













Baidu Create 2018深度學習前沿技術與工業應用公開課精彩回顧
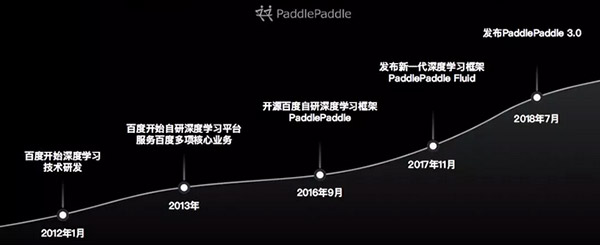
原創【51CTO.com原創稿件】中國開發者們的年度盛會——百度AI開發者大會于近日落下帷幕。百度在深度學習領域的技術研發始于2012年初,一年后,百度在深度學習平臺領域已取得初步成功,并將其應用于百度的多項核心業務。
百度深度學習框架PaddlePaddle自2016年開源以來,受到了業界的廣泛關注,已經成為全球發展熱度增速最高的開源深度學習平臺,PaddlePaddle社區更是匯集了一大批AI技術開發者。開源的模式使PaddlePaddle在近兩年取得了快速發展和升級,2017年11月百度發布了更細粒度的新一代深度學習框架——PaddlePaddleFluid,今年7月發布了PaddlePaddle3.0,這些相繼印證了百度在深度學習領域的雄厚實力。
實際上,無人車、智能家電、AI云、AlphaGo等常見的AI應用領域,都離不開深度學習框架的訓練和預測服務,深度學習框架則相當于AI時代的操作系統,在AI領域扮演者至關重要的角色。本次大會中,深度學習框架PaddlePaddle備受開發者們的關注,深度學習前沿技術與工業應用公開課分論壇現場座無虛席,開發者們擠爆全場,不少參會者甚至坐在地上聽完全部課程。
為滿足現場觀眾對前沿技術的渴求,本次公開課在每輪演講結束后特意設置了多輪問答環節,與會嘉賓積極踴躍地提問,涉及到實操性的問題時更是連翻追問,百度的專家講師團紛紛給出了耐心詳細的解答,會后參會者們紛紛表示受益頗豐。
本次公開課的課程內容涉及到深度學習領域的方方面面,包括深度學習的語義計算技術,百度視覺技術、OCR遷移至Paddle-Fluid版本的工程實例,PaddlePaddle的新特性,大規模稀疏數據分布式模型訓練,移動端深度學習技術及應用實踐,深度學習預測引擎Anakin的優化,以及深度學習的可視化等,小編梳理了本屆開發者大會中百度專家講師們的最新研究及實踐成果,讓我們一睹為快吧。
深度學習公開課現場的一角:坐在地上的小伙伴們
百度自主研發的深度學習框架PaddlePaddle
基于深度學習的語義計算技術
百度產品中常見的語義匹配場景包括百度搜索、百度Feed流以及百度拍照搜索等,分別實現問題與答案匹配、用戶與新聞匹配、圖片與文本匹配的效果。
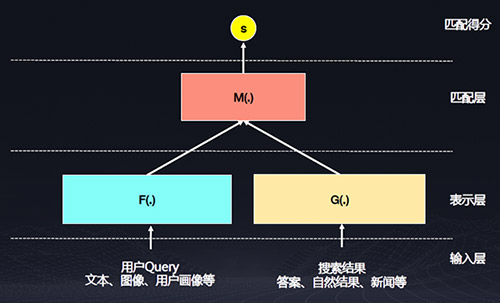
語義匹配模型包括輸入層、表示層、匹配層和匹配得分四層。

其中表示層需要完成輸入數據轉化為數值向量的過程。
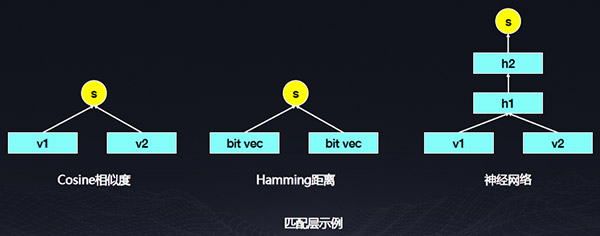
匹配層需要完成兩個向量融合并產生打分的過程,表示層和匹配層都可以是一個深度神經網絡。
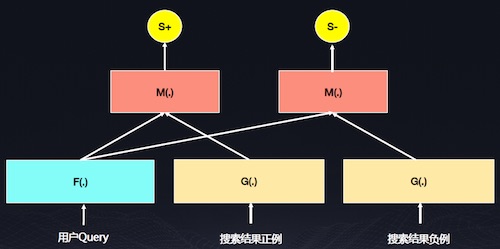
