大數(shù)據(jù)存儲(chǔ) 模型訓(xùn)練數(shù)據(jù)從哪來(lái)

面對(duì)大數(shù)據(jù)的爆炸式增長(zhǎng),且具有大數(shù)據(jù)量、異構(gòu)型、高時(shí)效性的需求時(shí),數(shù)據(jù)的存儲(chǔ)不僅僅有存儲(chǔ)容量的壓力,還給系統(tǒng)的存儲(chǔ)性能、數(shù)據(jù)管理乃至大數(shù)據(jù)的應(yīng)用方面帶來(lái)了挑戰(zhàn)。這些大量的數(shù)據(jù)結(jié)構(gòu)復(fù)雜,種類(lèi)繁多,如何對(duì)分布、多態(tài)、異構(gòu)的大數(shù)據(jù)進(jìn)行管理的問(wèn)題已經(jīng)不期而至,傳統(tǒng)的數(shù)據(jù)存儲(chǔ)方式面對(duì)大數(shù)據(jù)的猛烈增長(zhǎng)已不能滿足需求,需要開(kāi)展分布式存儲(chǔ)的研究。
大數(shù)據(jù)的存儲(chǔ)方式
分布式系統(tǒng):分布式系統(tǒng)可以解決大數(shù)據(jù)存儲(chǔ)的問(wèn)題,為大數(shù)據(jù)的存儲(chǔ)提供了方式。分布式系統(tǒng)的定義包括兩個(gè)方面:第一是關(guān)于硬件的:機(jī)器本身是獨(dú)立的。第二個(gè)方面是關(guān)于軟件的:對(duì)于用戶來(lái)說(shuō),他們就像跟單個(gè)系統(tǒng)打交道。這兩個(gè)方面一起闡明了分布式系統(tǒng)的本質(zhì),缺一不可。
NoSQL數(shù)據(jù)庫(kù):它是“Not Only SQL”的縮寫(xiě),意義是:適用關(guān)系型數(shù)據(jù)庫(kù)的時(shí)候就使用關(guān)系型數(shù)據(jù)庫(kù),不適用的時(shí)候也沒(méi)必要非使用關(guān)系型數(shù)據(jù)庫(kù)不可,可以考慮使用更加合適的數(shù)據(jù)存儲(chǔ)方式。
云存儲(chǔ):云存儲(chǔ)是伴隨著云計(jì)算技術(shù)的發(fā)展而衍生出來(lái)的一種新興的網(wǎng)絡(luò)存儲(chǔ)技術(shù),它是云計(jì)算的重要組成部分,也是云計(jì)算的重要應(yīng)用之一;它不僅是數(shù)據(jù)信息存儲(chǔ)的新技術(shù)、新設(shè)備模型,也是一種服務(wù)的創(chuàng)新模型。
面臨的挑戰(zhàn)
1 系統(tǒng)問(wèn)題
面對(duì)大數(shù)據(jù)的爆炸式增長(zhǎng),且具有大數(shù)據(jù)量、異構(gòu)型、高時(shí)效性的需求時(shí),數(shù)據(jù)的存儲(chǔ)不僅僅有存儲(chǔ)容量的壓力,還給系統(tǒng)的存儲(chǔ)性能、數(shù)據(jù)管理乃至大數(shù)據(jù)的應(yīng)用方面帶來(lái)了挑戰(zhàn)。
2 管理問(wèn)題
這些大量的數(shù)據(jù)結(jié)構(gòu)復(fù)雜,種類(lèi)繁多,如何對(duì)分布、多態(tài)、異構(gòu)的大數(shù)據(jù)進(jìn)行管理的問(wèn)題已經(jīng)不期而至,傳統(tǒng)的數(shù)據(jù)存儲(chǔ)方式面對(duì)大數(shù)據(jù)的猛烈增長(zhǎng)已不能滿足需求,需要開(kāi)展分布式存儲(chǔ)的研究。
3 應(yīng)用問(wèn)題
