一文學(xué)會(huì)爬蟲(chóng)技巧
前言
作為冷數(shù)據(jù)啟動(dòng)和豐富數(shù)據(jù)的重要工具,爬蟲(chóng)在業(yè)務(wù)發(fā)展中承擔(dān)著重要的作用,我們業(yè)務(wù)在發(fā)展過(guò)程中積累了不少爬蟲(chóng)使用的經(jīng)驗(yàn),在此分享給大家,希望能對(duì)之后的業(yè)務(wù)發(fā)展提供一些技術(shù)選型方向上的思路,以更好地促進(jìn)業(yè)務(wù)發(fā)展
我們將會(huì)從以下幾點(diǎn)來(lái)分享我們的經(jīng)驗(yàn)
- 爬蟲(chóng)的應(yīng)用場(chǎng)景
- 爬蟲(chóng)的技術(shù)選型
- 實(shí)戰(zhàn)詳解:復(fù)雜場(chǎng)景下的爬蟲(chóng)解決方案
- 爬蟲(chóng)管理平臺(tái)
爬蟲(chóng)的應(yīng)用場(chǎng)景
在生產(chǎn)上,爬蟲(chóng)主要應(yīng)用在以下幾種場(chǎng)景
- 搜索引擎,Google,百度這種搜索引擎公司每天啟動(dòng)著無(wú)數(shù)的爬蟲(chóng)去抓取網(wǎng)頁(yè)信息,才有了我們使用搜索引擎查詢資料的便捷,全面,高效(關(guān)于搜索引擎工作原理,在這篇文章作了詳細(xì)的講解,建議大家看看)
- 冷數(shù)據(jù)啟動(dòng)時(shí)豐富數(shù)據(jù)的主要工具,新業(yè)務(wù)開(kāi)始時(shí),由于剛起步,所以沒(méi)有多少數(shù)據(jù),此時(shí)就需要爬取其他平臺(tái)的數(shù)據(jù)來(lái)填充我們的業(yè)務(wù)數(shù)據(jù),比如說(shuō)如果我們想做一個(gè)類似大眾點(diǎn)評(píng)這樣的平臺(tái),一開(kāi)始沒(méi)有商戶等信息,就需要去爬取大眾,美團(tuán)等商家的信息來(lái)填充數(shù)據(jù)
- 數(shù)據(jù)服務(wù)或聚合的公司,比如天眼查,企查查,西瓜數(shù)據(jù)等等
- 提供橫向數(shù)據(jù)比較,聚合服務(wù),比如說(shuō)電商中經(jīng)常需要有一種比價(jià)系統(tǒng),從各大電商平臺(tái),如拼多多,淘寶,京東等抓取同一個(gè)商品的價(jià)格信息,以給用戶提供最實(shí)惠的商品價(jià)格,這樣就需要從各大電商平臺(tái)爬取信息。
- 黑產(chǎn),灰產(chǎn),風(fēng)控等,比如我們要向某些資金方申請(qǐng)授信,在資金方這邊首先要部署一道風(fēng)控,來(lái)看你的個(gè)人信息是否滿足授信條件,這些個(gè)人信息通常是某些公司利用爬蟲(chóng)技術(shù)在各個(gè)渠道爬取而來(lái)的,當(dāng)然了這類場(chǎng)景還是要慎用,不然正應(yīng)了那句話「爬蟲(chóng)用的好,監(jiān)控進(jìn)得早」
爬蟲(chóng)的技術(shù)選型
接下來(lái)我們就由淺入深地為大家介紹爬蟲(chóng)常用的幾種技術(shù)方案
簡(jiǎn)單的爬蟲(chóng)說(shuō)起爬蟲(chóng),大家可能會(huì)覺(jué)得技術(shù)比較高深,會(huì)立刻聯(lián)想到使用像 Scrapy 這樣的爬蟲(chóng)框架,這類框架確實(shí)很強(qiáng)大,那么是不是一寫爬蟲(chóng)就要用框架呢?非也!要視情況而定,如果我們要爬取的接口返回的只是很簡(jiǎn)單,固定的結(jié)構(gòu)化數(shù)據(jù)(如JSON),用 Scrapy 這類框架的話有時(shí)無(wú)異于殺雞用牛刀,不太經(jīng)濟(jì)!