上圖是百度常見的訓練模型,百度擁有海量的用戶行為日志,包括點擊行為和非點擊行為,這些行為通常暗示一種語義關系,點擊行為的語義更相關,因此要從海量的用戶行為日志信息中挖掘樣本,提取高質量弱標記數據,將語義相關的數據作為正例,語義不太相關的數據作為負例,Query和正例的打分比Query和負例的打分大,使𝑺↓+ − 𝑺↓−> 𝝈,通過定義目標函數來優化神經網絡的參數。
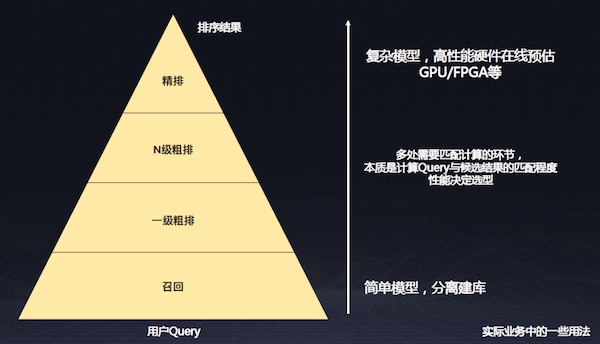
由于召回端有非常多的結果,如果用復雜的神經網絡模型來計算匹配度,系統很難承受,因此可以在召回層對Query做向量表示,將這個表示離線的計算出來,可以大大減少計算開銷。在精排階段,在結果很少的情況下可使用GPU做復雜的模擬計算,也就是在匹配層進行復雜計算。
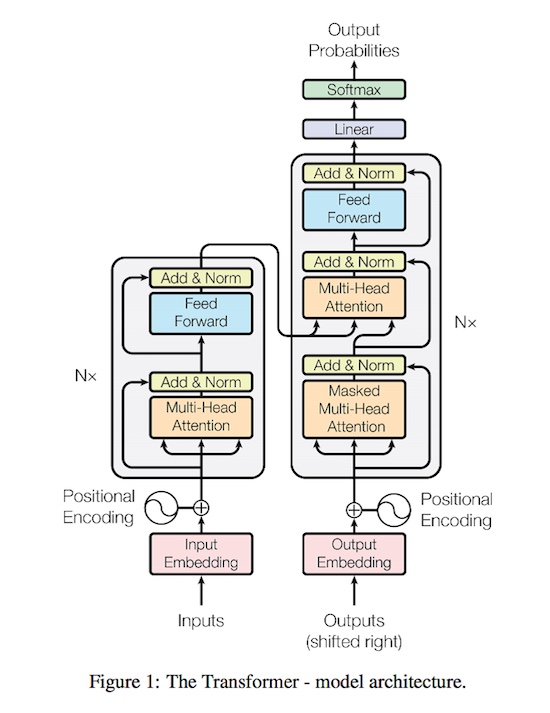
流行的Encoder, Decoder算法組件, Transformer:下載鏈接
接下來舉一個文本生成的例子。我們常用的機器翻譯模型,其目標是把原語言通過神經網絡建模翻譯成目標語言,目前學術界對翻譯模型的抽象都是基于編碼器和解碼器兩個階段的建模方法。基于用戶輸入的原語言做Decoder編碼,然后對Decoder的詞做最大化的測量估計,在機器翻譯的解碼過程中,通常對用戶輸入的語言做原語言的編碼,通過Beam Search的方法找到最大可能的翻譯的結果。Transformer是近兩年比較常用的、效果和速度都比較好的模型,感興趣的開發者不妨跑一跑。

語言模型是自然語言處理中比較經典的問題,其目標是學習一個詞序列的聯合概率函數,也就是說這個句子是否常見。如世界杯期間,在百度搜索中搜“阿根廷在”這四個字,“阿根廷在哪個組”這個Query的概率較大。
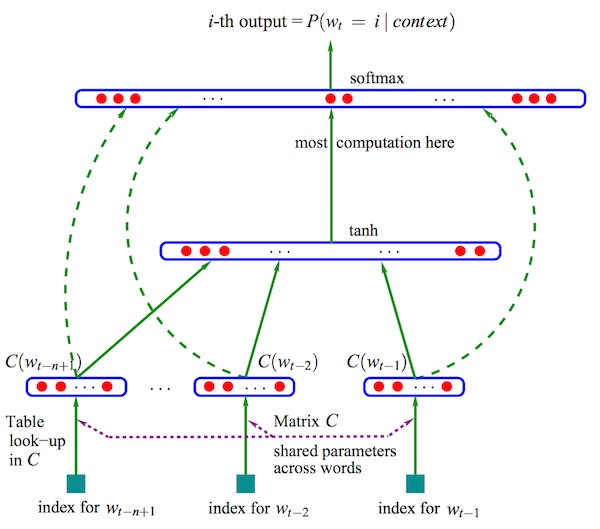
Neural Network Language Model. Bengio. 2003
上圖是神經網絡中較常見的Neural Network Language Model,它是用神經網絡做語言模型的比較常見的模型。
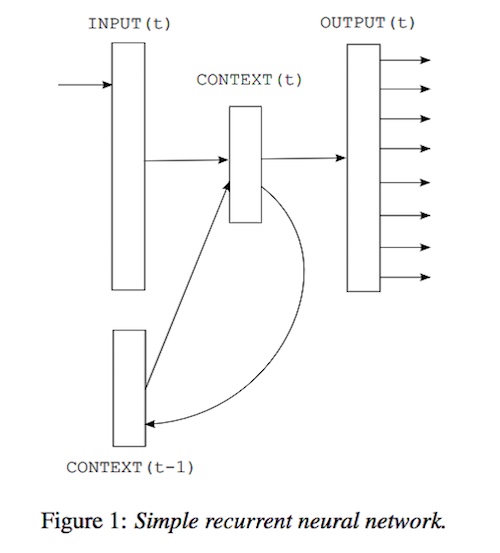
上圖是一個循環神經網絡,它會不斷融合歷史和當前的信息,因此也是作為語言模型比較常見的侯選。
接下來介紹一下百度賣方的NLP的計算服務,在ai.baidu.com網站有很多基于深度學習訓練的NLP模型的可調用服務,包括DNN語言模型、詞法分析、短文本相似度、中文情感分析等。百度在NLP方面開源了一些基于PaddlePaddle的項目,如NLP里的中文詞法分析,開源了整個模型訓練的配置,以及部署的方法,其中基于深度學習網絡,融合了切詞、標注,以及專名識別,是三個任務融合為一體的一個開源項目。
PaddlePaddle應用于百度視覺技術的工程實踐