隨著數(shù)據(jù)量的爆炸式增長(zhǎng),不斷刺激著計(jì)算機(jī)技術(shù)的發(fā)展,如何利用大數(shù)據(jù)為人們生活所用,即是大數(shù)據(jù)的應(yīng)用問(wèn)題。大數(shù)據(jù)的應(yīng)用在人類(lèi)活動(dòng)中所涉及的范圍越來(lái)越大,與我們已經(jīng)密不可分。
4 數(shù)據(jù)轉(zhuǎn)換
數(shù)據(jù)轉(zhuǎn)換是按照預(yù)先設(shè)計(jì)好的規(guī)則將抽取的數(shù)據(jù)進(jìn)行轉(zhuǎn)換,在轉(zhuǎn)化過(guò)程中,我們需要對(duì)數(shù)據(jù)進(jìn)行清洗、整理和集成,即發(fā)現(xiàn)數(shù)據(jù)中的錯(cuò)誤數(shù)據(jù)并進(jìn)行相應(yīng)的改正,將原來(lái)不同規(guī)則的數(shù)據(jù)整理集成為統(tǒng)一的規(guī)則。
全量抽取發(fā)現(xiàn)空值并處理:發(fā)現(xiàn)源數(shù)據(jù)中字段空值,按照一定的規(guī)則進(jìn)行加載或者替換,比如可以用“0”或者按照該字段的平均取值來(lái)替換。
規(guī)范數(shù)據(jù)格式:將不同源系統(tǒng)的不同數(shù)據(jù)格式統(tǒng)一規(guī)范。轉(zhuǎn)化過(guò)程需要將這些不同的表示格式統(tǒng)一成為唯一的規(guī)范格式。
拆分?jǐn)?shù)據(jù):有時(shí)候需要一句業(yè)務(wù)需求對(duì)字段進(jìn)行分解。比如通話主叫號(hào)碼02381322854,可進(jìn)行區(qū)域碼和電話號(hào)碼分解為主叫地區(qū)023和主叫號(hào)碼81322854。
數(shù)據(jù)存儲(chǔ)系統(tǒng)能力的提升主要有三個(gè)方面,一是提升系統(tǒng)的存儲(chǔ)容量,二是提升系統(tǒng)的吞吐量,三是系統(tǒng)的容錯(cuò)性
存儲(chǔ)容量:提升系統(tǒng)容量有兩種方式:一種是提升單硬盤(pán)的容量,通過(guò)不斷采用新的材質(zhì)和新的讀寫(xiě)技術(shù),目前單個(gè)硬盤(pán)的容量已經(jīng)進(jìn)入TB時(shí)代。一種是在多硬盤(pán)的情況的下如何提升整體的存儲(chǔ)容量。
吞吐量:對(duì)于單個(gè)硬盤(pán),提升吞吐量的主要方法是提高硬盤(pán)轉(zhuǎn)速、改進(jìn)磁盤(pán)接口形式或增加讀寫(xiě)緩存等。而要提升數(shù)據(jù)存儲(chǔ)系統(tǒng)的整體吞吐量,比較典型的技術(shù)是早期的專(zhuān)用數(shù)據(jù)庫(kù)機(jī)體系。
容錯(cuò)性:數(shù)據(jù)存儲(chǔ)容錯(cuò)是指當(dāng)系統(tǒng)中的部件或節(jié)點(diǎn)由于硬件或軟件故障,導(dǎo)致數(shù)據(jù)、文件損壞或丟失時(shí),系統(tǒng)能夠自動(dòng)將這些損壞或丟失的文件和數(shù)據(jù)恢復(fù)到故障發(fā)生前的狀態(tài),使系統(tǒng)能夠維持正常運(yùn)行的技術(shù)。
大數(shù)據(jù)從獲取到分析的各個(gè)階段都可能會(huì)涉及到數(shù)據(jù)集的存儲(chǔ),考慮到大數(shù)據(jù)有別于傳統(tǒng)數(shù)據(jù)集,因此大數(shù)據(jù)存儲(chǔ)技術(shù)有別于傳統(tǒng)存儲(chǔ)技術(shù)。大數(shù)據(jù)一般通過(guò)分布式系統(tǒng)、NoSQL數(shù)據(jù)庫(kù)等方式(還有云數(shù)據(jù)庫(kù))進(jìn)行存儲(chǔ)。同時(shí)涉及到以下幾個(gè)新理念。
