Hadoop老矣,為什么騰訊還要花精力在其開源發布上?

前些日子,騰訊主導開源大數據平臺 Apache Hadoop 2.8.4 新版本發布的新聞引起了筆者的注意。自 Hadoop 從雅虎誕生之日起,已經走過了 10 來個年頭,這期間,尤其是近年來,由華人作為 Release Manager 主導新版本發布已經有過不少先例,不過背后的公司不外乎雅虎、微軟、Hortonworks、Cloudera 等美國公司。而這次的新版本是***由中國公司主導發布,這對于國內的開源社區當然是一個重要的鼓勵,說明中國的開發者和開發組織完全有能力突破障礙,來勝任熱門開源社區中的更有影響力的角色;另一方面,這也意味著騰訊長期以來支持和擁抱開源以及開源社區的舉動有了回報,開始收獲開源社區影響力了。
對于筆者來說,更加好奇的卻是另外一個問題,在國內外紛紛唱衰 Hadoop 的論調中,為什么騰訊還要花費這么大精力去主導 Hadoop 的開源版本發布?
Hadoop 最早誕生于 2006 年,并在 2008 年成為 Apache ***項目。雖然在誕生之初,只有國內外幾家巨頭嘗試使用 Hadoop 技術,但沒過多久,Hadoop 就成為了互聯網行業大數據計算的標準配置,Hadoop 也快速成為 Apache 軟件基金會的金牌項目之一。不僅如此,它還孕育了包括 HBase、Hive、ZooKeeper 等一系列知名 Apache ***項目,而這些項目一開始都是以 Apache Hadoop 子項目的形式在社區運作并為開發者熟知的。
至今,Hadoop 已經走過了 12 個年頭,這對于任何軟件來說生命周期都不可謂不長。而從 2016 年開始,國內外就開始出現唱衰 Hadoop 的聲音。雖然對于國內外很多企業來說,Hadoop 依然是大數據計算不可缺少的配置,但對于 Hadoop 未來的發展,很多人都并不看好,“談不上會有好的發展”。Hadoop 背后***的平臺提供商 Hortonworks 也開始往以云計算為中心的世界靠攏。
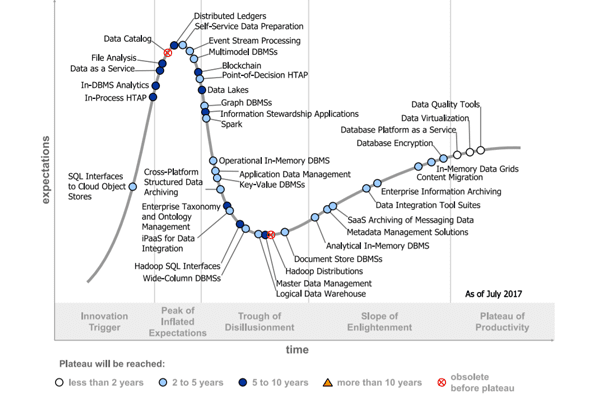
去年 9 月,Gartner 將 Hadoop 發行版從數據管理的技術成熟度曲線中淘汰出局,原因是由于整個 Hadoop 堆棧的復雜性和可用性問題,許多組織已經開始重新考慮其在信息基礎架構中的角色。而今年 KDnuggets 發布的數據科學和機器學習工具調查報告則顯示 Hadoop 的使用率也下降了,這讓“Hadoop 老矣”的說法又再度流傳起來。
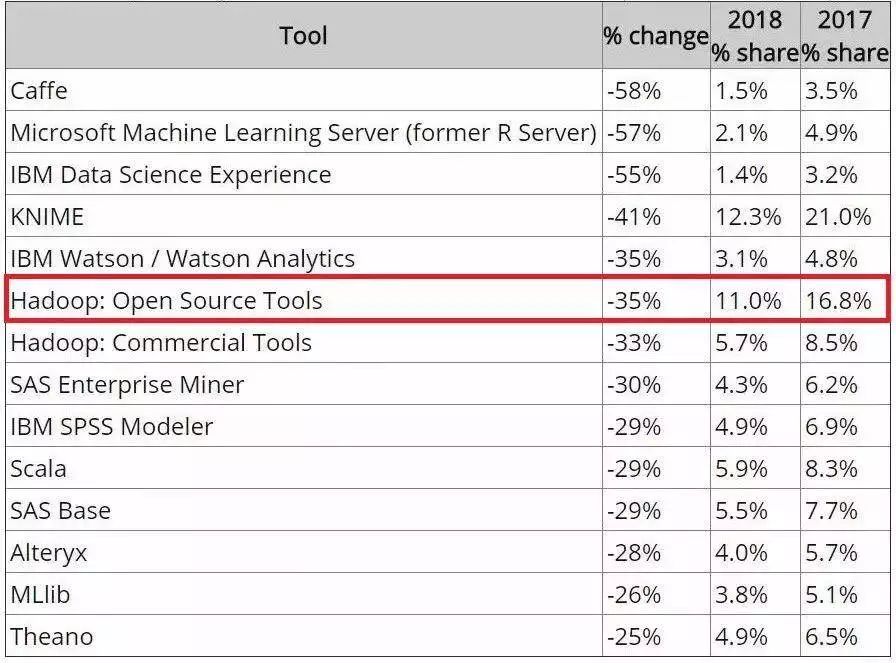
2018 年數據科學和機器學習工具調查報告顯示 Hadoop 使用率下降 35%
在這個時候,為什么騰訊要花費大力氣去主導 Hadoop 開源版本的發布?
負責主導本次開源版本發布的騰訊云專家研究員堵俊平告訴 AI 前線,真正“老矣”的是 Hadoop 商業發行版而非 Hadoop 技術本身, 不論在國內還是國外,Hadoop 技術都保持著大數據平臺的核心和事實標準地位。需要變革的是 Hadoop 技術的使用和發行方式, 未來越來越多的用戶從使用線下 Hadoop 發行版向云上的數據湖(對象存儲 +Hadoop)遷移可能會成為一種趨勢。