百度的AI視覺技術主要包括四個方面:圖像識別、圖像搜索、視頻理解和機器人視覺。五年前百度已開始將機器人視覺全面轉向深度學習技術,這些技術大量應用于百度內部和外部的各種業務。
圖像識別是把圖像生成文本標簽,包括通用分類,百度內部主要的分類模型有文字識別、人臉識別,以及醫療圖像、圖像審核和一些細粒度分類等一些特定領域的應用,圖像識別主要使用CNN的分類技術。
圖像檢索是用深度學習定義圖像和圖像之間的關系,圖像檢索主要應用于百度識圖,包括圖文檢索、相同圖片檢索,相似圖片檢索以及商品圖片檢索等功能。
視頻理解用于視頻分類、視頻標簽等,也大量應用于監控場景下的目標跟蹤、人體姿態跟蹤等。在小視頻帶來的新型市場環境下,視頻理解技術大量應用于百度內部的業務場景中。
機器人視覺主要用于一些工業場景,包括深度傳感器、SLAM、嵌入式視覺等,使用大量的嵌入式的技術。
據現場專家的介紹,這些AI視覺技術已經開放,同時百度還會不斷通過新的數據進行持續迭代,提供更加優質的服務。
進行視覺技術研發的挑戰
百度內部有上百個模型同時使用,每天會不斷產生新的數據,模型迭代需要解決的問題主要有三個方面:一是如何評價對比模型,然后才能選擇最優的模型結構或優化策略;二是如何快速經濟的訓練(復現)這些模型;三是如何沉淀工程和算法經驗,供大家共同使用。百度視覺技術研發的目標是使得機器學習流程化、標準化,構建模型持續快速迭代能力。
接下來介紹一下百度是如何基于PaddlePaddle解決上述問題的。
基于PaddlePaddle的模型研發
百度內部有兩種模型的研發,一是基線模型,是一些基礎的視覺問題,如圖像分類、圖像檢測、圖像跟蹤等,百度將這些問題定義為一個基本的機器學習問題。另一種是業務模型,就是針對業務場景、業務需求來收集數據,訓練模型。這兩種場景下采用不同的方式,使模型的比較和模型的復現更加容易。
自2017年PaddlePaddle發布Fluid版本后,基線模型研發統一采用開源的方式實現,并且通過開源社區提交基線模型的訓練代碼和文檔等研究成果,它的好處在于可以把機器學習的各個步驟進行標準化,包括將訓練框架統一到PaddlePaddle的最新版本,數據讀取、預處理、網絡定義、優化參數等接口均實現標準化,便于模型對比。
PaddlePaddle的技術支持
1、PaddlePaddle提供標準的符合論文實現的operator實現;
2、通過PaddlePaddle實現統一的訓練方式,保證單機單卡、單機多卡、多機多卡訓練效率和收斂一致性;
3、基于開源社區開發新的視覺相關operator。
Paddle-Cloud 集群訓練
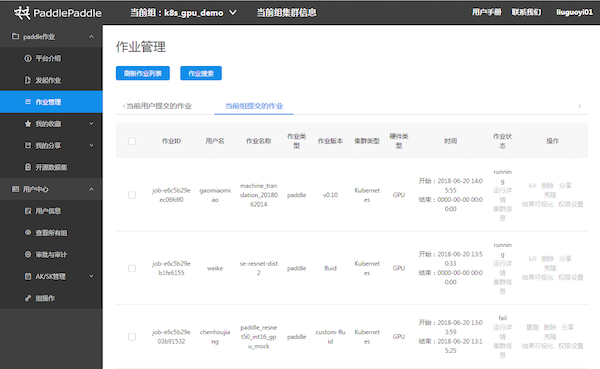
Paddle-Cloud平臺的作業管理
