詩人般的機器學習,ML工作原理大揭秘
機器學習使用數(shù)據(jù)中的模式來標記事物。聽起來好像很神奇,實際上核心概念相當簡單。
比如說標記事物,把酒分為好喝或者不好喝就是一個例子。這種標記不必想得太復(fù)雜,記得享受好喝的美酒就行啦~當然,如果你不喜歡喝酒,那無酒精的飲品可以了解一下→_ →
一、ML 工作原理
機器學習不是魔術(shù)。沒有數(shù)據(jù)就無法學習,因此我必須嘗一嘗。嘗過之后我給它一個「N」的標簽,N 代表「nope」,意思是「我們不要再試這個了。」這是我們?yōu)榭茖W做出的貢獻。
1. 數(shù)據(jù)
學習需要素材。想象一下我嘗了 50 種酒(為科學獻身!)并將其可視化。每種酒都有年限、評分及我們嘗試學習的正確答案:Y 代表「Yummy(好喝)」,N 代表「not-so-yummy(不怎么好喝)」。
據(jù)")
我品嘗了酒的味道并把它們的數(shù)據(jù)記錄在電子表格(左),但是我覺得以右圖的方式向你展示信息可能更友好。
2. 算法
選擇要使用的機器學習算法,就是在選我們要用到的「菜譜」。你要做的就是把紅色和藍色的事物分開,怎樣,沒問題吧?
如果你想畫一條線,那恭喜啦!你發(fā)明了一種叫「感知機」的 ML 算法。嗯,一個這么簡單的東西名字就是這么高大上!不要被機器學習里的術(shù)語給嚇住了,實際上很多東西沒有其名字那么復(fù)雜和厲害啦。

你會怎么把紅色和藍色的東西分開呢?
你的線要怎么畫?你應(yīng)該也能看出來,一條水平線不是什么聰明的解決方案。我們的目標是把 N 和 Y 分開來,而不是裝飾地平線。
機器學習算法的目的是在數(shù)據(jù)中選擇最合理的地方設(shè)置柵欄,而這要取決于數(shù)據(jù)點的位置。那要怎么做?答案是:優(yōu)化目標函數(shù)。
3. 優(yōu)化
我計劃專門寫個博客來講優(yōu)化問題,但目前先這么著想:目標函數(shù)就像是棋盤游戲的得分規(guī)則,優(yōu)化目標函數(shù)就是找出游戲的玩法,然后盡可能獲得***分。
目標函數(shù)(損失函數(shù))就像是棋盤游戲的得分系統(tǒng)。這張圖說明,大學時代我還沒有學會優(yōu)化問題……
通常在 ML 中,我們更喜歡大棒而不是胡蘿卜——分數(shù)是對錯誤的懲罰,而游戲規(guī)則是這些錯誤得分越少越好。這也是為什么在機器學習中目標函數(shù)被稱為「損失函數(shù)」,且目標是最小化損失。
想試試嗎?回到上面的分類圖,把你的手指水平放在屏幕上旋轉(zhuǎn),直到錯誤得分為零。
希望你找到的解決方案如下所示:
化")
來,先看圖片最左邊;簡單粗暴地畫一條水平線…中間的會更好一點,但還不是***的。我喜歡最右邊的方法。
4. 生活的調(diào)味品
如果你喜歡變化,那么你會愛上算法的。世界上有太多算法了,它們彼此之間的區(qū)別在于分割邊界時嘗試的位置不同。
「優(yōu)化狂魔」將告訴你以小的幅度旋轉(zhuǎn)柵欄(fence)是絕對不行的,有很多更好的方式可以更快速到達***位置。一些研究者竭盡全力嘗試結(jié)合多種方法在最短的距離內(nèi)到達***位置,不管地形(由輸入決定)變得如何反常。
多樣性的另一來源是邊界的形狀。柵欄不必是直線,不同的算法使用不同的柵欄。

