爬蟲進階:反反爬蟲技巧!

主要針對以下四種反爬技術:Useragent過濾;模糊的Javascript重定向;驗證碼;請求頭一致性檢查。
高級網絡爬蟲技術:繞過 “403 Forbidden”,驗證碼等
爬蟲的完整代碼可以在 github 上對應的倉庫里找到。
https://github.com/sangaline/advanced-web-scraping-tutorial
簡介
我從不把爬取網頁當做是我的一個愛好或者其他什么東西,但是我確實用網絡爬蟲做過很多事情。因為我所處理的許多工作都要求我得到無法以其他方式獲得的數據。我需要為 Intoli 做關于游戲數據的靜態(tài)分析,所以我爬取了Google應用商店的數據來尋找最新被下載的APK。Pointy Ball插件需要聚合來自不同網站的夢幻足球(游戲)的預測數據,最簡單的方式就是寫一個爬蟲。在我在考慮這個問題的之前,我大概已經寫了大約 40~50 個爬蟲了。我不太記得當時我對我家人撒謊說我已經抓取了多少 TB 的數據….,但是我確實很接近那個數字了。
我嘗試使用 xray/cheerio、nokogiri 和一些其他的工具。但我總是會回到我個人的最愛 Scrapy。在我看來,Scrapy是一個出色的軟件。我對這款軟件毫無保留的贊美是有原因的,它的用法非常符合直覺,學習曲線也很平緩。
你可以閱讀Scrapy的教程,在幾分鐘內就可以讓你的第一個爬蟲運行起來。然后,當你需要做一些更復雜的事情的時候,你就會發(fā)現,有一個內置的、有良好文檔說明的方式來做到這一點。這個框架有大量的內置功能,但是它的結構使得在你用到這些功能之前,不會妨礙到你。當你最終確實需要某些默認不存在的功能的時候,比如說,因為訪問了太多的 URL 鏈接以至于無法存儲到內存中,需要一個用于去重的 bloom filter(布隆過濾器),那么通常來說這就和繼承其中的組件,然后做一點小改動一樣簡單。一切都感覺如此簡單,而且scrapy是我書中一個關于良好軟件設計的例子。
我很久以前就想寫一個高級爬蟲教程了。這給我一個機會來展示scrapy的可擴展性,同時解決實踐中出現的現實問題。盡管我很想做這件事,但是我還是無法擺脫這樣一個事實:因為發(fā)布一些可能導致他人服務器由于大量的機器人流量受到損害的文章,就像是一個十足的壞蛋。
只要遵循幾個基本的規(guī)則,我就可以在爬取那些有反爬蟲策略的網站的時候安心地睡個好覺。換句話說,我讓我的請求頻率和手動瀏覽的訪問頻率相當,并且我不會對數據做任何令人反感的事情。這樣就使得運行爬蟲收集數據基本上和以其他主要的手動收集數據的方法無法區(qū)分。但即使我遵守了這些規(guī)則,我仍感覺為人們實際想要爬取的網站寫一個教程有很大的難度。
直到我遇到一個叫做Zipru的BT下載網站,這件事情仍然只是我腦海里一個模糊的想法。這個網站有多個機制需要高級爬取技術來繞過,但是它的 robots.txt 文件卻允許爬蟲爬取。此外,其實我們不必去爬取它。因為它有開放的API,同樣可以得到全部數據。如果你對于獲得torrent的數據感興趣,那就只需要使用這個API,這很方便。
在本文的剩余部分,我將帶領你寫一個爬蟲,處理驗證碼和解決我們在Zipru網站遇到的各種不同的挑戰(zhàn)。樣例代碼無法被正常運行因為 Zipru 不是一個真實存在的網站,但是爬蟲所使用的技術會被廣泛應用于現實世界中的爬取中。因此這個代碼在另一個意義上來說又是完整的。我們將假設你已經對 Python 有了基本的了解,但是我仍會盡力讓那些對于 Scrapy 一無所知的人看懂這篇文章。如果你覺得進度太快,那么花幾分鐘的時間閱讀一下Scrapy官網教程吧。
建立工程項目
我們會在 virtualenv 中建立我們的項目,這可以讓我們封裝一下依賴關系。首先我們在~/scrapers/zipru中創(chuàng)建一個virtualenv ,并且安裝scrapy包。
- mkdir ~/scrapers/zipru
- cd ~/scrapers/zipru
- virtualenv env
- . env/bin/activate
- pip install scrapy
你運行的終端將被配置為使用本地的virtualenv。如果你打開另一個終端,那么你就需要再次運行. ~/scrapers/zipru/env/bin/active 命令 (否則你有可能得到命令或者模塊無法找到的錯誤消息)。
現在你可以通過運行下面的命令來創(chuàng)建一個新的項目框架:
- scrapy startproject zipru_scraper
這樣就會創(chuàng)建下面的目錄結構。
- └── zipru_scraper
- ├── zipru_scraper
- │ ├── __init__.py
- │ ├── items.py
- │ ├── middlewares.py
- │ ├── pipelines.py
- │ ├── settings.py
- │ └── spiders
- │ └── __init__.py
- └── scrapy.cfg
大多數默認情況下產生的這些文件實際上不會被用到,它們只是建議以一種合理的方式來構建我們的代碼。從現在開始,你應該把 ~/scrapers/zipru/zipru_scraper 當做這個項目的根目錄。這里是任何scrapy命令運行的目錄,同時也是所有相對路徑的根。