百度內部基于PaddlePaddle有一個較好的實現模型快速迭代的Paddle-Cloud平臺,基于Kubernetes資源調度、隊列管理、用戶管理等于一身,可管理模型訓練,可統一管理訓練配置,提供Visual-DL的支持。在數據讀取方面,Paddle-Cloud平臺上實現了統一的數據讀取、數據倉庫的直讀,保證可以從原始數據直接復現業務模型。此外,訓練模型可以經過平臺訓練,直接存儲在模型倉庫中,跟存儲打通。
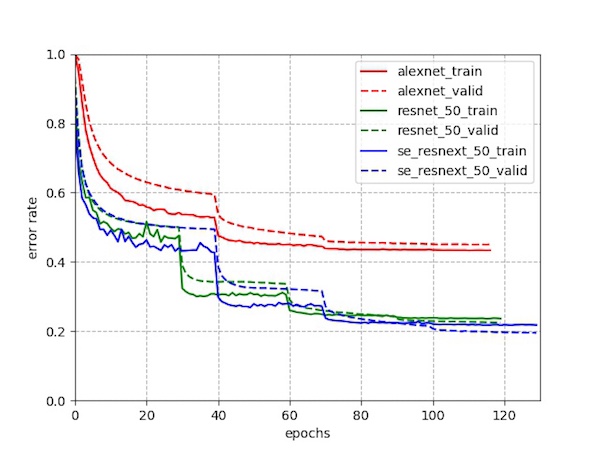
示例:圖像分類模型的論文結果復現——復現標準的分類模型
示例:圖像分類模型的論文結果復現——搭建過程
視覺模塊:已發布Paddle視覺模型
• 圖像分類:image_classification
• 人臉檢測:face_detection
• OCR識別:ocr_recognition
• 目標檢測:object_detection
• 模型轉換:image_classification/caffe2fluid
視覺模塊:開發中的視覺模型
• 圖像特征學習
• OCR end2end
• 定點化訓練
未來會發布更多自研模型
• 人臉檢測: 2018 WiderFace 第一名
• 大規模分類: 2018 Webvision 第一名
• 視頻識別: 2018 ActivityNet 第一名
工程示例:OCR Paddle-v1 遷移到Paddle-Fluid
下面重點介紹一下OCR的工程示例,OCR于三年前開始使用Paddle-V1版本進行識別模型訓練,由于V1版本已不是主流的維護版本,因此要將OCR升級到最新的Fluid的版本,把訓練統一遷移到內部的Paddle-Cloud集群,與此同時,百度一些優化的預測庫也可以應用到最新的OCR預測中。
在此背景下,百度在開源社區成立了Paddle-vision聯合項目組,并在遷移的過程中實現了模型研發、訓練遷移和預測遷移三大目標。
在模型遷移的過程中,項目組將Paddle的一些特殊OP用Fluid的版本進行打平,驗證了Paddle-Fluid版本的前向網絡和Paddle-V1的一致性,同時也驗證了新版本的訓練效果。Fluid版本與舊版本Paddle對齊了模型訓練指標,通過對比多種優化方法和學習率動態調整策略,使得整個網絡的準確率大幅提升。
模型訓練方面,實現Fluid框架訓練OCR英文識別模型,與舊版本Paddle訓練出的模型相比,精度相對提升1%。此外,還在Paddle-Cloud上實現了afs數據分發,實現了Paddle-Cloud進行單機單卡、單機多卡訓練OCR識別模型。
OCR預測庫接入和封裝需要解決的問題包括:
1、開發Fluid預測庫框架,實現統一接口的封裝;
2、實現Fluid預測庫框架下的多batch預測;
3、攜手sys anakin團隊優化了GPU預測速度,加速47%;
4、將fluid-OCR預測加入到QA自動回歸測試流程,避免因Paddle升級而引入新的bug。
在預測庫的接入和封裝方面遇到了不少困難,其中包括封裝的接口與原服務Tcmalloc兼容、預測加速不明顯、新預測庫對原檢測系統耗時的影響大等問題。
