?因為一大坨復雜的業務邏輯,可以通過封裝在 Lua 腳本中發送給 Redis,保證這段復雜業務邏輯執行的原子性。
那么,這段 Lua 腳本是什么意思呢?這里 KEYS[1] 代表的是你加鎖的那個 Key,比如說:RLock lock = redisson.getLock("myLock");這里你自己設置了加鎖的那個鎖 Key 就是“myLock”。
ARGV[1] 代表的就是鎖 Key 的默認生存時間,默認 30 秒。ARGV[2] 代表的是加鎖的客戶端的 ID,類似于下面這樣:8743c9c0-0795-4907-87fd-6c719a6b4586:1。
給大家解釋一下,***段 if 判斷語句,就是用“exists myLock”命令判斷一下,如果你要加鎖的那個鎖 Key 不存在的話,你就進行加鎖。如何加鎖呢?很簡單,用下面的命令:hset myLock。
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1,通過這個命令設置一個 Hash 數據結構,這行命令執行后,會出現一個類似下面的數據結構:
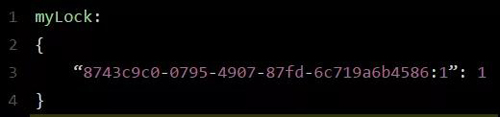
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”這個客戶端對“myLock”這個鎖 Key 完成了加鎖。
接著會執行“pexpire myLock 30000”命令,設置 myLock 這個鎖 Key 的生存時間是 30 秒。好了,到此為止,加鎖完成了。
鎖互斥機制
那么在這個時候,如果客戶端 2 來嘗試加鎖,執行了同樣的一段 Lua 腳本,會咋樣呢?
很簡單,***個 if 判斷會執行“exists myLock”,發現 myLock 這個鎖 Key 已經存在了。
接著第二個 if 判斷,判斷一下,myLock 鎖 Key 的 Hash 數據結構中,是否包含客戶端 2 的 ID,但是明顯不是的,因為那里包含的是客戶端 1 的 ID。
所以,客戶端 2 會獲取到 pttl myLock 返回的一個數字,這個數字代表了 myLock 這個鎖 Key 的剩余生存時間。
比如還剩 15000 毫秒的生存時間。此時客戶端 2 會進入一個 while 循環,不停的嘗試加鎖。
watch dog 自動延期機制
客戶端 1 加鎖的鎖 Key 默認生存時間才 30 秒,如果超過了 30 秒,客戶端 1 還想一直持有這把鎖,怎么辦呢?
簡單!只要客戶端 1 一旦加鎖成功,就會啟動一個 watch dog 看門狗,他是一個后臺線程,會每隔 10 秒檢查一下,如果客戶端 1 還持有鎖 Key,那么就會不斷的延長鎖 Key 的生存時間。
可重入加鎖機制
那如果客戶端 1 都已經持有了這把鎖了,結果可重入的加鎖會怎么樣呢?比如下面這種代碼:

這時我們來分析一下上面那段 Lua 腳本。***個if判斷肯定不成立,“exists myLock”會顯示鎖 Key 已經存在了。
第二個 if 判斷會成立,因為 myLock 的 Hash 數據結構中包含的那個 ID,就是客戶端 1 的那個 ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”。