騰訊選用 Hadoop:兼顧平臺穩定性和技術先進性
騰訊的大數據平臺有不少為自身特殊場景優化甚至重新自研的產品和組件,但有相當大的一部分是基于開源 Hadoop 生態組件構建的。
目前騰訊的大數據平臺用到了非常多的 Hadoop 生態組件。以騰訊云上開放的彈性 MapReduce 服務為例,騰訊提供了 Hadoop、HBase、Spark、Hive、Presto、Storm、Flink、Sqoop 等組件服務。不同組件也發揮了不同的用處:數據存儲和計算資源調度由 Hadoop 來實現,數據的導入可以用 Sqoop,HBase 提供了 NoSQL 數據庫服務,離線數據處理由 MapReduce、Spark、Hive 等完成,流式數據處理則由 Storm、Spark Streaming 以及 Flink 來提供等等。
堵俊平表示,對于 Hadoop 生態的各類組件的選型,騰訊的總體原則是兼顧平臺穩定性和技術先進性。一方面,需要理解每個組件所適用的場景以及它們的能力邊界,另一方面,從測試和運維實踐來看,要了解每個組件的穩定程度和運維復雜度。以基于 Hadoop 的數倉組件為例,新版的 Hive 增加了 LLAP 組件來提升交互式查詢的性能和速度,但從當前運行的實際效果來看并不穩定,所以騰訊暫緩把這個組件引入生產系統,Hive 更多服務于離線計算的場景,而交互式查詢由更為穩定的 SparkSQL 和 Presto 來提供。
騰訊并非個例,在國內外很多企業的大數據平臺中,Hadoop 生態的各類組件都占了相當大的比重。誰都離不開它,但可能應用太普遍,Hadoop 受到的關注反而變少了。作為 Hadoop 的 PMC,堵俊平表示,Hadoop 作為大數據平臺的核心和事實標準地位,在國內外并沒有太大的區別。不過在各個行業,Hadoop 應用的成熟度卻不盡相同。舉例來說,Hadoop 在互聯網公司應用的最早也最為成熟;其次是金融行業,Hadoop 大數據平臺落地的成功案例很多,也相對比較成熟。當前 Hadoop 大數據平臺應用的熱點是在政務和安防領域以及 IOT 工業互聯網平臺,這些新的熱點帶來新的需求也會促使 Hadoop 技術和生態繼續向前進化。
Hadoop 技術未老,但使用和發行方式需要變革
對于 Gartner 將 Hadoop 從技術成熟度曲線中淘汰出局,堵俊平指出,Gartner 的報告是針對 Hadoop 商業發行版而非 Hadoop 技術本身。
報告中所提到的 Hadoop 發行版的問題:比如發行版的復雜度高以及包含很多非必要性組件,從用戶的反饋來看,是真實存在的。很多商業發行版,例如 CDH 或者 HDP,都包含了洋洋灑灑十幾種甚至幾十種組件給用戶使用,在提供靈活性的同時,也給用戶帶來了很多使用和運維上的煩惱。更嚴重的是,這個問題從近幾年的觀察來看,不但沒有減輕且有愈演愈烈的趨勢。所以,Hadoop 技術的使用和發行的方式需要變革,未來越來越多的用戶從使用線下的 Hadoop 發行版向云上的數據湖(對象存儲 +Hadoop)遷移可能會成為一種趨勢。