舉個(gè)簡(jiǎn)單的例子,業(yè)務(wù)中有這么一個(gè)需求:需要抓取育學(xué)園中準(zhǔn)媽媽從「孕4周以下」~「孕36個(gè)月以上」每個(gè)階段的數(shù)據(jù)

對(duì)于這種請(qǐng)求,bash 中的 curl 足堪大任!
首先我們用 charles 等抓包工具抓取此頁(yè)面接口數(shù)據(jù),如下

通過(guò)觀察,我們發(fā)現(xiàn)請(qǐng)求的數(shù)據(jù)中只有 month 的值(代表孕幾周)不一樣,所以我們可以按以下思路來(lái)爬取所有的數(shù)據(jù):
1、 找出所有「孕4周以下」~「孕36個(gè)月以上」對(duì)應(yīng)的 month 的值,構(gòu)建一個(gè) month 數(shù)組 2、 構(gòu)建一個(gè)以 month 值為變量的 curl 請(qǐng)求,在 charles 中 curl 請(qǐng)求我們可以通過(guò)如下方式來(lái)獲取
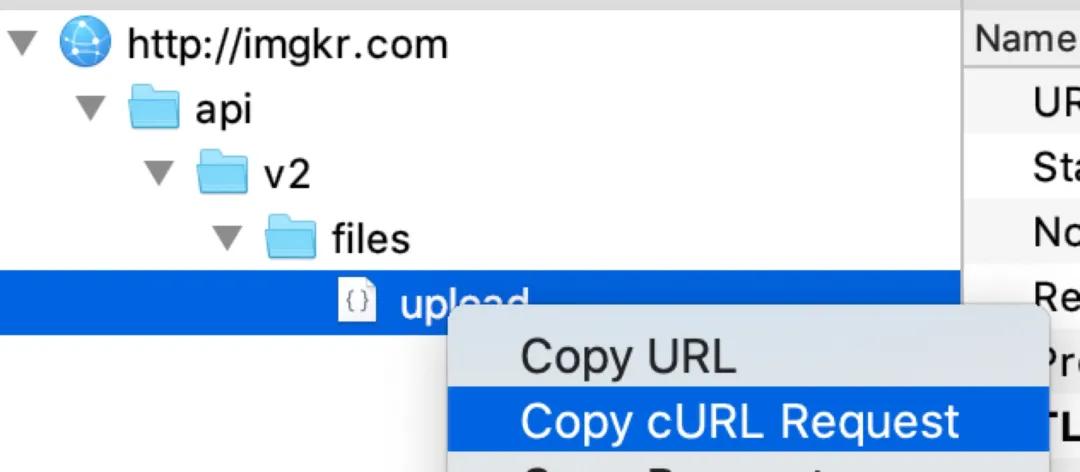
3、 依次遍歷步驟 1 中的 month,每遍歷一次,就用步驟 2 中的 curl 和 month 變量構(gòu)建一個(gè)請(qǐng)求并執(zhí)行,將每次的請(qǐng)求結(jié)果保存到一個(gè)文件中(對(duì)應(yīng)每個(gè)孕期的 month 數(shù)據(jù)),這樣之后就可以對(duì)此文件中的數(shù)據(jù)進(jìn)行解析分析。
示例代碼如下,為了方便演示,中間 curl 代碼作了不少簡(jiǎn)化,大家明白原理就好
- #!/bin/bash
- ## 獲取所有孕周對(duì)應(yīng)的 month,這里為方便演示,只取了兩個(gè)值
- month=(21 24)
- ## 遍歷所有 month,組裝成 curl 請(qǐng)求
- for month in ${month[@]};
- do
- curl -H 'Host: yxyapi2.drcuiyutao.com'
- -H 'clientversion: 7.14.1'
- ...
- -H 'birthday: 2018-08-07 00:00:00'
- --data "body=month%22%3A$month" ## month作為變量構(gòu)建 curl 請(qǐng)求
- --compressed 'http://yxyapi2.drcuiyutao.com/yxy-api-gateway/api/json/tools/getBabyChange' > $var.log ## 將 curl 請(qǐng)求結(jié)果輸出到文件中以便后續(xù)分析
- done
前期我們業(yè)務(wù)用 PHP 的居多,不少爬蟲(chóng)請(qǐng)求都是在 PHP 中處理的,在 PHP 中我們也可以通過(guò)調(diào)用 libcurl 來(lái)模擬 bash 中的 curl 請(qǐng)求,比如業(yè)務(wù)中有一個(gè)需要抓取每個(gè)城市的天氣狀況的需求,就可以用 PHP 調(diào)用 curl,一行代碼搞定!