此時就會執行可重入加鎖的邏輯,他會用:incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1,通過這個命令,對客戶端 1 的加鎖次數,累加 1。
此時 myLock 數據結構變為下面這樣:
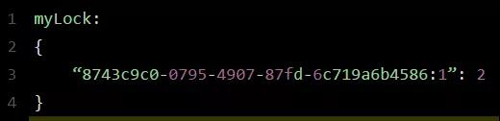
大家看到了吧,那個 myLock 的 Hash 數據結構中的那個客戶端 ID,就對應著加鎖的次數。
釋放鎖機制
如果執行 lock.unlock(),就可以釋放分布式鎖,此時的業務邏輯也是非常簡單的。其實說白了,就是每次都對 myLock 數據結構中的那個加鎖次數減 1。
如果發現加鎖次數是 0 了,說明這個客戶端已經不再持有鎖了,此時就會用:“del myLock”命令,從 Redis 里刪除這個 Key。
然后呢,另外的客戶端 2 就可以嘗試完成加鎖了。這就是所謂的分布式鎖的開源 Redisson 框架的實現機制。
一般我們在生產系統中,可以用 Redisson 框架提供的這個類庫來基于 Redis 進行分布式鎖的加鎖與釋放鎖。
上述 Redis 分布式鎖的缺點
上面那種方案***的問題,就是如果你對某個 Redis Master 實例,寫入了 myLock 這種鎖 Key 的 Value,此時會異步復制給對應的 Master Slave 實例。
但是這個過程中一旦發生 Redis Master 宕機,主備切換,Redis Slave 變為了 Redis Master。
接著就會導致,客戶端 2 來嘗試加鎖的時候,在新的 Redis Master 上完成了加鎖,而客戶端 1 也以為自己成功加了鎖。
此時就會導致多個客戶端對一個分布式鎖完成了加鎖。這時系統在業務語義上一定會出現問題,導致各種臟數據的產生。
所以這個就是 Redis Cluster,或者是 redis master-slave 架構的主從異步復制導致的 Redis 分布式鎖的***缺陷:在 Redis Master 實例宕機的時候,可能導致多個客戶端同時完成加鎖。
七張圖徹底講清楚 ZooKeeper 分布式鎖的實現原理
下面再給大家聊一下 ZooKeeper 實現分布式鎖的原理。同理,我是直接基于比較常用的 Curator 這個開源框架,聊一下這個框架對 ZooKeeper(以下簡稱 ZK)分布式鎖的實現。
一般除了大公司是自行封裝分布式鎖框架之外,建議大家用這些開源框架封裝好的分布式鎖實現,這是一個比較快捷省事兒的方式。
ZooKeeper 分布式鎖機制
接下來我們一起來看看,多客戶端獲取及釋放 ZK 分布式鎖的整個流程及背后的原理。
首先大家看看下面的圖,如果現在有兩個客戶端一起要爭搶 ZK 上的一把分布式鎖,會是個什么場景?
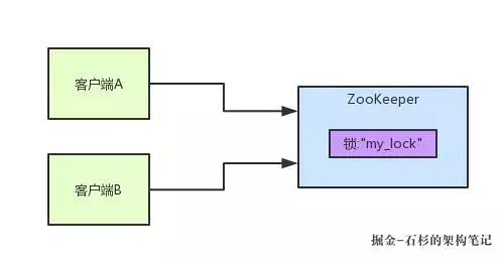
如果大家對 ZK 還不太了解的話,建議先自行百度一下,簡單了解點基本概念,比如 ZK 有哪些節點類型等等。
參見上圖。ZK 里有一把鎖,這個鎖就是 ZK 上的一個節點。然后呢,兩個客戶端都要來獲取這個鎖,具體是怎么來獲取呢?
