













什么是自注意力機制?
作者:KION KIM
機器之心編譯
參與:Geek AI、劉曉坤
注意力機制模仿了生物觀察行為的內部過程,即一種將內部經驗和外部感覺對齊從而增加部分區域的觀察精細度的機制。注意力機制可以快速提取稀疏數據的重要特征,因而被廣泛用于自然語言處理任務,特別是機器翻譯。而自注意力機制是注意力機制的改進,其減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性。本文通過文本情感分析的案例,解釋了自注意力機制如何應用于稀疏文本的單詞對表征加權,并有效提高模型效率。
目前有許多句子表征的方法。本文作者之前的博文中已經討論了 5 中不同的基于單詞表征的句子表征方法。想要了解更多這方面的內容,你可以訪問以下鏈接:
https://kionkim.github.io/(盡管其中大多數資料是韓文)
句子表征
在文本分類問題中,僅僅對句子中的詞嵌入求平均的做法就能取得良好的效果。而文本分類實際上是一個相對容易和簡單的任務,它不需要從語義的角度理解句子的意義,只需要對單詞進行計數就足夠了。例如,對情感分析來說,算法需要對與積極或消極情緒有重要關系的單詞進行計數,而不用關心其位置和具體意義為何。當然,這樣的算法應該學習到單詞本身的情感。
循環神經網絡
為了更好地理解句子,我們應該更加關注單詞的順序。為了做到這一點,循環神經網絡可以從一系列具有以下的隱藏狀態的輸入單詞(token)中抽取出相關信息。
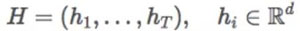
當我們使用這些信息時,我們通常只使用***一個時間步的隱藏狀態。然而,想要從僅僅存儲在一個小規模向量中的句子表達出所有的信息并不是一件容易的事情。
卷積神經網絡
借鑒于 n-gram 技術的思路,卷積神經網絡(CNN)可以圍繞我們感興趣的單詞歸納局部信息。為此,我們可以應用如下圖所示的一維卷積。當然,下面僅僅給出了一個例子,我們也可以嘗試其它不同的架構。

大小為 3 的一維卷積核掃描我們想要歸納信息的位置周圍的單詞。為此,我們必須使用大小為 1 的填充值(padding),從而使過濾后的長度保持與原始長度 T 相同。除此之外,輸出通道的數量是 c_1。
接著,我們將另一個過濾器應用于特征圖,最終將輸入的規模轉化為 c_2*T。這一系列的過程實在模仿人類閱讀句子的方式,首先理解 3 個單詞的含義,然后將它們綜合考慮來理解更高層次的概念。作為一種衍生技術,我們可以利用在深度學習框架中實現的優化好的卷積神經網絡算法來達到更快的運算速度。
關系網絡
單詞對可能會為我們提供關于句子的更清楚的信息。實際情況中,某個單詞往往可能會根據其不同的用法而擁有不同的含義。例如,「I like」中的單詞「like」(喜歡)和它在「like this」(像... 一樣)中的含義是不同的。如果我們將「I」和「like」一同考慮,而不是將「like」和「this」放在一起考慮,我們可以更加清楚地領會到句子的感情。這絕對是一種積極的信號。Skip gram 是一種從單詞對中檢索信息的技術,它并不要求單詞對中的單詞緊緊相鄰。正如單詞「skip」所暗示的那樣,它允許這些單詞之間有間隔。

正如你在上圖中所看到的,一對單詞被輸入到函數 f(⋅) 中,從而提取出它們之間的關系。對于某個特定的位置 t,有 T-1 對單詞被歸納,而我們通過求和或平均或任意其它相關的技術對句子進行表征。當我們具體實現這個算法時,我們會對包括當前單詞本身的 T 對單詞進行這樣的計算。
需要一種折衷方法
我們可以將這三種不同的方法寫作同一個下面的通用形式:
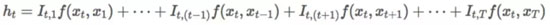
當所有的 I_{t,⋅} 為 1 時,通用形式說明任何「skip bigram」對于模型的貢獻是均勻的。
對于 RNN 來說,我們忽略單詞 x_t 之后的所有信息,因此上述方程可以化簡為:
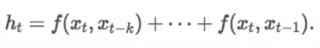
對于雙向 RNN 來說,我們可以考慮從 x_T 到 x_t 的后向關系。
另一方面,CNN 只圍繞我們感興趣的單詞瀏覽信息,如果我們只關心單詞 x_t 前后的 k 個單詞,通用的公式可以被重新排列為:
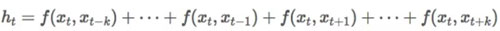