看了兩個(gè)例子,是否覺(jué)得爬蟲(chóng)不過(guò)如此,沒(méi)錯(cuò),業(yè)務(wù)中很多這種簡(jiǎn)單的爬蟲(chóng)實(shí)現(xiàn)可以應(yīng)付絕大多數(shù)場(chǎng)景的需求!
腦洞大開(kāi)的爬蟲(chóng)解決思路
按以上介紹的爬蟲(chóng)思路可以解決日常多數(shù)的爬蟲(chóng)需求,但有時(shí)候我們需要一些腦洞大開(kāi)的思路,簡(jiǎn)單列舉兩個(gè)
1、 去年運(yùn)營(yíng)同學(xué)給了一個(gè)天貓精選的有關(guān)奶粉的 url 的鏈接
- https://m.tmall.com/mblist/de_9n40_AVYPod5SU93irPS-Q.html,他們希望能提取此文章的信息,同時(shí)找到天貓精選中所有提到奶粉關(guān)鍵字的文章并提取其內(nèi)容, 這就需要用到一些搜索引擎的高級(jí)技巧了, 我們注意到,天貓精選的 url 是以以下形式構(gòu)成的
- https://m.tmall.com/mblist/de_ + 每篇文章獨(dú)一無(wú)二的簽名
利用搜索引擎技巧我們可以輕松搞定運(yùn)營(yíng)的這個(gè)需求
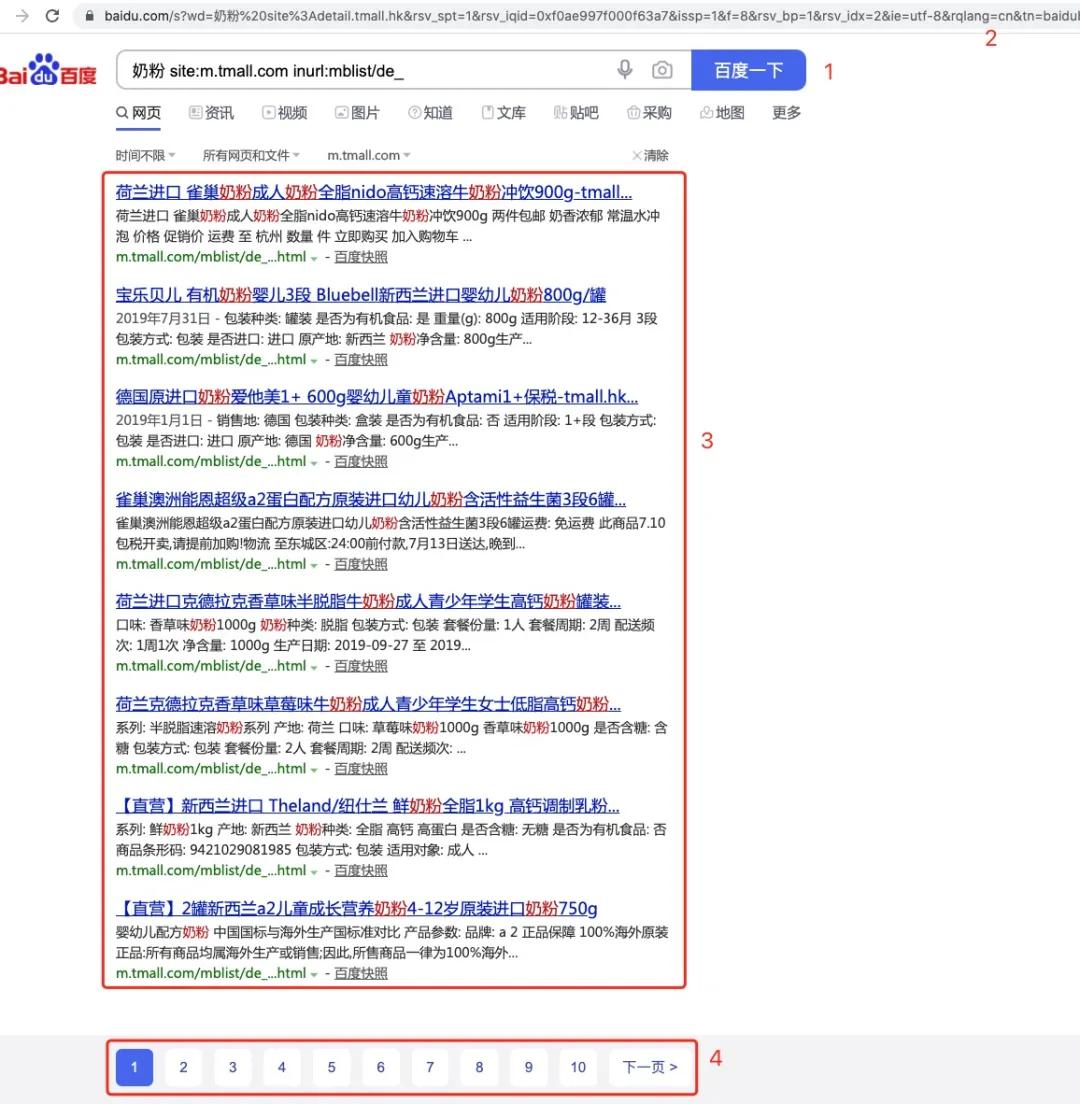
對(duì)照?qǐng)D片,步驟如下:
- 首先我們用在百度框輸入高級(jí)查詢語(yǔ)句「奶粉 site:m.tmall.com inurl:mblist/de_」,點(diǎn)擊搜索,就會(huì)顯示出此頁(yè)中所有天貓精選中包含奶粉的文章 title
- 注意地址欄中瀏覽器已經(jīng)生成了搜索的完整 url,拿到這個(gè) url 后,我們就可以去請(qǐng)求此 url,此時(shí)會(huì)得到上圖中包含有 3, 4 這兩塊的 html 文件
- 拿到步驟 2 中獲取的 html 文件后,在區(qū)域 3 每一個(gè)標(biāo)題其實(shí)對(duì)應(yīng)著一個(gè) url(以 ..... )的形式存在,根據(jù)正則表達(dá)式就可以獲取每個(gè)標(biāo)題對(duì)應(yīng)的 url,再請(qǐng)求這些 url 即可獲取對(duì)應(yīng)的文章信息。
- 同理,拿到步驟 2 中獲取的 html 文件后,我們可以獲取區(qū)域 4 每一頁(yè)對(duì)應(yīng)的 url,再依次請(qǐng)求這些 url,然后重復(fù)步驟 2,即可獲取每一頁(yè)天貓精選中包含有奶粉的文章