咱們就假設客戶端 A 搶先一步,對 ZK 發起了加分布式鎖的請求,這個加鎖請求是用到了 ZK 中的一個特殊的概念,叫做“臨時順序節點”。
簡單來說,就是直接在"my_lock"這個鎖節點下,創建一個順序節點,這個順序節點有 ZK 內部自行維護的一個節點序號。
比如說,***個客戶端來搞一個順序節點,ZK 內部會給起個名字叫做:xxx-000001。
然后第二個客戶端來搞一個順序節點,ZK 可能會起個名字叫做:xxx-000002。
大家注意一下,***一個數字都是依次遞增的,從 1 開始逐次遞增。ZK 會維護這個順序。
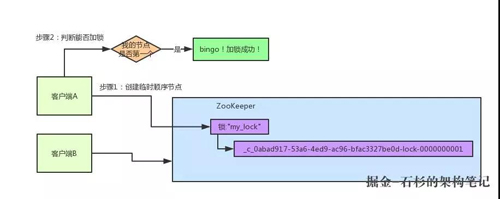
所以這個時候,假如說客戶端 A 先發起請求,就會搞出來一個順序節點,大家看下面的圖,Curator 框架大概會弄成如下的樣子:
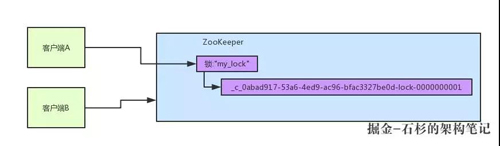
大家看,客戶端 A 發起一個加鎖請求,先會在你要加鎖的 node 下搞一個臨時順序節點,這一大坨長長的名字都是 Curator 框架自己生成出來的。
然后,那個***一個數字是"1"。大家注意一下,因為客戶端 A 是***個發起請求的,所以給他搞出來的順序節點的序號是"1"。
接著客戶端 A 創建完一個順序節點。還沒完,他會查一下"my_lock"這個鎖節點下的所有子節點,并且這些子節點是按照序號排序的,這個時候他大概會拿到這么一個集合:

接著客戶端 A 會走一個關鍵性的判斷,就是說:唉!兄弟,這個集合里,我創建的那個順序節點,是不是排在***個啊?
如果是的話,那我就可以加鎖了啊!因為明明我就是***個來創建順序節點的人,所以我就是***個嘗試加分布式鎖的人啊!
Bingo!加鎖成功!大家看下面的圖,再來直觀的感受一下整個過程:
接著假如說,客戶端 A 都加完鎖了,客戶端 B 過來想要加鎖了,這個時候他會干一樣的事兒:先是在"my_lock"這個鎖節點下創建一個臨時順序節點,此時名字會變成類似于:

大家看看下面的圖:

客戶端 B 因為是第二個來創建順序節點的,所以 ZK 內部會維護序號為"2"。
接著客戶端 B 會走加鎖判斷邏輯,查詢"my_lock"鎖節點下的所有子節點,按序號順序排列,此時他看到的類似于:
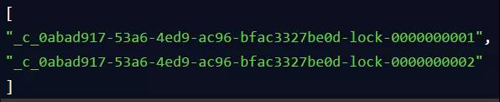
同時檢查自己創建的順序節點,是不是集合中的***個?明顯不是啊,此時***個是客戶端 A 創建的那個順序節點,序號為"01"的那個。所以加鎖失敗!
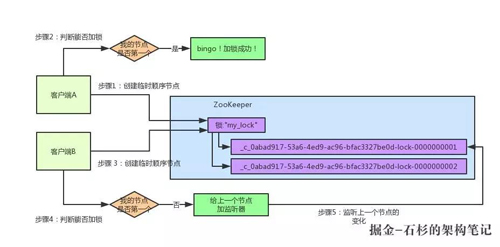
加鎖失敗了以后,客戶端 B 就會通過 ZK 的 API 對他的順序節點的上一個順序節點加一個監聽器。ZK 天然就可以實現對某個節點的監聽。
如果大家還不知道 ZK 的基本用法,可以百度查閱,非常的簡單。客戶端 B 的順序節點是:

他的上一個順序節點,不就是下面這個嗎?

即客戶端 A 創建的那個順序節點!所以,客戶端 B 會對

這個節點加一個監聽器,監聽這個節點是否被刪除等變化!大家看下面的圖:
接著,客戶端 A 加鎖之后,可能處理了一些代碼邏輯,然后就會釋放鎖。那么,釋放鎖是個什么過程呢?
