一分鐘搞懂HBase
什么是HBase?
HBase(Hadoop Database)是Apache的Hadoop項目的子項目,是一個分布式的、面向列的開源數據庫,就像Bigtable利用了Google文件系統(GFS)所提供的分布式數據存儲一樣,HBase在Hadoop之上提供了類似于Bigtable的能力。
為什么采用HBase?
HBase不同于一般的關系數據庫,它是一個適合于非結構化數據存儲的數據庫,HBase是介于Map Entry(key & value)和DB Row之間的一種數據存儲方式,有點類似于現在流行的Memcache,但不僅僅是簡單的一個key對應一個 value,你還可以根據需要存儲多個屬性的數據結構,但沒有傳統數據庫表中那么多的關聯關系,這就是所謂的松散數據。
簡單來說,你在HBase中創建的表可以看做是一張很大的表,而這個表的屬性可以根據需求去動態增加,在HBase中沒有表與表之間關聯查詢。你只需要告訴你的數據存儲到HBase表的哪個column families 就可以了,不需要指定它的具體類型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事務此類的功能。
Apache HBase 和Google Bigtable 有非常相似的地方,一個數據行擁有一個可選擇的鍵和任意數量的列。表是疏松的存儲的,因此用戶可以給行定義各種不同的列,對于這樣的功能在大項目中非常實用,可以簡化設計和升級的成本。
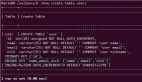
HBase與傳統RDBMS的區別

應用場景
有時候了解軟件產品的***方法是看看它是怎么用的。它可以解決什么問題和這些解決方案如何適用于大型應用架構,能夠告訴你很多。因為HBase有許多公開的產品部署,我們正好可以這么做。本章節將詳細介紹一些人們成功使用HBase的使用場景。
注意:不要自我限制,認為HBase只能解決這些使用場景。它是一個初生的技術,根據使用場景進行創新正驅動著系統的發展。如果你有新想法,認為可以受益于HBase提供的功能,試試吧。社區很樂于幫助你,也會從你的經驗中學習。這正是開源軟件精神。
互聯網搜索應用
BigTable,和模仿出來的HBase,為這種文檔庫提供存儲,BigTable提供行級訪問,所以爬蟲可以插入和更新單個文檔。搜索索引可以基于BigTable 通過MapReduce計算高效生成。
捕獲增量數據
數據通常是細水長流,累加到已有數據庫以備將來使用,例如分析,處理和服務。許多HBase使用場景屬于這個類別—使用HBase作為數據存儲,捕獲來自于各種數據源的增量數據。例如,這種數據源可能是網頁爬蟲(我們討論過的互聯網搜索應用問題),可能是記錄用戶看了什么廣告和多長時間的廣告效果數據,也可能是記錄各種參數的時間序列數據。
半結構化或非結構化數據
對于數據結構字段不夠確定或雜亂無章很難按一個概念去進行抽取的數據適合用HBase。例如,當業務發展需要存儲用戶的email,phone,address信息時RDBMS需要停機維護,而HBase支持動態增加。
記錄非常稀疏
RDBMS的行有多少列是固定的,為null的列浪費了存儲空間。HBase為null的Column不會被存儲,這樣既節省了空間又提高了讀性能。
多版本數據
根據Row key和Column key定位到的Value可以有任意數量的版本值,因此對于需要存儲變動歷史記錄的數據,用HBase就非常方便了。比如用戶表的address是會變動的,業務上一般只需要***的值,但有時可能需要查詢到歷史值。
超大數據量
當數據量越來越大,RDBMS數據庫撐不住了,就出現了讀寫分離策略,通過一個Master專門負責寫操作,多個Slave負責讀操作,服務器成本倍增。
隨著壓力增加,Master撐不住了,這時就要分庫了,把關聯不大的數據分開部署,一些join查詢不能用了,需要借助中間層。
隨著數據量的進一步增加,一個表的記錄越來越大,查詢就變得很慢,于是又得搞分表,比如按ID取模分成多個表以減少單個表的記錄數。經歷過這些事的人都知道過程是多么的折騰。
采用HBase就簡單了,只需要加機器即可,HBase會自動水平切分擴展,跟Hadoop的無縫集成保障了其數據可靠性(HDFS)和海量數據分析的高性能(MapReduce)。
【本文為51CTO專欄作者“朱國立”的原創稿件,轉載請通過作者微信公眾號“開發者圓桌”獲取聯系和授權】