大數據的列式存儲格式:Parquet
今天介紹一種大數據時代有名的列式存儲文件格式:Parquet,被廣泛用于 Spark、Hadoop 數據存儲。Parquet 的中文是鑲木地板,意思是結構緊湊,空間占用率高。注意,Parquet 是一種文件格式!
背景
2010年 google 發(fā)表了一篇論文《Dremel: Interactive Analysis of Web-Scale Datasets》,介紹了其 Dermel 系統是如何利用列式存儲管理嵌套數據的,嵌套數據就是層次數據,如定義一個班級,班級由同學組成,同學的信息有學號、年齡、身高等。
Parquet 是 Dremel 的開源實現,作為一種列式存儲文件格式,2015年稱為 Apache ***項目,后來被 Spark 項目吸收,作為 Spark 的默認數據源,在不指定讀取和存儲格式時,默認讀寫 Parquet 格式的文件。
今天不介紹嵌套數據是如何映射到每一列了,簡單來說就是把不同層級的屬性拍到一級,類似降維打擊。這樣,一個嵌套數據可以看成獨立的多個屬性,每一個屬性就是一列,和表結構差不多。
寫流程
雖然是按列存儲,但數據是一行一行來的,那什么時候將內存中的數據寫文件呢?我們知道文件只能順序寫,假如每收到一行數據就寫入磁盤,那就是行式存儲了。
一個解決方案是為每個列開一個文件,假如數據有 n 個屬性,就需要 n 個文件,每次寫數據就需要追加到 n 個文件中。但是對于文件格式來說,用戶肯定希望把復雜的數據存到一個文件中,而不希望管理一堆小文件(可以想象你做了一個ppt,每一頁存成了一個文件),所以一個 Parquet 文件中必須存儲數據的所有屬性。
另一個解決方案是在內存中緩存一些數據,等緩存到一定量后,將各個列的數據放在一起打包,這樣各個包就可以按一定順序寫到一個文件中。這就是列式存儲的精髓:按列緩存打包。
文件格式
按照上邊這種方式,Parquet 在每一列內也需要分成一個個的數據包,這個數據包就叫 Page,Page 的分割標準可以按數據點數(如每1000行數據打成一個 Page),也可以按空間占用(如每列的數據攢到8KB合成一個 Page)。
一個 Page 的數據就是一列,類型相同,在存儲到磁盤之前一般都會進行編碼壓縮,為了快速查詢、也為了解壓縮這一個 Page,在寫的時候先統計一下***最小值,叫做 PageHeader,存儲在 Page 的開頭,其實就是 Page 的 元數據(metadata)。PageHeader 后邊就是數據了,讀取一個 Page 時,可以先通過 PageHeader 進行過濾。
Parquet 又把多個 Page 放在一起存儲,叫 Column Chunk。于是,每一列都由多個 Column Chunk 組成,并且也有其對應的 ColumnChunk Metadata。注意,這只是一個完整數據的一個屬性,一個數據的多個屬性要放在多個 Column Chunk 的,這多個 Column Chunk 放在一起就叫做一個 Row Group。
下邊這就是 Parquet 官方介紹:
- 4-byte magic number "PAR1"
- <Column 1 Chunk 1 + Column Metadata>
- <Column 2 Chunk 1 + Column Metadata>
- ...
- <Column N Chunk 1 + Column Metadata>
- <Column 1 Chunk 2 + Column Metadata>
- <Column 2 Chunk 2 + Column Metadata>
- ...
- <Column N Chunk 2 + Column Metadata>
- ...
- <Column 1 Chunk M + Column Metadata>
- <Column 2 Chunk M + Column Metadata>
- ...
- <Column N Chunk M + Column Metadata>
- File Metadata
- 4-byte length in bytes of file metadata
- 4-byte magic number "PAR1"
magic number 就類似水印,***有整個文件的 Metadata。還是看圖吧,Parquet 的官方文件格式圖是下面這樣的:
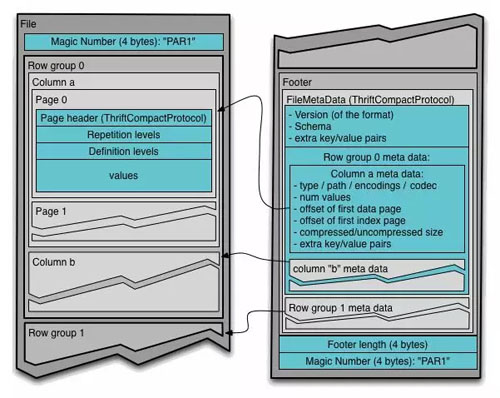
左邊是數據,右邊是 File Metadata。
如果覺得太復雜了,可以看我畫的簡潔版:
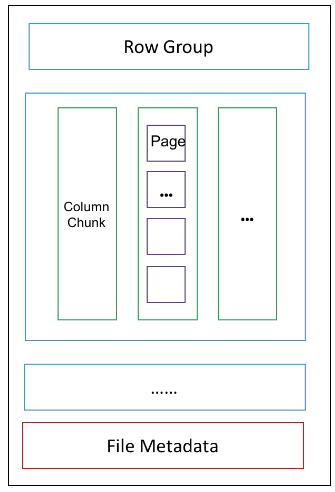
是不是清爽很多!File Metadata 中有對應的 Row Group Metadata,里面還有 Column Chunk Metadta,和數據的組織形式類似,就不展開畫了。
Parquet 的接口就不介紹了,有興趣的去吧:
https://github.com/apache/parquet-format
總結
列式存儲文件格式到底有多列,取決于每列在內存中緩存的數據量,由于同一列的各個 Page 相互獨立,如果每個 Page 只緩存一個數據點,就退化成行式存儲了(比行式存儲還差)。因此,列式存儲有一個需要注意的就是列不能太多,這是個大坑。
跟我們之前介紹的文件格式比,Parquet 只是多了幾層而已,只要掌握了文件格式的基本原理,各種文件格式都可以快速上手。