其實很簡單,就是把自己在 ZK 里創建的那個順序節點,也就是:

這個節點給刪除。刪除了那個節點之后,ZK 會負責通知監聽這個節點的監聽器,也就是客戶端 B 之前加的那個監聽器,說:兄弟,你監聽的那個節點被刪除了,有人釋放了鎖。
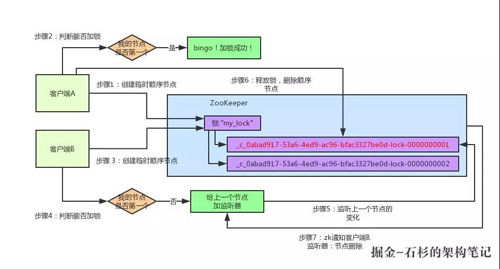
此時客戶端 B 的監聽器感知到了上一個順序節點被刪除,也就是排在他之前的某個客戶端釋放了鎖。
此時,就會通知客戶端 B 重新嘗試去獲取鎖,也就是獲取"my_lock"節點下的子節點集合,此時為:

集合里此時只有客戶端 B 創建的唯一的一個順序節點了!然后呢,客戶端 B 判斷自己居然是集合中的***個順序節點,Bingo!可以加鎖了!直接完成加鎖,運行后續的業務代碼即可,運行完了之后再次釋放鎖。
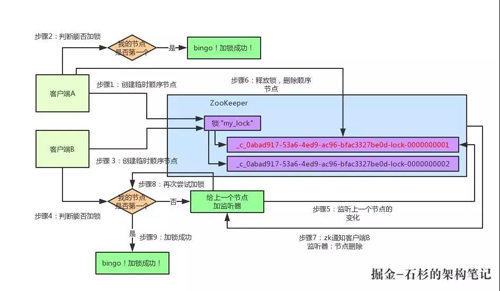
其實如果有客戶端 C、客戶端 D 等 N 個客戶端爭搶一個 ZK 分布式鎖,原理都是類似的:
- 大家都是上來直接創建一個鎖節點下的一個接一個的臨時順序節點。
- 如果自己不是***個節點,就對自己上一個節點加監聽器。
- 只要上一個節點釋放鎖,自己就排到前面去了,相當于是一個排隊機制。
而且用臨時順序節點的另外一個用意就是,如果某個客戶端創建臨時順序節點之后,不小心自己宕機了也沒關系,ZK 感知到那個客戶端宕機,會自動刪除對應的臨時順序節點,相當于自動釋放鎖,或者是自動取消自己的排隊。
***,咱們來看下用 Curator 框架進行加鎖和釋放鎖的一個過程:

其實用開源框架就是這點好,方便。這個 Curator 框架的 ZK 分布式鎖的加鎖和釋放鎖的實現原理,就是上面我們說的那樣子。
但是如果你要手動實現一套那個代碼的話。還是有點麻煩的,要考慮到各種細節,異常處理等等。所以大家如果考慮用 ZK 分布式鎖,可以參考下本文的思路。
每秒上千訂單場景下的分布式鎖高并發優化實踐
接著就給大家聊一個有意思的話題:每秒上千訂單場景下,如何對分布式鎖的并發能力進行優化?
首先,我們一起來看看這個問題的背景?前段時間有個朋友在外面面試,然后有一天找我聊說:有一個國內不錯的電商公司,面試官給他出了一個場景題:
假如下單時,用分布式鎖來防止庫存超賣,但是是每秒上千訂單的高并發場景,如何對分布式鎖進行高并發優化來應對這個場景?