具體的解決方法如下:
1、在動態庫里面提供glibc編譯的內存釋放接口;
2、與sys anakin團隊合作,優化了預測速度;
3、fluid默認打開了openblas的多線程。openblas多線程優先級較高,導致系統默認多線程的資源只能分配到單核CPU上,需要服務顯式關閉openblas的多線程。

經過一番努力之后,實現了基于PaddlePaddle Fluid框架訓練和預測的OCR英文識別模型上線。成功上線后,整體中英文系統QPS提升7%,每天影響約1500w含英文文本圖像的OCR流量。
模型研發總結
1、基于公開數據集對齊公開算法,保證基線模型正確性,標準化數據集合和訓練步驟,便于橫向對比。
2、基于開源方式,百度實現貢獻到Paddle社區,經過重復review,提升代碼和文檔質量,實現社區反饋,技術積累和問題解決。
3、基于PaddlePaddle統一的集群訓練方式,實現一些高級訓練特性的快速集成;Paddlemobile,anakin等團隊針對不同硬件的優化;獨立的訓練QA測試,保證訓練結果隨版本迭代可復現。
深度學習框架PaddlePaddle的新特性與煉成之路
PaddlePaddle能全面支撐Modeling、Training和Serving下的各種AI場景。

Paddle Modeling
Paddle Modeling涵蓋數百種計算operator和layer組網;支持序列變長,動態batch size;Pre-trained模型開放。

Paddle Training
Paddle Training支持同步,異步分布式;多線程,多GPU,多stream異構并行計算;ring,trainer-pserver拓撲。

Paddle Serving
Paddle Serving能實現服務器端快速部署;匯編層高度性能優化;移動端Linux-ARM/iOS/Android/DuerOS多終端支持。
PaddlePaddle Serving靈活適配多種預測引擎:
- 靈活融合原生計算operator與第三方預測引擎;
- 默認引擎,快速可用;
- 兼容業內流行預測引擎TensorRT;
- Anakin,百度開源預測引擎,性能優異。
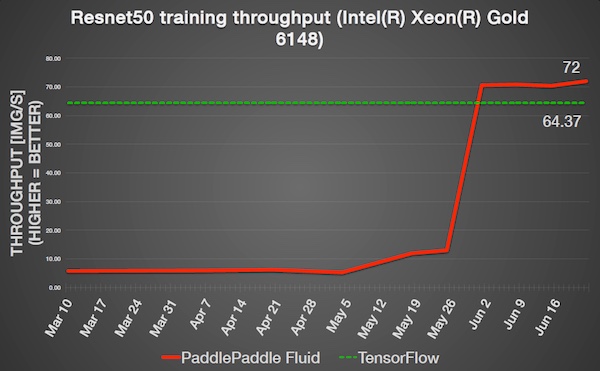
PaddlePaddle Serving的默認引擎:
- 統一的training與serving的基礎架構和實現,訓后模型快速部署。
- 多pass進行圖優化。
- CPU MKLDNN高性能加速。
- GPU可以混合調度TensorRT。
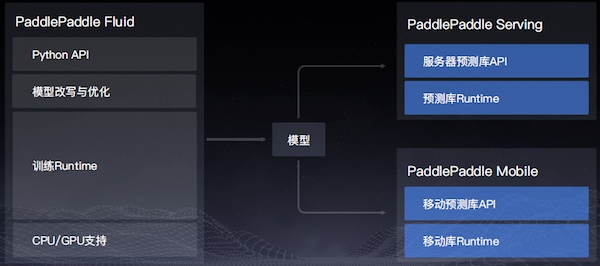
PaddlePaddle核心框架
PaddlePaddle Fluid版本主要包含四大組成部分:Python API;模型改寫與優化;訓練Runtime;CPU/GPU支持。