添加一個基本的爬蟲功能
現在我們需要添加一個Spieder類來讓我們的scrapy真正地做一些事情。Spider類是scrapy爬蟲用來解析文本,爬取新的url鏈接或是提取數據的一個類。我們非常依賴于默認Spider類的實現,以最大限度地減少我們必須要編寫的代碼量。這里要做的事情看起來有點自動化,但假如你看過文檔,事情會變得更加簡單。
首先,在zipru_scraper/spiders/目錄下創(chuàng)建一個文件,命名為 zipru_spider.py ,輸入下面內容。
- import scrapy
- class ZipruSpider(scrapy.Spider):
- name = 'zipru'
- start_urls = ['http://zipru.to/torrents.php?category=TV']
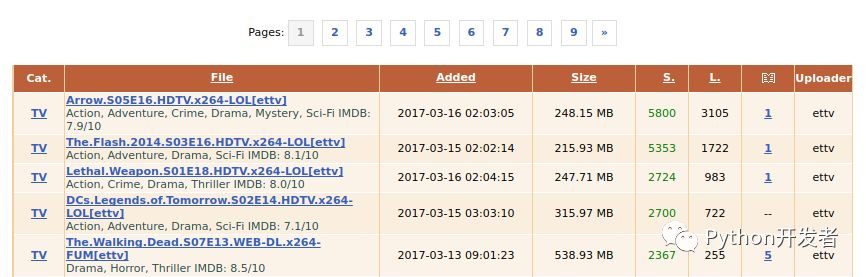
你可以在上面的網頁中看到許多指向其他頁面的連接。我們想讓我們的爬蟲跟蹤這些鏈接,并且解析他們的內容。為了完成這個任務,我們首先需要識別出這些鏈接并且弄清楚他們指向的位置。
在這個階段,DOM檢查器將起到很大的助力。如果你右擊其中的一個頁面鏈接,在DOM檢查器里面查看它,然后你就會看到指向其他頁面的鏈接看起來像是這樣的:
- <a href="/torrents.php?...page=2" title="page 2">2</a>
- <a href="/torrents.php?...page=3" title="page 3">3</a>
- <a href="/torrents.php?...page=4" title="page 4">4</a>
接下來我們需要為這些鏈接構造一個選擇器表達式。有幾種類型似乎用css或者xpath選擇器進行搜索更適合,所以我通常傾向于靈活地混合使用這幾種選擇器。我強烈推薦學習xpath,但是不幸的是,它有點超出了本教程的范圍。我個人認為xpath對于網絡爬蟲,web UI 測試,甚至一般的web開發(fā)來說都是不可或缺的。我接下來仍然會使用css選擇器,因為它對于大多數人來說可能比較熟悉。
要選擇這些頁面鏈接,我們可以把 a[title ~= page] 作為一個 css 選擇器,來查找標題中有 “page” 字符的 <a>標簽。如果你在 DOM 檢查器中按 ctrl-f,那么你就會發(fā)現你也可以使用這個css表達式作為一條查找語句(也可以使用xpath)。這樣我們就可以循環(huán)查看所有的匹配項了。這是一個很棒的方法,可以用來檢查一個表達式是否有效,并且表達式足夠明確不會在不小心中匹配到其他的標簽。我們的頁面鏈接選擇器同時滿足了這兩個條件。
為了講解我們的爬蟲是怎樣發(fā)現其他頁面的,我們在 ZipruSpider 類中添加一個 parse(response) 方法,就像下面這樣:
- def parse(self, response):
- # proceed to other pages of the listings
- for page_url in response.css('a[title ~= page]::attr(href)').extract():
- page_url = response.urljoin(page_url)
- yield scrapy.Request(url=page_url, callback=self.parse)
當我們開始爬取的時候,我們添加到 start_urls 中的鏈接將會被自動獲取到,響應內容會被傳遞到 parse(response) 方法中。之后我們的代碼就會找到所有指向其他頁面的鏈接,并且產生新的請求對象,這些請求對象將使用同一個 parse(response) 作為回調函數。這些請求將被轉化成響應對象,只要 url 仍然產生,響應就會持續(xù)地返回到 parse(response)函數(感謝去重器)。
我們的爬蟲已經可以找到了頁面中列出的所有不同的頁面,并且對它們發(fā)出了請求,但我們仍然需要提取一些對爬蟲來說有用的數據。torrent 列表位于 <table> 標簽之內,并且有屬性 class="list2at" ,每個單獨的 torrent 都位于帶有屬性 class="lista2" 的 <tr> 標簽,其中的每一行都包含 8 個 <td>標簽,分別與 “類別”,“文件”,“添加時間”,“文件大小”,“保種的人”,“下載文件的人”,“文件描述”,和“上傳者”相對應。在代碼中查看其它的細節(jié)可能是最簡單的方法,下面是我們修改后的 parse(response) 方法:
- def parse(self, response):
- # proceed to other pages of the listings
- for page_url in response.xpath('//a[contains(@title, "page ")]/@href').extract():
- page_url = response.urljoin(page_url)
- yield scrapy.Request(url=page_url, callback=self.parse)
- # extract the torrent items
- for tr in response.css('table.lista2t tr.lista2'):