通過(guò)這種方式我們也巧妙地實(shí)現(xiàn)了運(yùn)營(yíng)的需求,這種爬蟲(chóng)獲取的數(shù)據(jù)是個(gè) html 文件,不是 JSON 這些結(jié)構(gòu)化數(shù)據(jù),我們需要從 html 中提取出相應(yīng)的 url 信息(存在 標(biāo)簽里),可以用正則,也可以用 xpath 來(lái)提取。
比如 html 中有如下 div 元素
- <div id="test1">大家好!</div>
- data = selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把「大家好!」提取出來(lái),需要注意的是在這種場(chǎng)景中,「依然不需要使用 Scrapy 這種復(fù)雜的框架」,在這種場(chǎng)景下,由于數(shù)據(jù)量不大,使用單線程即可滿足需求,在實(shí)際生產(chǎn)上我們用 php 實(shí)現(xiàn)即可滿足需求
2、 某天運(yùn)營(yíng)同學(xué)又提了一個(gè)需求,想爬取美拍的視頻
通過(guò)抓包我們發(fā)現(xiàn)美拍每個(gè)視頻的 url 都很簡(jiǎn)單,輸入到瀏覽器查看也能正常看視頻,于是我們想當(dāng)然地認(rèn)為直接通過(guò)此 url 即可下載視頻,但實(shí)際我們發(fā)現(xiàn)此 url 是分片的(m3u8,為了優(yōu)化加載速度而設(shè)計(jì)的一種播放多媒體列表的檔案格式),下載的視頻不完整,后來(lái)我們發(fā)現(xiàn)打開(kāi)`http://www.flvcd.com/`網(wǎng)站
輸入美拍地址轉(zhuǎn)化一下就能拿到完整的視頻下載地址

「如圖示:點(diǎn)擊「開(kāi)始GO!」后就會(huì)開(kāi)始解析視頻地址并拿到完整的視頻下載地址」
進(jìn)一步分析這個(gè)「開(kāi)始GO!」按鈕對(duì)應(yīng)的請(qǐng)求是「http://www.flvcd.com/parse.php?format=&kw= + 視頻地址」,所以只要拿到美拍的視頻地址,再調(diào)用 flvcd 的視頻轉(zhuǎn)換請(qǐng)求即可拿到完整的視頻下載地址,通過(guò)這種方式我們也解決了無(wú)法拿到美拍完整地址的問(wèn)題。
