一分鐘理解Redo Undo
作者:邢森
數據庫中有一種特殊的“日志文件”叫Redo(重做) Undo(撤銷),Reod/Undo文件是數據庫的一部分,主要用于數據恢復,保證數據的一致性和完整性。
數據庫中有一種特殊的“日志文件”叫 Redo(重做) Undo(撤銷),傳統意義上的日志文件是記錄系統運行狀態的,主要用于系統工程師或者程序員排錯。而 Reod/Undo 文件是數據庫的一部分,主要用于數據恢復,保證數據的一致性和完整性。

用途
當執行 Insert、Update、Delete 動作時數據庫不會真的去數據文件中執行 I/O 操作,而是分了兩部分:
- 修改內存中的數據(數據庫稱為 Buffer)
- 記錄 Redo Undo 日志
只有當 Buffer 達到刷新條件(比如臟數據達到一定比例)才會對數據文件進行操作。數據庫這么設計是出于性能考慮,因為讀寫數據文件是一次隨機 I/O 會降低系統性能;雖然 Redo Undo 也會寫文件,但它是順序寫入,性能比較高。
這種順序寫入一般采用 LSM (Log Structured Merge Trees)算法,比如 Kafka,HBase、LevelDB 都采用這種結構。
因為數據并沒有真正的寫入數據文件,所以當數據庫系統崩潰后(比如斷電、系統重啟、介質錯誤),數據庫系統會利用Redo、Undo 恢復數據。
如何恢復
兩個原則
- 從前向后讀取 Redo,重做所有已提交的事務
- 從后往前讀取 Undo,回滾未提交的事務
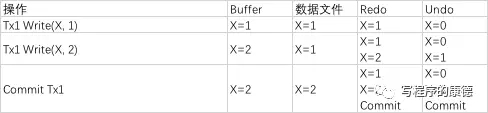
以上面操作為例,假設故障點發生在***個 Write 之后。
數據庫啟動后讀取 Redo 文件沒有發現已經提交的事務,什么也不做;讀取 Undo 文件發現未提交的事務,恢復 X=0(假設 X 歷史值為 0)。
- 假設故障點發生在第二個 Write 之后:數據庫啟動后讀取 Redo 文件發現沒有已經提交的事務,什么也不做;讀取 Undo 文件發現未提交的事務,恢復 X=1,繼續回滾X=0。
- 假設故障點發生在 Commit 之后:數據庫啟動后讀取 Redo 文件發生已經提交的事務,執行 X=1,然后 X=2;讀取 Undo 文件發現提交事務,什么也不做。
多個事務也是如此,讀者可以自行嘗試枚舉。
【本文是51CTO專欄作者“邢森”的原創文章,轉載請聯系作者本人獲取授權】
責任編輯:趙寧寧
來源:
51CTO專欄