集群:將多臺(tái)服務(wù)器集中在一起,每臺(tái)服務(wù)器(節(jié)點(diǎn))實(shí)現(xiàn)相同的業(yè)務(wù)。
因此每臺(tái)服務(wù)器并不是缺一不可,集群的目的是緩解并發(fā)壓力和單點(diǎn)故障轉(zhuǎn)移問(wèn)題。
例如:新浪網(wǎng)微博的訪問(wèn)量巨大,因此可以通過(guò)群集技術(shù),幾臺(tái)服務(wù)器完成同一業(yè)務(wù)。當(dāng)有業(yè)務(wù)訪問(wèn)時(shí),選擇負(fù)載較輕的服務(wù)器完成任務(wù)。
分布式
傳統(tǒng)的項(xiàng)目中,各個(gè)業(yè)務(wù)模塊存在于同一系統(tǒng)中,導(dǎo)致系統(tǒng)過(guò)于龐大,開(kāi)發(fā)維護(hù)困難,無(wú)法針對(duì)單個(gè)模塊進(jìn)行優(yōu)化以及水平擴(kuò)展。因此考慮分布式系統(tǒng):
將多臺(tái)服務(wù)器集中在一起,分別實(shí)現(xiàn)總體中的不同業(yè)務(wù)。每臺(tái)服務(wù)器都缺一不可,如果某臺(tái)服務(wù)器故障,則網(wǎng)站部分功能缺失,或?qū)е抡w無(wú)法運(yùn)行。因此可大幅度的提高效率、緩解服務(wù)器的訪問(wèn)存儲(chǔ)壓力。
分布式與集群的關(guān)系、區(qū)別
關(guān)系:分布式方便我們系統(tǒng)的維護(hù)和開(kāi)發(fā),但是不能解決并發(fā)問(wèn)題,也無(wú)法保證我們的系統(tǒng)崩潰后的正常運(yùn)轉(zhuǎn)。集群則恰好彌補(bǔ)了分布式的缺陷,多個(gè)服務(wù)器處理相同的業(yè)務(wù),這可以改善系統(tǒng)的并發(fā)問(wèn)題,同時(shí)保證系統(tǒng)崩潰后的正常運(yùn)轉(zhuǎn)。
因此,分布式和集群技術(shù)一般同時(shí)出現(xiàn),密不可分。(分布式中的每一個(gè)節(jié)點(diǎn),都可以做集群)
區(qū)別:分布式是以縮短單個(gè)任務(wù)的執(zhí)行時(shí)間來(lái)提升效率的,而集群則是通過(guò)提高單位時(shí)間內(nèi)執(zhí)行的任務(wù)數(shù)來(lái)提升效率。
【補(bǔ)充】例如:
如果一個(gè)任務(wù)由10個(gè)子任務(wù)組成,每個(gè)子任務(wù)單獨(dú)執(zhí)行需1小時(shí),則在一臺(tái)服務(wù)器上執(zhí)行改任務(wù)需10小時(shí)。
- 采用分布式方案:提供10臺(tái)服務(wù)器,每臺(tái)服務(wù)器只負(fù)責(zé)處理一個(gè)子任務(wù),不考慮子任務(wù)間的依賴(lài)關(guān)系,執(zhí)行完這個(gè)任務(wù)只需一個(gè)小時(shí)。(這種工作模式的一個(gè)典型代表就是Hadoop的Map/Reduce分布式計(jì)算模型)
- 而采用集群方案:同樣提供10臺(tái)服務(wù)器,每臺(tái)服務(wù)器都能獨(dú)立處理這個(gè)任務(wù)。假設(shè)有10個(gè)任務(wù)同時(shí)到達(dá),10個(gè)服務(wù)器將同時(shí)工作,10小時(shí)后,10個(gè)任務(wù)同時(shí)完成。整身來(lái)看,還是1小時(shí)內(nèi)完成一個(gè)任務(wù)。