盡管關系網絡可能過于龐大,以至于我們不能考慮所有單詞對關系。而 CNN 的規模又太小了,我們不能僅僅考慮它們之間的局部關系。所以,我們需要在這兩個極端之間找到一種折衷的方式,這就是所謂的注意力機制。
自注意力機制
上文提到的通用形式可以被重新改寫為下面更加靈活的形式:
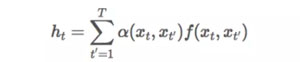
在這里,α(⋅,⋅) 控制了每個單詞組合可能產生的影響。例如,在句子「I like you like this」中,兩個單詞「I」和「you」可能對于確定句子的情感沒有幫助。然而,「I」和「like」的組合使我們對這句話的情感有了一個清晰的認識。在這種情況下,我們給予前一種組合的注意力很少,而給予后一種組合的注意力很多。通過引入權重向量 α(⋅,⋅),我們可以讓算法調整單詞組合的重要程度。
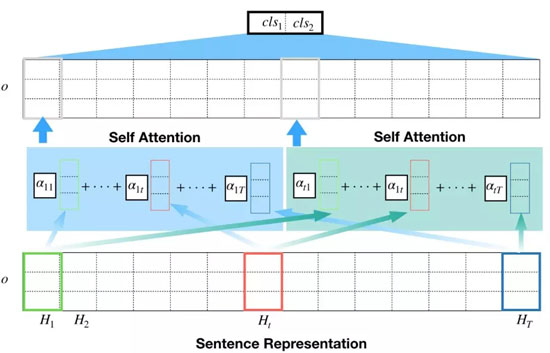
假設第 i 個句子中的 T 個單詞被嵌入到了 H_{i1},…,H_{iT} 中,每個詞嵌入都會被賦予一個權重 α_{it},它代表了將單詞歸納到一個統一的表征中時的相對重要性。
我們在這里想要擁有的最終結果是每個輸入句子的權重矩陣。如果我們把 10 個句子輸入到網絡中,我們會得到 10 個如下所示的注意力矩陣。
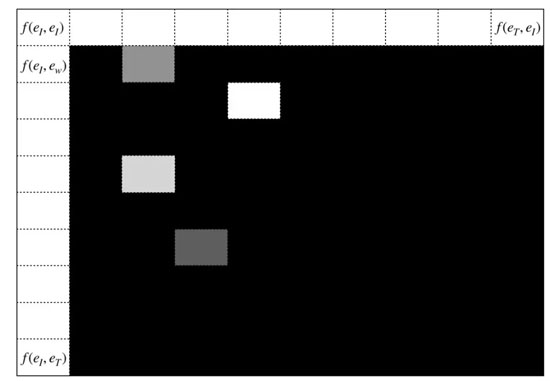
自注意力機制的實現
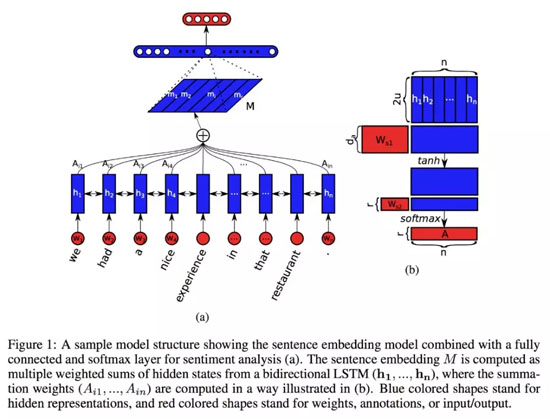
自注意力機制在論文「A structured Self-Attentive Sentence Embedding」中被***提出,此文作者將自注意力機制應用于雙向 LSTM 的隱層,模型結構如下圖所示:
論文地址:https://arxiv.org/pdf/1703.03130.pdf
然而,我們并不一定要用 LSTM 來做單詞表征(并不一定是單詞表征,我的意思是句子表征之前的階段),我們將把自注意力機制應用到基于關系網絡的單詞表征中。
與原論文中的自注意力機制不同(如上圖所示,數學上的細節可以在我的上一篇博文中找到),關系網絡的注意力機制可以被定義為:
參見:
https://kionkim.github.io/_posts/2018-07-12-sentiment_analysis_self_attention.md
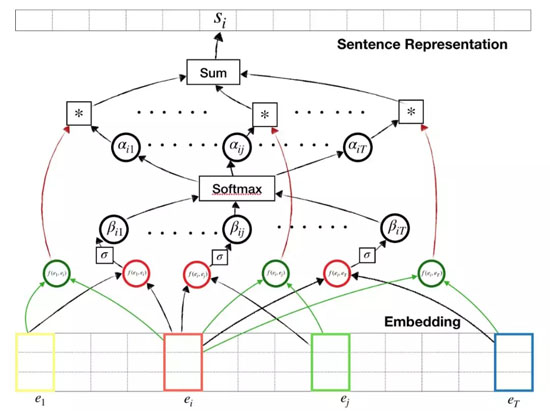
為了解釋上面的圖標,不妨假設我們想要得到第 i 個單詞的表征。對于包含第 i 個單詞的單詞組合,會生成兩個輸出:一個用于特征提取(綠色圓圈),另一個用于注意力加權(紅色圓圈)。這兩個輸出可能共享同一個網絡,但在本文中,我們為每個輸出使用單獨的網絡。在得到***的注意力權重之前,注意力(紅色圓圈)的輸出通過需要經過 sigmoid 和 softmax 層的運算。這些注意力權重會與提取出的特征相乘,以得到我們感興趣的單詞的表征。
用 Gluon 實現 自注意力機制
在具體實現部分,我們假設網絡結構十分簡單,有兩個相連的全連接層用于關系提取,有一個全連接層用于注意力機制。緊跟著是兩個相連的全連接層用于分類。在這里,關系提取和注意力提取會用到下面的代碼片段:
- class Sentence_Representation(nn.Block):
- def __init__(self, **kwargs):
- super(Sentence_Representation, self).__init__()
- for (k, v) in kwargs.items():
- setattr(self, k, v)
- with self.name_scope():
- self.embed = nn.Embedding(self.vocab_size, self.emb_dim)
- self.g_fc1 = nn.Dense(self.hidden_dim,activation='relu')
- self.g_fc2 = nn.Dense(self.hidden_dim,activation='relu')
- self.attn = nn.Dense(1, activation = 'tanh')
- def forward(self, x):