他說他當時沒答上來,因為沒做過沒什么思路。其實我當時聽到這個面試題心里也覺得有點意思,因為如果是我來面試候選人的話,應該會給的范圍更大一些。
比如,讓面試的同學聊一聊電商高并發秒殺場景下的庫存超賣解決方案,各種方案的優缺點以及實踐,進而聊到分布式鎖這個話題。
因為庫存超賣問題是有很多種技術解決方案的,比如悲觀鎖,分布式鎖,樂觀鎖,隊列串行化,Redis 原子操作,等等吧。
但是既然那個面試官兄弟限定死了用分布式鎖來解決庫存超賣,我估計就是想問一個點:在高并發場景下如何優化分布式鎖的并發性能。
我覺得,面試官提問的角度還是可以接受的,因為在實際落地生產的時候,分布式鎖這個東西保證了數據的準確性,但是他天然并發能力有點弱。
剛好我之前在自己項目的其他場景下,確實是做過高并發場景下的分布式鎖優化方案,因此正好是借著這個朋友的面試題,把分布式鎖的高并發優化思路,給大家來聊一聊。
庫存超賣現象是怎么產生的?
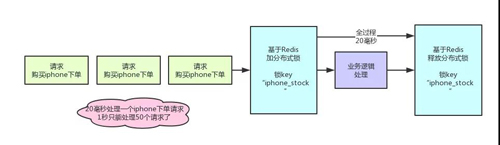
先來看看如果不用分布式鎖,所謂的電商庫存超賣是啥意思?大家看看下面的圖:
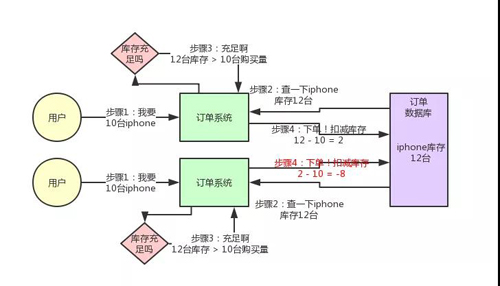
這個圖,其實很清晰了,假設訂單系統部署在兩臺機器上,不同的用戶都要同時買 10 臺 iPhone,分別發了一個請求給訂單系統。
接著每個訂單系統實例都去數據庫里查了一下,當前 iPhone 庫存是 12 臺。倆大兄弟一看,樂了,12 臺庫存大于了要買的 10 臺數量啊!
于是乎,每個訂單系統實例都發送 SQL 到數據庫里下單,然后扣減了 10 個庫存,其中一個將庫存從 12 臺扣減為 2 臺,另外一個將庫存從 2 臺扣減為 -8 臺。
現在完了,庫存出現了負數!淚奔啊,沒有 20 臺 iPhone 發給兩個用戶啊!這可如何是好。
用分布式鎖如何解決庫存超賣問題?
我們用分布式鎖如何解決庫存超賣問題呢?其實很簡單,回憶一下上次我們說的那個分布式鎖的實現原理:
同一個鎖 Key,同一時間只能有一個客戶端拿到鎖,其他客戶端會陷入***的等待來嘗試獲取那個鎖,只有獲取到鎖的客戶端才能執行下面的業務邏輯。
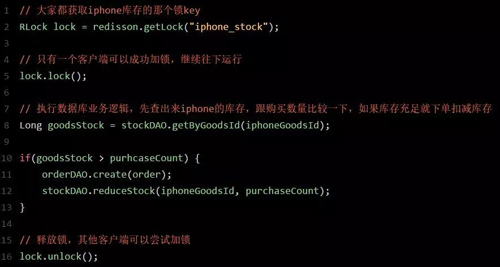
代碼大概就是上面那個樣子,現在我們來分析一下,為啥這樣做可以避免庫存超賣?
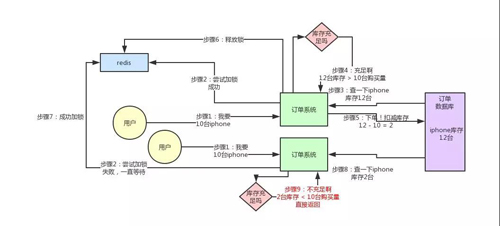
大家可以順著上面的那個步驟序號看一遍,馬上就明白了。
從上圖可以看到,只有一個訂單系統實例可以成功加分布式鎖,然后只有他一個實例可以查庫存、判斷庫存是否充足、下單扣減庫存,接著釋放鎖。
釋放鎖之后,另外一個訂單系統實例才能加鎖,接著查庫存,一下發現庫存只有 2 臺了,庫存不足,無法購買,下單失敗。不會將庫存扣減為 -8 的。
有沒其他方案解決庫存超賣問題?