文件系統(tǒng) & 分布式文件系統(tǒng)
文件系統(tǒng)——是一種存儲(chǔ)和組織計(jì)算機(jī)數(shù)據(jù)的方法。
數(shù)據(jù)是以文件的形式存在,提供 Open、Read、Write、Seek、Close 等API 進(jìn)行訪問(wèn);
文件以樹(shù)形目錄進(jìn)行組織,提供重命名(Rename)操作改變文件或者目錄的位置。
分布式文件系統(tǒng)——允許文件通過(guò)網(wǎng)絡(luò)在多臺(tái)主機(jī)上分享的文件系統(tǒng),可讓多機(jī)器上的多用戶分享文件和存儲(chǔ)空間。
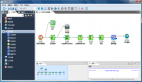
幾種常見(jiàn)的分布式文件存儲(chǔ)系統(tǒng)有GFS(Google分布式文件系統(tǒng))、HDFS(Hadoop分布式文件系統(tǒng))、TFS、Swift、Ceph等。

HDFS系統(tǒng)示意圖
NoSQL(非關(guān)系型數(shù)據(jù)庫(kù))
NoSQL(Not Only SQL),意即"不僅僅是SQL"。NoSQL數(shù)據(jù)庫(kù)可同時(shí)存儲(chǔ)結(jié)構(gòu)化、非結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)。
相比于關(guān)系型數(shù)據(jù)庫(kù),非關(guān)系型數(shù)據(jù)庫(kù)提出另一種理念:每一個(gè)樣本(元組)根據(jù)需要可以有不同的字段,這樣就不局限于固定的結(jié)構(gòu),調(diào)取數(shù)據(jù)時(shí)也更方便。可以減少一些時(shí)間和空間的開(kāi)銷(xiāo)。因此為了獲取用戶的不同信息,不需要像關(guān)系型數(shù)據(jù)庫(kù)中,對(duì)多表進(jìn)行關(guān)聯(lián)查詢(xún)。僅需要根據(jù)id取出相應(yīng)的value就可以完成查詢(xún),通過(guò)XQuery、SPARQL等查詢(xún)語(yǔ)言完成查詢(xún)過(guò)程。
非關(guān)系型數(shù)據(jù)庫(kù)有以下幾種類(lèi)型:

大數(shù)據(jù)集的數(shù)據(jù)量巨大,單機(jī)無(wú)法存儲(chǔ)與處理如此規(guī)模的數(shù)據(jù)量,只能依靠大規(guī)模集群以進(jìn)行存儲(chǔ)和處理,因此系統(tǒng)需要具備可擴(kuò)展性。
目前主流的大數(shù)據(jù)存儲(chǔ)與計(jì)算系統(tǒng)往往采用橫向擴(kuò)展(Scale Out)的方式。因此,對(duì)于待存儲(chǔ)處理的海量數(shù)據(jù),需要用過(guò)數(shù)據(jù)分片將數(shù)據(jù)進(jìn)行切分,并分配到各服務(wù)器中。
數(shù)據(jù)分布的兩條途徑:復(fù)制 & 分片
分布式NoSQL的兩大特性:復(fù)制和分片。
數(shù)據(jù)分片與數(shù)據(jù)復(fù)制是緊密聯(lián)系的兩個(gè)概念。對(duì)于海量數(shù)據(jù),可通過(guò)數(shù)據(jù)分片實(shí)現(xiàn)系統(tǒng)的水平擴(kuò)展,通過(guò)數(shù)據(jù)復(fù)制保證數(shù)據(jù)的高可用性。

數(shù)據(jù)分片與數(shù)據(jù)復(fù)制的關(guān)系