- tds = tr.css('td')
- link = tds[1].css('a')[0]
- yield {
- 'title' : link.css('::attr(title)').extract_first(),
- 'url' : response.urljoin(link.css('::attr(href)').extract_first()),
- 'date' : tds[2].css('::text').extract_first(),
- 'size' : tds[3].css('::text').extract_first(),
- 'seeders': int(tds[4].css('::text').extract_first()),
- 'leechers': int(tds[5].css('::text').extract_first()),
- 'uploader': tds[7].css('::text').extract_first(),
- }
我們的 parse(response) 方法現在能夠返回字典類型的數據,并且根據它們的類型自動區(qū)分請求。每個字典都會被解釋為一項,并且作為爬蟲數據輸出的一部分。
如果我們只是爬取大多數常見的網站,那我們已經完成了。我們只需要使用下面的命令來運行:
- scrapy crawl zipru -o torrents.jl
幾分鐘之后我們本應該得到一個 [JSON Lines] 格式 torrents.jl 文件,里面有我們所有的torrent 數據。取而代之的是我們得到下面的錯誤信息(和一大堆其他的東西):
- [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
- [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
- [scrapy.core.engine] DEBUG: Crawled (403) <GET http://zipru.to/robots.txt> (referer: None) ['partial']
- [scrapy.core.engine] DEBUG: Crawled (403) <GET http://zipru.to/torrents.php?category=TV> (referer: None) ['partial']
- [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://zipru.to/torrents.php?category=TV>: HTTP status code is not handled or not allowed
- [scrapy.core.engine] INFO: Closing spider (finished)
我好氣啊!我們現在必須變得更聰明來獲得我們完全可以從公共API得到的數據,因為上面的代碼永遠都無法爬取到那些數據。
簡單的問題
我們的第一個請求返回了一個 403 響應,所以這個url被爬蟲忽略掉了,然后一切都關閉了,因為我們只給爬蟲提供了一個 url 鏈接。同樣的請求在網頁瀏覽器里運行正常,即使是在沒有會話(session)歷史的隱匿模式也可以,所以這一定是由于兩者請求頭信息的差異造成的。我們可以使用 tcpdump 來比較這兩個請求的頭信息,但其實有個常見錯誤,所以我們應該首先檢查: user agent 。
Scrapy 默認把 user-agent 設置為 “Scrapy/1.3.3 (+http://scrapy.org)“,一些服務器可能會屏蔽這樣的請求,甚至使用白名單只允許少量的user agent 通過。你可以在線查看 最常見的 user agent ,使用其中任何一個通常就足以繞過基本反爬蟲策略。選擇一個你最喜歡的 User-agent ,然后打開 zipru_scraper/settings.py ,替換 User agent
- # Crawl responsibly by identifying yourself (and your website) on the user-agent
- #USER_AGENT = 'zipru_scraper (+http://www.yourdomain.com)'
使用下面內容替換 USER_AGENT :
- USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'
你可能注意到了,默認的scrapy設置中有一些令爬蟲蒙羞的事。關于這個問題的觀點眾說紛紜,但是我個人認為假如你想讓爬蟲表現的像是一個人在使用普通的網頁瀏覽器,那么你就應該把你的爬蟲設置地像普通的網絡瀏覽器那樣。所以讓我們一起添加下面的設置來降低一下爬蟲響應速度:
- CONCURRENT_REQUESTS = 1
- DOWNLOAD_DELAY = 5
通過 AutoThrottle 擴展 ,上面的設置會創(chuàng)建一個稍微真實一點的瀏覽模式。我們的爬蟲在默認情況下會遵守 robots.txt,所以現在我們的行為非常檢點。
現在使用 scrapy crawl zipru -o torrents.jl 命令再次運行爬蟲,應該會產生下面的輸出:
- [scrapy.core.engine] DEBUG: Crawled (200) <GET http://zipru.to/robots.txt> (referer: None)
- [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://zipru.to/threat_defense.php?defense=1&r=78213556> from <GET http://zipru.to/torrents.php?category=TV>
- [scrapy.core.engine] DEBUG: Crawled (200) <GET http://zipru.to/threat_defense.php?defense=1&r=78213556> (referer: None) ['partial']
- [scrapy.core.engine] INFO: Closing spider (finished)
這是一個巨大的進步!我們獲得了兩個 200 狀態(tài)碼和一個 302狀態(tài)碼,下載中間件知道如何處理 302 狀態(tài)碼。不幸的是,這個 302 將我們的請求重定向到了一個看起來不太吉利的頁面 threat_defense.php。不出所料,爬蟲沒有發(fā)現任何有用的東西,然后爬蟲就停止運行了。
注: 假如網站檢測到你的爬蟲,那么網站就會把你的請求重定向到 threat_defense.php 頁面,使你的爬蟲失效,用來防止頻繁的爬蟲請求影響了網站正常用戶的使用。
下載中間件
在我們深入研究我們目前所面臨的更復雜的問題之前,先了解一下請求和響應在爬蟲中是怎樣被處理的,將會很有幫助。當我們創(chuàng)建了我們基本的爬蟲,我們生成了一個 scrapy.Request 對象,然后這些請求會以某種方法轉化為與服務器的響應相對應的 scrapy.Response對象。這里的 “某種方法” 很大一部分是來自于下載中間件。
下載中間件繼承自 scrapy.downloadermiddlewares.DownloaderMiddleware 類并且實現了 process_request(request, spider) 和 process_response(request, response, spider) 方法。你大概可以從他們的名字中猜到他們是做什么的。實際上這里有一大堆的默認開啟的中間件。下面是標準的中間件配置(你當然可以禁用、添加或是重新設置這些選項):
- DOWNLOADER_MIDDLEWARES_BASE = {
- 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
- 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
- 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
- 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
- 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
- 'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
- 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
- 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
- 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
- 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
- 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
- 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
- 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
- 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
- }
當一個請求到達服務器時,他們會通過每個這些中間件的 process_request(request, spider) 方法。 這是按照數字順序發(fā)生的,RobotsTxtMiddleware 中間件首先產生請求,并且 HttpCacheMiddleware 中間件最后產生請求。一旦接收到一個響應,它就會通過任何已啟用的中間件的 process_response(request,response,spider) 方法來返回響應。這次是以相反的順序發(fā)生的,所以數字越高越先發(fā)送到服務器,數字越低越先被爬蟲獲取到。
一個特別簡單的中間件是 CookiesMiddleware。它簡單地檢查響應中請求頭的 Set-Cookie,并且保存 cookie 。然后當響應返回的時候,他們會適當地設置 Cookie 請求頭標記,這樣這些標記就會被包含在發(fā)出的請求中了。這個由于時間太久的原因要比我們說的要稍微復雜些,但你會明白的。