當我們選擇這些復(fù)雜術(shù)語時,我們其實只是選擇了用來劃分標簽的邊界形狀。我們想用一條斜線分割樣本,還是很多水平/垂直的線或者靈活的曲線?可選擇的算法實在是太多了,分類邊界的形狀也各不相同。
5. 潮人喜歡的算法
現(xiàn)在,機器學習潮人都不喜歡直線。靈活的曲線在機器學習大潮中大受歡迎(即「神經(jīng)網(wǎng)絡(luò)」,盡管其實并沒有什么神經(jīng),這個名字是半個多世紀以前出現(xiàn)的,充滿了雄心壯志,似乎沒有人喜歡我的建議——將它們重命名為「瑜伽網(wǎng)絡(luò)」或「多層數(shù)學運算」)。
與其接受與線性算法和大腦神經(jīng)網(wǎng)絡(luò)的炒作性質(zhì)的對比,不如從柔術(shù)表演能力的角度來思考神經(jīng)網(wǎng)絡(luò)。其他方法在數(shù)學瑜伽方面略遜一籌。但是沒有什么東西是免費的,神經(jīng)網(wǎng)絡(luò)需要付出代價,因此不要相信任何人稱神經(jīng)網(wǎng)絡(luò)是***解決方案的說法。
神經(jīng)網(wǎng)絡(luò)或許也可以被稱為「瑜伽網(wǎng)絡(luò)」,其特殊能力在于能夠提供非常靈活的邊界。
那些專業(yè)的算法名稱告訴你它們將要用什么形狀的柵欄劃分輸入數(shù)據(jù)。如果你是一名應(yīng)用機器學習愛好者,不記住它們也沒問題,但在實踐中你需要將數(shù)據(jù)輸入到盡可能多的算法中,然后在看起來更有前途的算法上進行迭代。布丁的存在意義就在于吃,那么我們來吃吧~
即使翻閱了課本,你也很難一次就找到解決方案。別擔心。這不是個有一個正確答案的游戲,沒有人能一次就找到解決方案。你需要修補、嘗試并接著玩。留給設(shè)計新算法的研究人員一個問題:「它是如何工作的」。(你最終可能會熟悉這些名字,就像你了解困擾你的任何一部爛肥皂劇的角色一樣。)
6. 模型
一旦柵欄到位,算法就完成了,你從中得到的就是你想要的:一個模型,說白了就是一個「食譜」。現(xiàn)在有一些指令,讓電腦在下次看到一瓶新酒時用來將數(shù)據(jù)轉(zhuǎn)換成決策。如果數(shù)據(jù)落在藍色區(qū)域,就叫它藍色。落在紅色部分就叫它紅色。

7. 標注
一旦你把新鑄造的模型投入「薦酒」生產(chǎn)中,你就可以通過給電腦輸入年齡和評審分數(shù)來使用它,系統(tǒng)會查找出對應(yīng)的區(qū)域并輸出標簽。
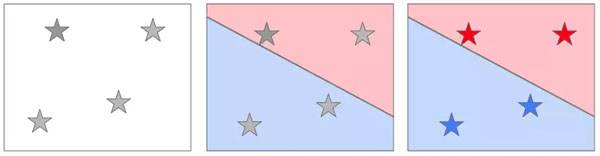
當我有四瓶新酒時,我只需將它們的輸入數(shù)據(jù)與「食譜」中的紅色和藍色區(qū)域進行匹配,并相應(yīng)地給它們貼上標簽。看到?jīng)]?這很容易!
我們怎么判斷它是否有效?檢查輸出!
通過運行一堆新數(shù)據(jù)來測試你的系統(tǒng),并確保它運行良好。不管是誰出的這種主意,跟著做就對了。
二、總結(jié)
以下,我另一篇文章為你提供了一份簡單直觀的總結(jié):
1. 詩人般的機器學習
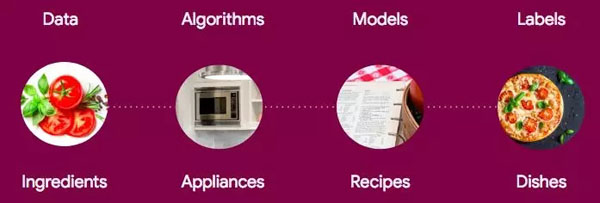
如果你還對機器學習感到困惑,那么可以試試這個類比:一位詩人選擇一種方法(或算法)將所有詞匯組合在紙上。這種方法決定了詩歌體裁(或決策邊界的形狀),這種體裁可能是三行俳句,也可能是十四行詩。一旦詩人完成了作品,即找到了將語句填充到十四行詩的***方法,現(xiàn)在完成的詩歌就相當于機器學習中的模型。
2. ML 模型 vs 傳統(tǒng)代碼
我想指出,機器學習模型和程序員通過評估問題而寫出代碼并手工制定規(guī)則的做法并不存在不可逾越的鴻溝。用非擬人化的語言來描述機器學習就是,模型在概念上和通常的代碼是相同的。
「隨著新樣本的輸入,重復(fù)運行算法來調(diào)整決策邊界」,這種說法會使你難以將機器學習和程序員的標準工作聯(lián)系起來。人類也可以隨新信息的獲取而調(diào)整代碼。
3. 這就是機器學習的全部嗎?
是的,機器學習工程方法真正困難的部分在于安裝軟件包,并對粗糙的數(shù)據(jù)集進行一系列炫酷的操作,這樣就相當于在數(shù)據(jù)上運行了一個非常復(fù)雜的算法。接下來是對代碼設(shè)定的***修改,請注意別讓高貴的名字「超參數(shù)調(diào)優(yōu)」迷惑了你。當你在新數(shù)據(jù)上評估模型的性能時,如果它的性能非常感人,那么你可能就需要重新設(shè)計方案并訓練。這一修正過程需要持續(xù)到獲得還能接受的效果,這也就是為什么機器學習工程師需要有良好的耐心。
機器學習不是魔術(shù)。機器學習能讓你寫出不能完全理解,但能自動地工作得很好的代碼。不要嫌棄它太簡單,杠桿也很簡單,但它能撬動整個地球。
原文鏈接:https://hackernoon.com/machine-learning-is-the-emperor-wearing-clothes-59933d12a3cc
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】