分片(sharding/partition)——將數(shù)據(jù)的各個(gè)部分存放在不同的服務(wù)器/節(jié)點(diǎn)中,每個(gè)服務(wù)器/節(jié)點(diǎn)負(fù)責(zé)自身數(shù)據(jù)的讀取與寫(xiě)入操作,以此實(shí)現(xiàn)橫向擴(kuò)展。
復(fù)制(replication)——將同一份數(shù)據(jù)拷貝到多個(gè)節(jié)點(diǎn)。分為主從復(fù)制master-slave方式、對(duì)等式復(fù)制peer-to-peer。
- 主從式復(fù)制:master節(jié)點(diǎn)用于存放權(quán)威數(shù)據(jù),通常負(fù)責(zé)數(shù)據(jù)的更新,其余節(jié)點(diǎn)都叫做slave節(jié)點(diǎn),復(fù)制操作就是讓slave節(jié)點(diǎn)的數(shù)據(jù)與master節(jié)點(diǎn)的數(shù)據(jù)同步。適用于讀請(qǐng)求密集的負(fù)載。
- 對(duì)等式復(fù)制:兩個(gè)節(jié)點(diǎn)相互為各自的副本,也同時(shí)可以接受寫(xiě)入請(qǐng)求,丟失其中一個(gè)不影響整個(gè)數(shù)據(jù)庫(kù)的訪問(wèn)。但同時(shí)接受寫(xiě)入請(qǐng)求,容易出現(xiàn)數(shù)據(jù)(寫(xiě)入)不一致問(wèn)題,實(shí)際使用上,通常是只有一個(gè)節(jié)點(diǎn)接受寫(xiě)入請(qǐng)求,另一個(gè)master作為stand-by,在對(duì)方出現(xiàn)故障的時(shí)候自動(dòng)承接寫(xiě)操作請(qǐng)求。
分片與復(fù)制可以組合,即同時(shí)采用主從復(fù)制與分片、對(duì)等復(fù)制與分片。
優(yōu)缺點(diǎn)對(duì)比:
分片可以極大地提高讀取性能,但對(duì)于要頻繁寫(xiě)的應(yīng)用,幫助不大。另外,分片對(duì)改善故障恢復(fù)能力并沒(méi)有幫助,但是它減少了故障范圍,只有訪問(wèn)這個(gè)節(jié)點(diǎn)的那些用戶才會(huì)受影響,其余用戶可以正常訪問(wèn)。雖然數(shù)據(jù)庫(kù)缺失了一部分,但是還是其余部分還是可以正常運(yùn)轉(zhuǎn)。
復(fù)制除保證可用性之外,還可增加讀操作的效率。即客戶端可以從多個(gè)備份數(shù)據(jù)中選擇物理距離較近的進(jìn)行讀取,這既增加了讀操作的并發(fā)性又可以提高單次讀的讀取效率。
對(duì)于分布式數(shù)據(jù)庫(kù)系統(tǒng)的設(shè)計(jì)過(guò)程,需遵循CAP定理:
CAP定理(布魯爾定理)
布式數(shù)據(jù)庫(kù)系統(tǒng)不可能同時(shí)滿足以下三點(diǎn),最多只能同時(shí)滿足兩個(gè):
- 一致性(Consistency)——所有節(jié)點(diǎn)在同一時(shí)間具有相同的數(shù)據(jù);
- 可用性(Availability)——保證每個(gè)請(qǐng)求不管成功或者失敗都有響應(yīng);
- 分區(qū)容忍(Partition tolerance)——系統(tǒng)中任意信息的丟失或失敗不會(huì)影響系統(tǒng)的繼續(xù)運(yùn)作。
因此,當(dāng)代的分布式數(shù)據(jù)存儲(chǔ)服務(wù),均是針對(duì)各自服務(wù)的內(nèi)容、性質(zhì)取舍。