另一個相對基本的就是 RedirectMiddleware 中間件,它是用來處理 3XX 重定向的。它讓一切不是 3XX 狀態(tài)碼的響應都能夠成功的通過,但假如響應中還有重定向發(fā)生會怎樣? 唯一能夠弄清楚服務器如何響應重定向URL的方法就是創(chuàng)建一個新的請求,而且這個中間件就是這么做的。當 process_response(request, response, spider) 方法返回一個請求對象而不是響應對象的時候,那么當前響應就會被丟棄,一切都會從新的請求開始。這就是 RedirectMiddleware 中間件怎樣處理重定向的,這個功能我們稍后會用到。
如果你對于有那么多的中間件默認是開啟的感到驚訝的話,那么你可能有興趣看看 體系架構概覽。實際上同時還有很多其他的事情在進行,但是,再說一次,scrapy的最大優(yōu)點之一就是你不需要知道它的大部分原理。你甚至不需要知道下載中間件的存在,卻能寫一個實用的爬蟲,你不必知道其他部分就可以寫一個實用的下載中間件。
困難的問題
回到我們的爬蟲上來,我們發(fā)現我們被重定向到某個 threat_defense.php?defense=1&... URL上,而不是我們要找的頁面。當我們在瀏覽器里面訪問這個頁面的時候,我們看到下面的東西停留了幾秒:

在被重定向到 threat_defense.php?defense=2&... 頁面之前,會出現像下面的提示:

看看第一個頁面的源代碼就會發(fā)現,有一些 javascript 代碼負責構造一個特殊的重定向URL,并且構造瀏覽器的cookies。如果我們想要完成這個任務,那我們就必須同時解決上面這兩個問題。
接下來,當然我們也需要解決驗證碼并提交答案。如果我們碰巧弄錯了,那么我們有時會被重定向到另一個驗證碼頁面,或者我們會在類似于下面的頁面上結束訪問:
在上面的頁面中,我們需要點擊 “Click here” 鏈接來開始整個重定向的循環(huán),小菜一碟,對吧?
我們所有的問題都源于最開始的 302 重定向,因此處理它們的方法自然而然應該是做一個自定義的 重定向中間件。我們想讓我們的中間件在所有情況下都像是正常重定向中間件一樣,除非有一個 302 狀態(tài)碼并且請求被重定向到 threat_defense.php 頁面。當它遇到特殊的 302 狀態(tài)碼時,我們希望它能夠繞過所有的防御機制,把訪問cookie添加到 session 會話中,最后重新請求原來的頁面。如果我們能夠做到這一點,那么我們的Spider類就不必知道這些事情,因為請求會全部成功。
打開 zipru_scraper/middlewares.py 文件,并且把內容替換成下面的代碼:
- import os, tempfile, time, sys, logging
- logger = logging.getLogger(__name__)
- import dryscrape
- import pytesseract
- from PIL import Image
- from scrapy.downloadermiddlewares.redirect import RedirectMiddleware
- class ThreatDefenceRedirectMiddleware(RedirectMiddleware):
- def _redirect(self, redirected, request, spider, reason):
- # act normally if this isn't a threat defense redirect
- if not self.is_threat_defense_url(redirected.url):
- return super()._redirect(redirected, request, spider, reason)
- logger.debug(f'Zipru threat defense triggered for {request.url}')
- request.cookies = self.bypass_threat_defense(redirected.url)
- request.dont_filter = True # prevents the original link being marked a dupe
- return request
- def is_threat_defense_url(self, url):
- return '://zipru.to/threat_defense.php' in url
你可能注意到我們繼承了 RedirectMiddleware 類,而不是直接繼承 DownloaderMiddleware 類。這樣就允許我們重用大部分的重定向處理函數,并且把我們的代碼插入到 _redirect(redirected, request, spider, reason) 函數中,一旦有重定向的請求被創(chuàng)建,process_response(request, response, spider) 函數就會調用這個函數。我們只是把對于普通的重定向的處理推遲到父類進行處理,但是對于特殊的威脅防御重定向的處理是不一樣的。我們到目前為止還沒有實現 bypass_threat_defense(url) 方法,但是我們可以知道它應該返回訪問cookies,并把它附加到原來的請求中,然后原來的請求將被重新處理。