Python API支持圖像模型、NLP模型、語音模型、推薦模型等各類模型。Python API大致可分為組網類底層API以及執行類底層API兩大類別。組網類底層API包含通用、控制、計算、優化、IO等類型的API。執行類底層API包含訓練、預測、分布式等API。
組網類API
- Variables:Paddle中的變量,可以是Tensor,可以是Parameter,也可以是RPCClient。概念類似高級語言中的變量,可以有不同類型。
- Layers:Paddle中,用戶配置模型的基礎模塊,Layer表示一個或者一組緊密關聯的計算,Layers可以通過輸入輸出連接起來。
- Block:Block表示一組連續的計算邏輯,通常是一個或多個順序Layer組成。通常主模型是一個block0,另外在control flow中,比如while, iflese,也會單獨形成一個子block。
- Control Flow:Paddle支持if-else, while, switch等編程語言中常見的control flow。以確保模型的靈活表達。control flow通常以block的形式存在。
- Program:包含了1個或者多個block,表示一個完整的模型執行單元。執行器需要完整的執行Program,并保證讀寫關系符合用戶的預期。
執行類API

執行類API

執行類API

示例
訓練Runtime
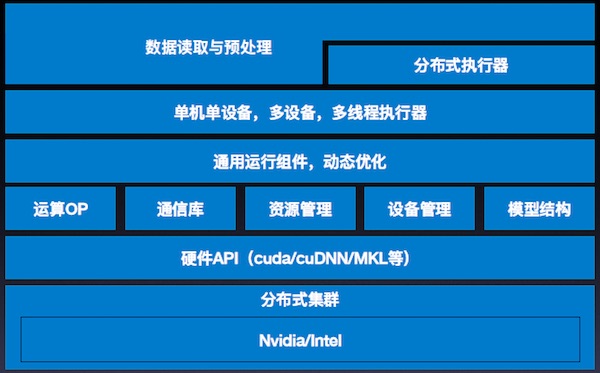
訓練Runtime
顯存優化
- InPlace Activation
- 反向不需要input,并且輸出和輸入的tensor一致,可以直接overwrite input,節省顯存開銷。
- Memory Optimizer
- Live variable analysis:分析每個Op的live-in和live-out,找到可以將來被復用的candidate。在將來的op output中,如果有match candidate的,復用candidate,節省顯存分配。
多卡并行-SSA Graph
- 將模型program轉換成一個可并發執行的Intermediate Representation (IR);利用Static Single Assignment為variable加version,得到一個正確的依賴關系;Build Pass中插入通信節點和額外的依賴關系。
- 基于圖依賴的執行:Input ready的所有operator可以并發執行;Operators在多個GPU上數據并行執行;多卡gradient聚合,確保數據并行中參數一致。

多卡并行-Profile
多機分布式
多機分布式支持ring、pserver兩種模式。ring:自動插入多機communicator,多機同步訓練,支持高性能RDMA通信。pserver:拆分成trainer program和pserver program。支持同步和異步的分布式訓練。Trainer端多線程異步發送gradient;Pserver端多線程異步apply optimization。