而NoSQL數(shù)據(jù)庫(kù)分成了滿足 CA 原則、滿足 CP 原則和滿足 AP 原則三大類(lèi)。

關(guān)系型數(shù)據(jù)庫(kù)的設(shè)計(jì)原則與事務(wù)管理遵循ACID規(guī)則:
ACID
事務(wù)(transaction),具有如下四個(gè)特性:
- A (Atomicity) 原子性——事務(wù)里的所有操作要么全部做完,要么都不做,事務(wù)成功的條件是事務(wù)里的所有操作都成功,只要有一個(gè)操作失敗,整個(gè)事務(wù)失敗,需要回滾。
- C (Consistency)一致性——數(shù)據(jù)庫(kù)要一直處于一致的狀態(tài),事務(wù)的運(yùn)行不會(huì)改變數(shù)據(jù)庫(kù)原本的約束。
- I (Isolation) 獨(dú)立性——并發(fā)的事務(wù)是相互隔離的,一個(gè)事務(wù)的執(zhí)行不能被其他事務(wù)干擾。
- D (Durability) 持久性——是指一旦事務(wù)提交后,它所做的修改將會(huì)永久的保存在數(shù)據(jù)庫(kù)上,即使系統(tǒng)崩潰也不會(huì)丟失。
基于CAP定理演化而來(lái)BASE數(shù)據(jù)庫(kù)設(shè)計(jì)原則:
BASE
包括:Basically Available(基本可用)、Soft state(軟狀態(tài))、Eventually consistent(最終一致性)。
針對(duì)數(shù)據(jù)庫(kù)系統(tǒng)要求的可用性、一致性,BASE放寬要求,形成基本可用和軟狀態(tài)/柔性事務(wù)。而一致性是最終目的。
大模型訓(xùn)練的數(shù)據(jù)來(lái)源
大模型的基礎(chǔ)是大量的數(shù)據(jù)以及算力,下面是一些典型大模型的訓(xùn)練數(shù)據(jù)集大小(以 GB 為單位)。

大模型的訓(xùn)練數(shù)據(jù)源主要包含:
- 維基百科 維基百科是一個(gè)免費(fèi)的多語(yǔ)言協(xié)作在線百科全書(shū),由超過(guò) 300,000 名志愿者組成的社區(qū)編寫(xiě)和維護(hù)。截至 2022 年 4 月,英文版維基百科中有超過(guò) 640 萬(wàn)篇文章,包含超 40 億個(gè)詞[5]。一般來(lái)說(shuō),重點(diǎn)研究實(shí)驗(yàn)室會(huì)首先選取它的純英文過(guò)濾版作為數(shù)據(jù)集。
- 書(shū)籍 故事型書(shū)籍由小說(shuō)和非小說(shuō)兩大類(lèi)組成,主要用于訓(xùn)練模型的故事講述能力和反應(yīng)能力,數(shù)據(jù)集包括 Project Gutenberg 和 Smashwords (Toronto BookCorpus/BookCorpus) 等。
- 雜志期刊 預(yù)印本和已發(fā)表期刊中的論文為數(shù)據(jù)集提供了堅(jiān)實(shí)而嚴(yán)謹(jǐn)?shù)幕A(chǔ),因?yàn)閷W(xué)術(shù)寫(xiě)作通常來(lái)說(shuō)更有條理、理性和細(xì)致。這類(lèi)數(shù)據(jù)集包括 ArXiv 和美國(guó)國(guó)家衛(wèi)生研究院等。
- Reddit 鏈接 WebText 是一個(gè)大型數(shù)據(jù)集,它的數(shù)據(jù)是從社交媒體平臺(tái) Reddit 所有出站鏈接網(wǎng)絡(luò)中爬取的,每個(gè)鏈接至少有三個(gè)贊,代表了流行內(nèi)容的風(fēng)向標(biāo),對(duì)輸出優(yōu)質(zhì)鏈接和后續(xù)文本數(shù)據(jù)具有指導(dǎo)作用。