復(fù)雜的爬蟲(chóng)設(shè)計(jì)
上文我們要爬取的數(shù)據(jù)相對(duì)比較簡(jiǎn)單, 數(shù)據(jù)屬于拿來(lái)即用型,實(shí)際上我們要爬取的數(shù)據(jù)大部分是非結(jié)構(gòu)化數(shù)據(jù)(html 網(wǎng)頁(yè)等),需要對(duì)這些數(shù)據(jù)做進(jìn)一步地處理(爬蟲(chóng)中的數(shù)據(jù)清洗階段),而且每個(gè)我們爬取的數(shù)據(jù)中也很有可能包含著大量待爬取網(wǎng)頁(yè)的 url,也就是說(shuō)需要有 url 隊(duì)列管理,另外請(qǐng)求有時(shí)候還需求登錄,每個(gè)請(qǐng)求也需要添加 Cookie,也就涉及到 Cookie 的管理,在這種情況下考慮 Scrapy 這樣的框架是必要的!不管是我們自己寫的,還是類似 Scrapy 這樣的爬蟲(chóng)框架,基本上都離不開(kāi)以下模塊的設(shè)計(jì)
- url 管理器
- 網(wǎng)頁(yè)(HTML)下載器, 對(duì)應(yīng) Python 中的urllib2, requests等庫(kù)
- (HTML)解析器,主要有兩種方式來(lái)解析
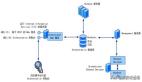
下圖詳細(xì)解釋了各個(gè)模塊之間是如何配合使用的
- 正則表達(dá)式
- 以css, xpath為代表的結(jié)構(gòu)化解析(即將文檔以DOM樹(shù)的形式重新組織,通過(guò)查找獲取節(jié)點(diǎn)進(jìn)而提取數(shù)據(jù)的方式), Python中的 html.parser,BeautifulSoup,lxml 皆是此類范疇
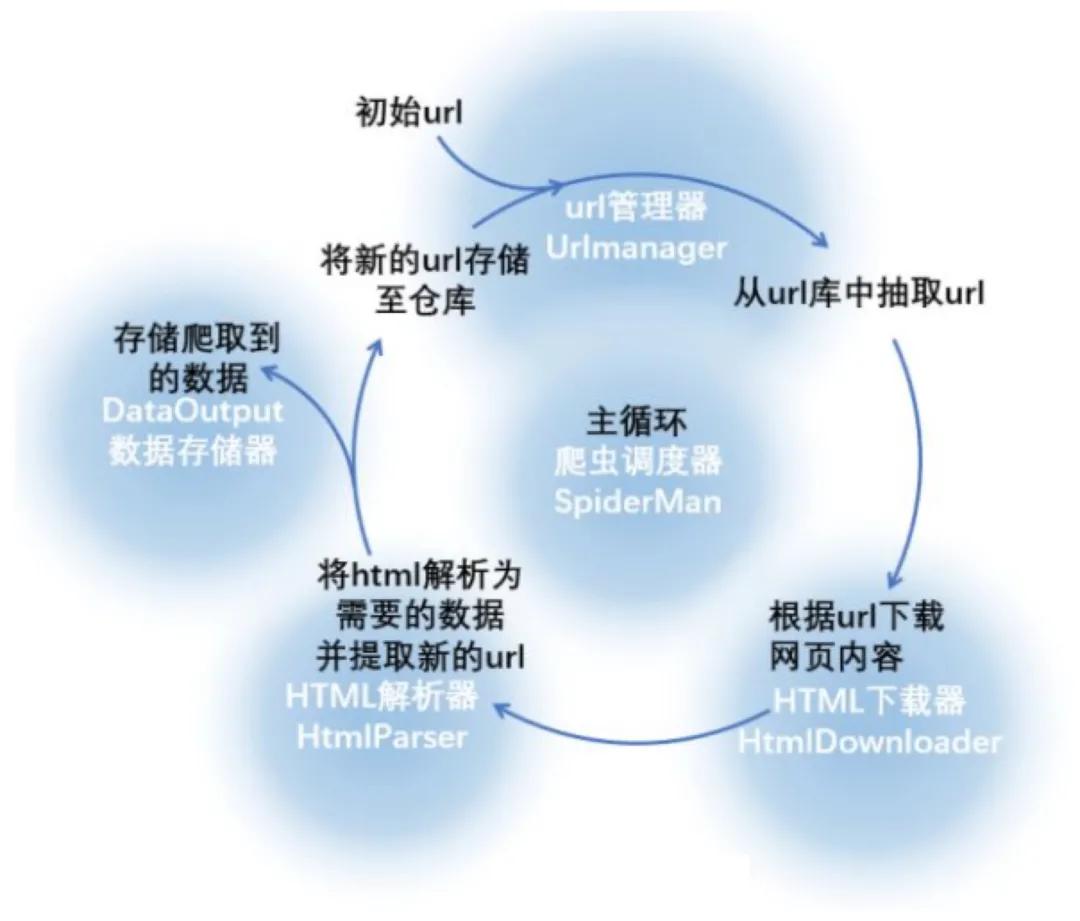
- 首先調(diào)度器會(huì)詢問(wèn) url 管理器是否有待爬取的 url
- 如果有,則獲取出其中的 url 傳給下載器進(jìn)行下載
- 下載器下載完內(nèi)容后會(huì)將其傳給解析器做進(jìn)一步的數(shù)據(jù)清洗,這一步除了會(huì)提取出有價(jià)值的數(shù)據(jù),還會(huì)提取出待爬取的URL以作下一次的爬取
- 調(diào)度器將待爬取的URL放到URL管理器里,將有價(jià)值的數(shù)據(jù)入庫(kù)作后續(xù)的應(yīng)用