當然有啊!比如悲觀鎖,分布式鎖,樂觀鎖,隊列串行化,異步隊列分散,Redis 原子操作,等等,很多方案,我們對庫存超賣有自己的一整套優化機制。
但是前面說過了,這篇文章就聊一個分布式鎖的并發優化,不是聊庫存超賣的解決方案,所以庫存超賣只是一個業務場景而已。
分布式鎖的方案在高并發場景下
好,現在我們來看看,分布式鎖的方案在高并發場景下有什么問題?
問題很大啊!兄弟,不知道你看出來了沒有。分布式鎖一旦加了之后,對同一個商品的下單請求,會導致所有客戶端都必須對同一個商品的庫存鎖 Key 進行加鎖。
比如,對 iPhone 這個商品的下單,都必對“iphone_stock”這個鎖 Key 來加鎖。這樣會導致對同一個商品的下單請求,就必須串行化,一個接一個的處理。
大家再回去對照上面的圖反復看一下,應該能想明白這個問題。
假設加鎖之后,釋放鎖之前,查庫存→創建訂單→扣減庫存,這個過程性能很高吧,算他全過程 20 毫秒,這應該不錯了。
那么 1 秒是 1000 毫秒,只能容納 50 個對這個商品的請求依次串行完成處理。
比如一秒鐘來 50 個請求,都是對 iPhone 下單的,那么每個請求處理 20 毫秒,一個一個來,*** 1000 毫秒正好處理完 50 個請求。
大家看一眼下面的圖,加深一下感覺。
所以看到這里,大家起碼也明白了,簡單的使用分布式鎖來處理庫存超賣問題,存在什么缺陷。
缺陷就是同一個商品多用戶同時下單的時候,會基于分布式鎖串行化處理,導致沒法同時處理同一個商品的大量下單的請求。
這種方案,要是應對那種低并發、無秒殺場景的普通小電商系統,可能還可以接受。
因為如果并發量很低,每秒就不到 10 個請求,沒有瞬時高并發秒殺單個商品的場景的話,其實也很少會對同一個商品在 1 秒內瞬間下 1000 個訂單,因為小電商系統沒那場景。
如何對分布式鎖進行高并發優化?
好了,終于引入正題了,那么現在怎么辦呢?
面試官說,我現在就卡死,庫存超賣就是用分布式鎖來解決,而且一秒對一個 iPhone 下上千訂單,怎么優化?
現在按照剛才的計算,你 1 秒鐘只能處理針對 iPhone 的 50 個訂單。其實說出來也很簡單,相信很多人看過 Java 里的 ConcurrentHashMap 的源碼和底層原理,應該知道里面的核心思路,就是分段加鎖!