- Common Crawl
Common Crawl 是 2008 年至今的一個(gè)網(wǎng)站抓取的大型數(shù)據(jù)集,數(shù)據(jù)包含原始網(wǎng)頁(yè)、元數(shù)據(jù)和文本提取,它的文本來(lái)自不同語(yǔ)言、不同領(lǐng)域。重點(diǎn)研究實(shí)驗(yàn)室一般會(huì)首先選取它的純英文過(guò)濾版(C4)作為數(shù)據(jù)集。 - 其他數(shù)據(jù)集不同于上述類(lèi)別,這類(lèi)數(shù)據(jù)集由 GitHub 等代碼數(shù)據(jù)集、StackExchange 等對(duì)話論壇和視頻字幕數(shù)據(jù)集組成。
很多人認(rèn)為,這個(gè)數(shù)據(jù)量也不大啊,也就是幾百GB到TB,根本無(wú)法稱(chēng)之為大量數(shù)據(jù)。其實(shí),以CC數(shù)據(jù)集為例,合計(jì)1.4PB,而GPT3用于訓(xùn)練的CC數(shù)據(jù)僅使用了其中的570GB。這中間是因?yàn)閱未斡?xùn)練進(jìn)行了數(shù)據(jù)的預(yù)處理,只提取了自己關(guān)心的部分。

數(shù)據(jù)爬取和保存通常使用WARC、WAT和WET格式的數(shù)據(jù)存儲(chǔ)。LLaMA的模型使用的是WET格式的數(shù)據(jù)。以Common Crawl為例,每個(gè)CC快照的文本大小約300T,而一個(gè)WET格式的快照大小約30T。
數(shù)據(jù)去重
用CCNet將這些快照進(jìn)行分片(sharding),將原來(lái)的數(shù)據(jù)分成5G一個(gè)分片。然后對(duì)每個(gè)數(shù)據(jù)做預(yù)處理:如小寫(xiě)化所有數(shù)據(jù)、數(shù)字變成占位符等,然后計(jì)算每個(gè)段落的hash,再去重。并行處理數(shù)據(jù),提高處理速度,降低數(shù)據(jù)量。
文本語(yǔ)言識(shí)別與過(guò)濾
識(shí)別語(yǔ)言,然后對(duì)不同語(yǔ)言的數(shù)據(jù)計(jì)算分?jǐn)?shù),最后根據(jù)分?jǐn)?shù)確定是否保留某些語(yǔ)言。在pipeline中執(zhí)行此操作的順序可能會(huì)影響語(yǔ)言識(shí)別的質(zhì)量。CCNet使用使用n-gram特征的fastText分類(lèi)器。
質(zhì)量過(guò)濾
CCNet中,他們建議使用維基百科在目標(biāo)語(yǔ)言上訓(xùn)練一個(gè)簡(jiǎn)單的語(yǔ)言模型,然后計(jì)算每段的困惑度(perplexity),并使用困惑度分布的來(lái)對(duì)它們進(jìn)行分段。
進(jìn)一步過(guò)濾
為了確定頁(yè)面的質(zhì)量。如果這個(gè)頁(yè)面無(wú)法被認(rèn)為是可以作為維基百科引用的,說(shuō)明頁(yè)面本身質(zhì)量可能比較差,所以可以進(jìn)一步丟棄,提高數(shù)據(jù)的質(zhì)量,降低訓(xùn)練成本。經(jīng)過(guò)這么一輪操作猛如虎,剩下數(shù)據(jù)就很少了。未來(lái)數(shù)據(jù)從單一的文本自然語(yǔ)言走向多模態(tài),相關(guān)的訓(xùn)練數(shù)據(jù)集就會(huì)更多了。