堵俊平坦言,Hadoop 生態確實存在一些不足。Hadoop 的生態系統非常復雜,每個組件都是獨立的模塊,由單獨的開源社區開發和發布,我們可以稱之為松耦合。這種松耦合的開發方式,好處是靈活、適應面廣、開發周期可控,缺點是組件之間配合的成熟度低、版本沖突嚴重、集成測試困難。這也給用戶的使用帶來了困難,因為一個場景中需要涉及到很多組件的配置工作。
雖然流計算對于大數據處理來說越來越重要,但不支持流計算卻不會成為 Hadoop 的致命傷。雖然 Hadoop 自身不提供流計算服務,不過主要的流計算組件,如 Storm、Spark Streaming 以及 Flink 本身就屬于 Hadoop 生態系統的一部分,因此并不構成太大的問題。
Hadoop 生態組件競爭激烈,Spark 優勢明顯,MapReduce 已進入維護模式
曾有開發者向 AI 前線表示,Hadoop 主要是被 MapReduce 拖累了,其實 HDFS 和 YARN 都還不錯。堵俊平則認為 MapReduce 拖累 Hadoop 的說法并不準確,首先 MapReduce 還是有應用場景,只是越來越窄,它仍然適合某些超大規模數據處理的批量任務,且任務運行非常穩定;其次,Hadoop 社區對于 MapReduce 的定位就是進入維護模式, 并不追求任何新的功能或性能演進,這樣可以讓資源投入到更新的計算框架,比如 Spark、Tez,促進其成熟。
HDFS 和 YARN 目前還是大數據領域分布式存儲和資源調度系統的事實標準,不過也面臨一些挑戰。對 HDFS 而言,在公有云領域,越來越多的大數據應用會選擇跳過 HDFS 而直接使用云上的對象存儲, 這樣比較方便實現計算與存儲分離,增加了資源彈性。YARN 也面臨著來自 Kubernetes 的強大挑戰,尤其是原生的 docker 支持,更好的隔離性以及上面生態的完整性。不過 K8S 在大數據領域還是追趕者,在資源調度器以及和對各計算框架支持上還有很大的進步空間。
Spark 在計算框架方面基本上占據了主導地位,MapReduce 主要是一些歷史應用,而 Tez 更像是 Hive 的專屬執行引擎。流處理方面,早期的流處理引擎 Storm 正在退役,而當前唱主角的則是 Spark Streaming 和 Flink,這兩個流處理引擎各有千秋,前者強在生態,后者則在架構方面有優勢。一個有意思的情況是,對于 Spark Streaming 和 Flink 的應用在國內外的情況很不一樣,國內已經有大量的公司開始使用 Flink 構建自己的流處理平臺,但美國市場 Spark Streaming 還是占絕對主流的地位。當然,還有一些新的流處理框架,例如 Kafka Streams 等等,發展得也不錯。
在大數據 SQL 引擎方面,四大主流引擎 Hive、SparkSQL、Presto 以及 Impala 仍然各有所長。
Hive 最早由 Facebook 開源貢獻也是早年應用最廣泛的大數據 SQL 引擎,和 MapReduce 一樣,Hive 在業界的標簽就是慢而穩定。其無私地提供了很多公共組件為其他引擎所使用,堪稱業界良心,比如元數據服務 Hive Metastore、查詢優化器 Calcite、列式存儲 ORC 等。近年來,Hive 發展很快,例如查詢優化方面采用了 CBO,在執行引擎方面用 Tez 來替換 MapReduce,通過 LLAP 來 cache 查詢結果做優化,以及 ORC 存儲不斷演進。不過相比較而言,這些新技術從市場應用來說還不算成熟穩定,Hive 仍然被大量用戶定義為可靠的 ETL 工具而非即時查詢產品。