把數據分成很多個段,每個段是一個單獨的鎖,所以多個線程過來并發修改數據的時候,可以并發的修改不同段的數據。不至于說,同一時間只能有一個線程獨占修改 ConcurrentHashMap 中的數據。
另外,Java 8 中新增了一個 LongAdder 類,也是針對 Java 7 以前的 AtomicLong 進行的優化,解決的是 CAS 類操作在高并發場景下,使用樂觀鎖思路,會導致大量線程長時間重復循環。
LongAdder 中也是采用了類似的分段 CAS 操作,失敗則自動遷移到下一個分段進行 CAS 的思路。
其實分布式鎖的優化思路也是類似的,之前我們是在另外一個業務場景下落地了這個方案到生產中,不是在庫存超賣問題里用的。
但是庫存超賣這個業務場景不錯,很容易理解,所以我們就用這個場景來說一下。
大家看看下面的圖:
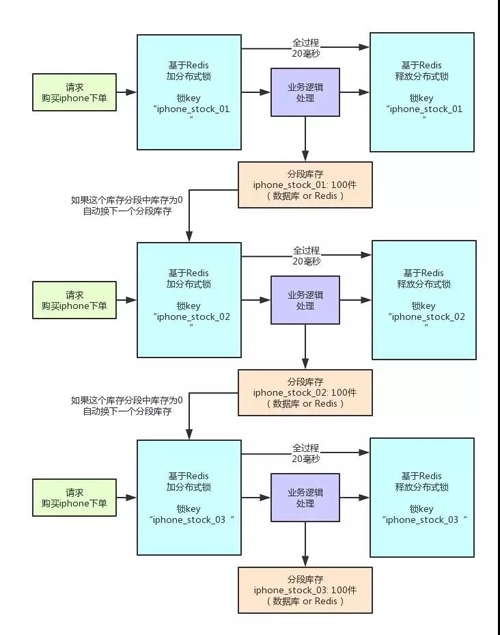
這就是分段加鎖。假如你現在 iPhone 有 1000 個庫存,那么你完全可以給拆成 20 個庫存段。
要是你愿意,可以在數據庫的表里建 20 個庫存字段,比如 stock_01,stock_02,類似這樣的,也可以在 Redis 之類的地方放 20 個庫存 Key。
總之,就是把你的 1000 件庫存給他拆開,每個庫存段是 50 件庫存,比如 stock_01 對應 50 件庫存,stock_02 對應 50 件庫存。
接著,每秒 1000 個請求過來了,好!此時其實可以是自己寫一個簡單的隨機算法,每個請求都是隨機在 20 個分段庫存里,選擇一個進行加鎖。
Bingo!這樣就好了,同時可以有最多 20 個下單請求一起執行,每個下單請求鎖了一個庫存分段,然后在業務邏輯里面,就對數據庫或者是 Redis 中的那個分段庫存進行操作即可,包括查庫存→判斷庫存是否充足→扣減庫存。
這相當于什么呢?相當于一個 20 毫秒,可以并發處理掉 20 個下單請求,那么 1 秒,也就可以依次處理掉 20 * 50 = 1000 個對 iPhone 的下單請求了。
一旦對某個數據做了分段處理之后,有一個坑大家一定要注意:就是如果某個下單請求,咔嚓加鎖,然后發現這個分段庫存里的庫存不足了,此時咋辦?
這時你得自動釋放鎖,然后立馬換下一個分段庫存,再次嘗試加鎖后嘗試處理。這個過程一定要實現。
分布式鎖并發優化方案有什么不足?
不足肯定是有的,***的不足,很不方便,實現太復雜了:
- 首先,你得對一個數據分段存儲,一個庫存字段本來好好的,現在要分為 20 個庫存字段。
- 其次,你在每次處理庫存的時候,還得自己寫隨機算法,隨機挑選一個分段來處理。
- ***,如果某個分段中的數據不足了,你還得自動切換到下一個分段數據去處理。
這個過程都是要手動寫代碼實現的,還是有點工作量,挺麻煩的。
不過我們確實在一些業務場景里,因為用到了分布式鎖,然后又必須要進行鎖并發的優化,又進一步用到了分段加鎖的技術方案,效果當然是很好的了,一下子并發性能可以增長幾十倍。
該優化方案的后續改進:以我們本文所說的庫存超賣場景為例,你要是這么玩,會把自己搞的很痛苦!再次強調,我們這里的庫存超賣場景,僅僅只是作為演示場景而已。
作者:中華石杉
中華石杉:十余年 BAT 架構經驗,一線互聯網公司技術總監。帶領上百人團隊開發過多個億級流量高并發系統。現將多年工作中積累下的研究手稿、經驗總結整理成文,傾囊相授。微信公眾號:石杉的架構筆記(ID:shishan100)。