為了開啟我們新的中間件,我們需要把下面的內容添加到 zipru_scraper/settings.py中:
- DOWNLOADER_MIDDLEWARES = {
- 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None,
- 'zipru_scraper.middlewares.ThreatDefenceRedirectMiddleware': 600,
- }
這會禁用默認的重定向中間件,并且把我們的中間件添加在中間件堆棧中和默認重定向中間件相同的位置。我們必須安裝一些額外的包,雖然我們現在沒有用到,但是稍后我們會導入它們:
- pip install dryscrape # headless webkit
- pip install Pillow # image processing
- pip install pytesseract # OCR
請注意,這三個包都有 pip 無法處理的外部依賴,如果你運行出錯,那么你可能需要訪問 dryscrape, Pillow, 和 pytesseract 的安裝教程,遵循平臺的具體說明來解決。
我們的中間件現在應該能夠替代原來的標準重定向中間件,現在我們只需要實現 bypass_thread_defense(url) 方法。我們可以解析 javascript 代碼來得到我們需要的變量,然后用 python 重建邏輯,但這看起來很不牢靠,而且需要大量的工作。讓我們采用更簡單的方法,盡管可能還是比較笨重,使用無頭的 webkit 實例。有幾個不同選擇,但我個人比較喜歡 dryscrape (我們已經在上面安裝了)
首先,讓我們在中間件構造函數中初始化一個 dryscrape 會話。
- def __init__(self, settings):
- super().__init__(settings)
- # start xvfb to support headless scraping
- if 'linux' in sys.platform:
- dryscrape.start_xvfb()
- self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
你可以把這個會話對象當做是一個單獨的瀏覽器標簽頁,它可以完成一切瀏覽器通常可以做的事情(例如:獲取外部資源,執(zhí)行腳本)。我們可以在新的標簽頁中打開新的 URL 鏈接,點擊一些東西,或者在輸入框中輸入內容,或是做其他的各種事情。Scrapy 支持并發(fā)請求和多項處理,但是響應的處理是單線程的。這意味著我們可以使用這個單獨的 dryscrapy 會話,而不必擔心線程安全。
現在讓我們實現繞過威脅防御機制的基本邏輯。
- def bypass_threat_defense(self, url=None):
- # only navigate if any explicit url is provided
- if url:
- self.dryscrape_session.visit(url)
- # solve the captcha if there is one
- captcha_images = self.dryscrape_session.css('img[src *= captcha]')
- if len(captcha_images) > 0:
- return self.solve_captcha(captcha_images[0])
- # click on any explicit retry links
- retry_links = self.dryscrape_session.css('a[href *= threat_defense]')
- if len(retry_links) > 0:
- return self.bypass_threat_defense(retry_links[0].get_attr('href'))
- # otherwise, we're on a redirect page so wait for the redirect and try again
- self.wait_for_redirect()
- return self.bypass_threat_defense()
- def wait_for_redirect(self, url = None, wait = 0.1, timeout=10):
- url = url or self.dryscrape_session.url()
- for i in range(int(timeout//wait)):
- time.sleep(wait)
- if self.dryscrape_session.url() != url:
- return self.dryscrape_session.url()
- logger.error(f'Maybe {self.dryscrape_session.url()} isn\'t a redirect URL?')
- raise Exception('Timed out on the zipru redirect page.')