用戶Focus Modeling, 框架自動多機化部署:
- 發現optimizer operators,parameters, gradients。
- split和assign他們到parameter server上。
- 在trainer和parameter server上插入發送和接收的通信節點。
- 生成在trainer執行的program。
- 生成在parameter server執行的program。
多機分布式的通信和集群:
- 支持MPI, RPC等通信方式。
- RPC將來會換成brpc,并提供原生的RPC+RDMA支持,極大提高通信效率。
- 支持Kubernetes集群部署。
多機分布式下的容錯:
- trainer或者pserver failure后可以重啟恢復訓練。
- 即將支持pserver端的分布式checkpoint和恢復,支持大規模embedding。
大規模稀疏數據分布式模型訓練
在互聯網場景中,億級的用戶每天產生著百億級的用戶數據,百度的搜索和推薦系統是大規模稀疏數據分布式模型訓練的主要應用場景。
如何利用這些數據訓練出更好的模型來給用戶提供服務,對機器器學習框架提出了很高的要求。主要包括:
- 樣本數量大,單周20T+。
- 特征維度多達千億甚至萬億。
- T級別,參數大。
- 小時級更新,時效要求高。
主要問題包括三個方面:
1. 在千億feature的時候,一個寬度8的 embedding table的參數量2980.23GB。
2. Feature ID使用hash算法計算,分布在int64范圍內,難以預先確定。
3. 輸入特征非常稀疏。(數百/千億)
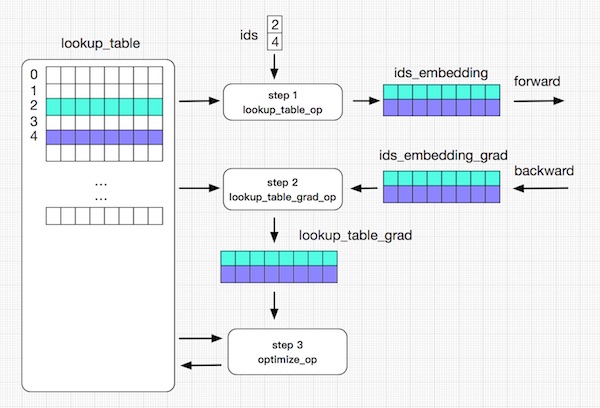
分布式查找表(Distribute Lookup Table):
1. 參數量大:針對數據特點的數據結構SelectedRows(key-value);分布式存儲;Pserver端 save/load。
2. Feature ID不確定:Auto Growth。
3. 輸入特征稀疏:參數Prefetch。
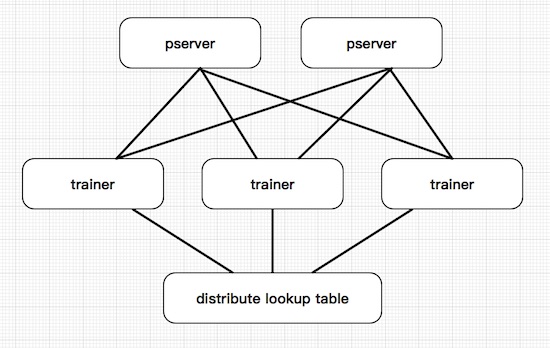
系統整體架構一
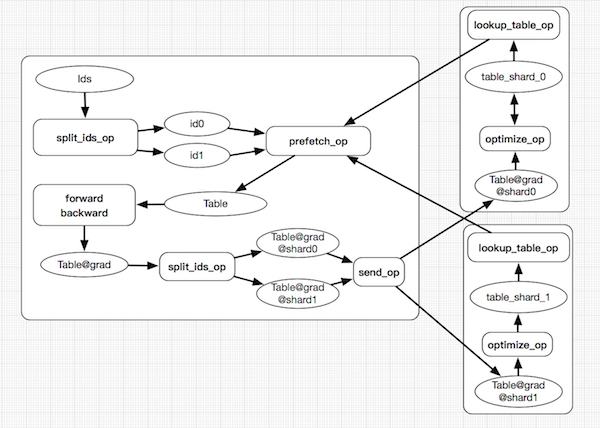
系統整體架構二
應用優化
- Model Average Optimizer:訓練中通過窗⼝累計歷史parameter,在預測時使用average后的parameter,整體提高預測的精度。
- 序列變長:Batch中序列長度不一,計算時無需填充。
- 動態Batch:訓練中,每個iteration的batch size可變。
移動端深度學習優化