SparkSQL 這兩年發展迅猛,尤其在 Spark 進入 2.x 時代,發展更是突飛猛進。其優秀的 SQL 兼容性(唯一全部 pass TPC-DS 全部 99 個 query 的開源大數據 SQL),卓越的性能、龐大且活躍的社區、完善的生態(機器學習、圖計算、流處理等)都讓 SparkSQL 從這幾個開源產品中脫穎而出,在國內外市場得到了非常廣泛的應用。
Presto 這兩年應用也非常廣泛,這款內存型 MPP 引擎的特點就是處理小規模數據會非常快,數據量大的時候會比較吃力。Impala 的性能也非常優異,不過其發展路線相對封閉,社區生態進展比較緩慢,SQL 兼容性也比較差,用戶群體相對較小。
Hadoop 生態必然會向云發展,IOT 值得長期關注
Hadoop 已經 12 歲了,未來 Hadoop 生態將會如何發展?堵俊平表示,未來 Hadoop 的生態會向云的方向發展,簡化運維甚至免運維既是用戶的需求也是云廠商的優勢所在。越來越多的數據在云中產生、存儲和消費,從而形成數據生命周期在云端的閉環——數據湖。所以云上的數據安全和隱私保護技術顯得十分重要。
除此之外,Hadoop 在混合云上的部署和應用也會是一個重要的趨勢,而這方面的技術和架構還不是非常成熟,需要持續創新和創造。在這樣的背景下,傳統 Hadoop 發行版廠商的話語權在技術和商業層面會相對減少,而云廠商的話語權則會增大。 另外一個趨勢是 Hadoop 生態會不斷向數據應用端生長,強調從數據處理到數據治理的轉變,更方便的 ETL 工具、元數據管理與數據治理工具會逐漸走向成熟與完善。***,Hadoop 生態也會從單純的大數據平臺演化到集數據與機器學習平臺為一體, 未來可助力很多的 AI 應用場景。
堵俊平告訴 AI 前線,未來大數據領域比較重要的發展方向中,IOT 是一個值得長期關注的領域。在大數據發展歷史上,這部分業務發展周期較短,很多技術都不是非常成熟,標準也沒有完全統一。除此之外,云上的大數據產品還有技術變革的空間,例如:跨數據中心 / 云的解決方案、自動化關鍵數據業務遷移、數據隱私保護、自動機器學習等,未來一定會有更加創新的產品來打動和吸引用戶上云。
騰訊云會聚焦云端大數據用戶的核心痛點,制定相應的技術和產品路線。對于大數據平臺的底層平臺架構,騰訊云會更加強調 serverless,注重性能與開銷的平衡,提高資源利用率會是一個長期的方向。而 Hadoop 生態會繼續在其中扮演重要角色,因為市場更為認可開放和開源的產品以及解決方案。騰訊云也會繼續貢獻和回饋開源社區,和社區一起創造更好更新的技術來滿足未來的需要。
結語
Hadoop 花了 12 年從一個新興開源項目成長為大數據平臺標準配置,實屬不易。如今 Hadoop 生態內部面臨著來自眾多年輕開源組件的競爭壓力,優勝劣汰也很正常,世上沒有十全十美的開源平臺,憑借已有的優勢,Hadoop 生態的地位依然十分穩固,但未來是否還能煥發出新的活力,抑或在全面云化的進程中逐漸式微,仍是一個未知數。