這樣就處理了我們在瀏覽器中遇到的所有不同的情況,并且完全符合人類在每種情況中的行為。在任何給定情況下采取的措施都取決于當前頁面的情況,所以這種方法可以稍微優(yōu)雅一點地處理各種不同的情況。
最后一個難題是如果如何解決驗證碼。網上提供了 驗證碼識別 服務,你可以在必要時使用它的API,但是這次的這些驗證碼非常簡單,我們只用 OCR 就可以解決它。使用 pytessertact 的 OCR 功能,最后我們可以添加 solve_captcha(img) 函數,這樣就完善了 bypass_threat_defense() 函數。
- def solve_captcha(self, img, width=1280, height=800):
- # take a screenshot of the page
- self.dryscrape_session.set_viewport_size(width, height)
- filename = tempfile.mktemp('.png')
- self.dryscrape_session.render(filename, width, height)
- # inject javascript to find the bounds of the captcha
- js = 'document.querySelector("img[src *= captcha]").getBoundingClientRect()'
- rect = self.dryscrape_session.eval_script(js)
- box = (int(rect['left']), int(rect['top']), int(rect['right']), int(rect['bottom']))
- # solve the captcha in the screenshot
- image = Image.open(filename)
- os.unlink(filename)
- captcha_image = image.crop(box)
- captcha = pytesseract.image_to_string(captcha_image)
- logger.debug(f'Solved the Zipru captcha: "{captcha}"')
- # submit the captcha
- input = self.dryscrape_session.xpath('//input[@id = "solve_string"]')[0]
- input.set(captcha)
- button = self.dryscrape_session.xpath('//button[@id = "button_submit"]')[0]
- url = self.dryscrape_session.url()
- button.click()
- # try again if it we redirect to a threat defense URL
- if self.is_threat_defense_url(self.wait_for_redirect(url)):
- return self.bypass_threat_defense()
- # otherwise return the cookies as a dict
- cookies = {}
- for cookie_string in self.dryscrape_session.cookies():
- if 'domain=zipru.to' in cookie_string:
- key, value = cookie_string.split(';')[0].split('=')
- cookies[key] = value
- return cookies
你可能注意到如果驗證碼因為某些原因識別失敗的話,它就會委托給 back to the bypass_threat_defense() 函數。這樣就給了我們多次識別驗證碼的機會,但重點是,我們會在得到正確結果之前一直在驗證碼識別過程中循環(huán)。
這應該足夠讓我們的爬蟲工作,但是它有可能陷入死循環(huán)中。
- [scrapy.core.engine] DEBUG: Crawled (200) <GET http://zipru.to/robots.txt> (referer: None)
- [zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
- [zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "UJM39"
- [zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
- [zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "TQ9OG"
- [zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
- [zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "KH9A8"
- ...
至少看起來我們的中間件已經成功地解決了驗證碼,然后補發(fā)了請求。問題在于,新的請求再次觸發(fā)了威脅防御機制。我第一個想法是我可能在怎樣解析或是添加cookie上面有錯誤,但是我檢查了三次,代碼是正確的。這是另外一種情況 “唯一可能不同的事情就是請求頭” 。
很明顯,scrapy 和 dryscrape 的請求頭都繞過了最初的觸發(fā) 403 響應的過濾器,因為我們現在不會得到任何 403 的響應。這肯定是因為它們的請求頭信息不一致導致的。我的猜測是其中一個加密的訪問cookies包含了整個請求頭信息的散列值,如果這個散列不匹配,就會觸發(fā)威脅防御機制。這樣的目的可能是防止有人把瀏覽器的cookie復制到爬蟲中去,但是它只是增加了你需要解決的問題而已。
所以讓我們在 zipru_scraper/settings.py 中把請求頭信息修改成下面這個樣子。
- DEFAULT_REQUEST_HEADERS = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
- 'User-Agent': USER_AGENT,
- 'Connection': 'Keep-Alive',
- 'Accept-Encoding': 'gzip, deflate',
- 'Accept-Language': 'en-US,*',
- }
注意我們已經把 User-Agent 頭信息修改成了我們之前定義的 USER_AGENT 中去.這個工作是由 user agent 中間件自動添加進去的,但是把所有的這些配置放到一個地方可以使得 dryscrape 更容易復制請求頭信息。我們可以通過修改 ThreatDefenceRedirectMiddleware 初始化函數像下面這樣:
- def __init__(self, settings):
- super().__init__(settings)
- # start xvfb to support headless scraping
- if 'linux' in sys.platform:
- dryscrape.start_xvfb()
- self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
- for key, value in settings['DEFAULT_REQUEST_HEADERS'].items():
- # seems to be a bug with how webkit-server handles accept-encoding
- if key.lower() != 'accept-encoding':
- self.dryscrape_session.set_header(key, value)
現在,當我們可以通過命令 scrapy crawl zipru -o torrents.jl 再次運行爬蟲。我們可以看到源源不斷的爬取的內容,并且我們的 torrents.jl 文件記錄把爬取的內容全部記錄了下來。我們已經成功地繞過了所有的威脅防御機制。
總結
我們已經成功地寫了一個能夠解決四種截然不同的威脅防御機制的爬蟲,這四種防御機制分別是:
- User agent 過濾
- 模糊的 Javascript 重定向
- 驗證碼
- 請求頭一致性檢查
我們的目標網站 Zipru 可能是虛構的,但是這些機制都是你會在真實網站上遇到的真實的反爬蟲技術。希望我們使用的方法對你自己爬蟲中遇到的挑戰(zhàn)有幫助。