- embeds = self.embed(x) # batch * time step * embedding
- x_i = embeds.expand_dims(1)
- x_i = nd.repeat(x_i,repeats= self.sentence_length, axis=1) # batch * time step * time step * embedding
- x_j = embeds.expand_dims(2)
- x_j = nd.repeat(x_j,repeats= self.sentence_length, axis=2) # batch * time step * time step * embedding
- x_full = nd.concat(x_i,x_j,dim=3) # batch * time step * time step * (2 * embedding)
- # New input data
- _x = x_full.reshape((-1, 2 * self.emb_dim))
- # Network for attention
- _attn = self.attn(_x)
- _att = _attn.reshape((-1, self.sentence_length, self.sentence_length))
- _att = nd.sigmoid(_att)
- att = nd.softmax(_att, axis = 1)
- _x = self.g_fc1(_x) # (batch * time step * time step) * hidden_dim
- _x = self.g_fc2(_x) # (batch * time step * time step) * hidden_dim
- # add all (sentence_length*sentence_length) sized result to produce sentence representation
- x_g = _x.reshape((-1, self.sentence_length, self.sentence_length, self.hidden_dim))
- _inflated_att = _att.expand_dims(axis = -1)
- _inflated_att = nd.repeat(_inflated_att, repeats = self.hidden_dim, axis = 3)
- x_q = nd.multiply(_inflated_att, x_g)
- sentence_rep = nd.mean(x_q.reshape(shape = (-1, self.sentence_length **2, self.hidden_dim)), axis= 1)
- return sentence_rep, att
我們將為特征提取和注意力機制運用獨立的網絡。最終得到的注意力向量的規模為 T*1,提取出的特征向量的規模為 T*d,其中 d 為超參數。為了將二者相乘,我們只需要將注意力向量擴展到與提取出的特征向量的規模相匹配。我們在這里提供的只是一個小例子,其它的實現可能會更好。
完整的實現代碼可以從以下鏈接獲得:
http://210.121.159.217:9090/kionkim/stat-analysis/blob/master/nlp_models/notebooks/text_classification_RN_SA_umich.ipynb。
結果
下面是 9 個隨機選擇的注意力矩陣:
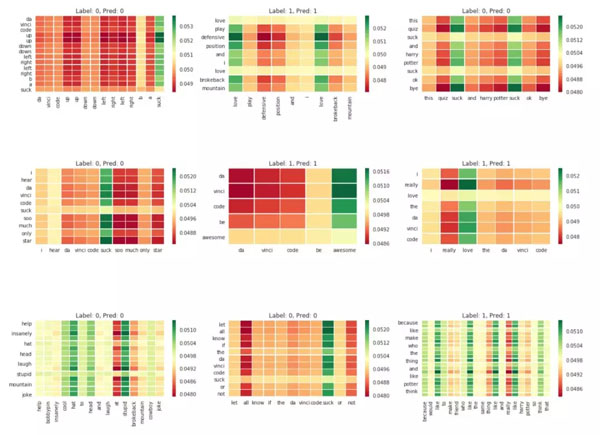
當對文本進行分類時,我們可以知道算法將把注意力放在那些單詞上。正如預期的那樣,在分類過程中,「love」、「awesome」、「stupid」、「suck」這樣表達情感的單詞受到了重點關注。
參考鏈接:https://medium.com/@kion.kim/self-attention-a-clever-compromise-4d61c28b8235
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】



