移動端深度學習具有低延遲、節省流量、節省吞吐量和隱私安全四大優勢,同時也面臨著來自性能、機型覆蓋、硬件芯片覆蓋、SDK尺寸、內存使用、模型尺寸和32位APP限制等多方面的挑戰。
影響移動端深度學習性能的硬件包括:
- CPU:緩存預取,Block 對齊;降低總線帶寬占用;DL預測加速。
- GPU:矩陣運算,DL預測加速;圖形渲染加速。
- DSP/NPU:DSP高通多媒體芯片;NPU華為AI芯片。
- FPGA:AIG合作研發ARM的AI框架;落地安防監控,各類攝像頭場景。
影響移動端深度學習性能的工具:
- ATrace - 從ftrace中讀取統計信息然后交給數據分析工具來處理。
- Gprof - gprof精確地給出函數被調用的時間和次數。
- xcode - instrument 動態調追蹤和分析OS X和iOS代碼的性能分析。
- streamline - 查看核心數據。
影響移動端深度學習性能的trick包括編譯選項、循環展開、內聯、分支優先和匯編。
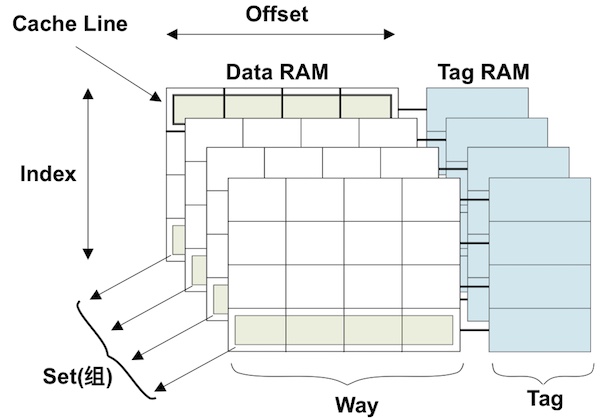
緩存優化
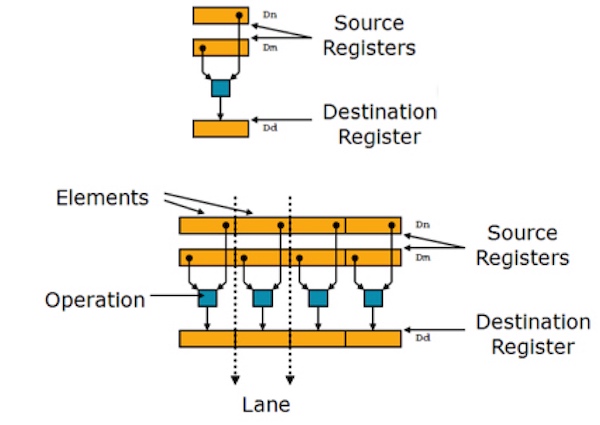
neon優化
移動端深度學習的體積優化有編譯選項、避免不必要引入、根據網絡適配、定制probuf或者去掉。移動端深度學習的能效比優化從DSP、GPU和AI處理器三方面著手。
百度已與華為、ARM等多家硬件廠商展開合作。與華為的合作,基于百度視覺搜索SDK驗證,在圖像分類和主體監測方面,GoogLeNet-V3和squeezenet兩種網絡CPU與NPU性能對比,華為AI芯片的NPU加速效果顯著。
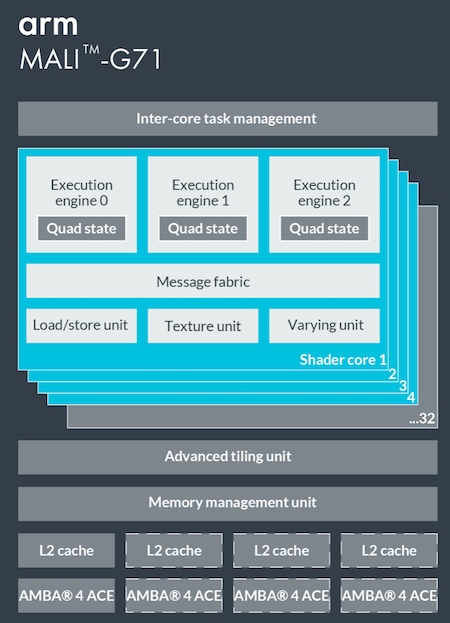
百度還與ARM合作,且在Paddle-Mobile 中已經融入了ARM的合作成果,在Mali GPU上性能表現優異,實現了在G71 mobilenet 1.0運行時的自動切換。
此外,百度專家在本次公開課上還分享了深度學習預測引擎Anakin的優化以及深度學習的可視化,來自英特爾人工智能產品事業部的高級經理Marcin Rysztowski也分享了《PaddlePaddle在Intel平臺的優化》的主題演講。整場公開課可謂干貨滿滿,不難看出百度在深度學習領域的成果頗豐。
據了解,為了更好的幫助開發者學習深度學習,PaddlePaddle建立了覆蓋線上、線下的全套課程及培訓。PaddlePaddle公開課擁有10大系列、400節課程、累計學習時間3000分鐘的在線課程體系,可以覆蓋開發者的學習全階段。
沒有到現場聽課的小伙伴們也不必感到惋惜和沮喪,本次公開課的視頻正在加緊剪輯中,并將在PaddlePaddle的官方微信號上更新,讓我們共同期待吧。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】