- 以上過(guò)程會(huì)一直循環(huán),直到再無(wú)待爬取URL
可以看到,像以上的爬蟲(chóng)框架,如果待爬取 URL 很多,要下載,解析,入庫(kù)的工作就很大(比如我們有個(gè)類似大眾點(diǎn)評(píng)的業(yè)務(wù),需要爬取大眾點(diǎn)評(píng)的數(shù)據(jù),由于涉及到幾百萬(wàn)量級(jí)的商戶,評(píng)論等爬取,數(shù)據(jù)量巨大!),就會(huì)涉及到多線程,分布式爬取,用 PHP 這種單線程模型的語(yǔ)言來(lái)實(shí)現(xiàn)就不合適了,Python 由于其本身支持多線程,協(xié)程等特性,來(lái)實(shí)現(xiàn)這些比較復(fù)雜的爬蟲(chóng)設(shè)計(jì)就綽綽有余了,同時(shí)由于 Python 簡(jiǎn)潔的語(yǔ)法特性,吸引了一大波人寫了很多成熟的庫(kù),各種庫(kù)拿來(lái)即用,很是方便,大名鼎鼎的 Scrapy 框架就是由于其豐富的插件,易用性俘獲了大批粉絲,我們的大部分爬蟲(chóng)業(yè)務(wù)都是用的scrapy來(lái)實(shí)現(xiàn)的,所以接下來(lái)我們就簡(jiǎn)要介紹一下 Scrapy,同時(shí)也來(lái)看看一個(gè)成熟的爬蟲(chóng)框架是如何設(shè)計(jì)的。
我們首先要考慮一下爬蟲(chóng)在爬取數(shù)據(jù)過(guò)程中會(huì)可能會(huì)碰到的一些問(wèn)題,這樣才能明白框架的必要性以后我們自己設(shè)計(jì)框架時(shí)該考慮哪些點(diǎn)
- url 隊(duì)列管理:比如如何防止對(duì)同一個(gè) url 重復(fù)爬取(去重),如果是在一臺(tái)機(jī)器上可能還好,如果是分布式爬取呢
- Cookie 管理:有一些請(qǐng)求是需要帳號(hào)密碼驗(yàn)證的,驗(yàn)證之后需要用拿到的 Cookie 來(lái)訪問(wèn)網(wǎng)站后續(xù)的頁(yè)面請(qǐng)求,如何緩存住 Cookie 以便后續(xù)進(jìn)一步的操作
- 多線程管理:前面說(shuō)了如果待爬取URL很多的話,加載解析的工作是很大的,單線程爬取顯然不可行,那如果用多線程的話,管理又是一件大麻煩
- User-Agent 與動(dòng)態(tài)代理的管理: 目前的反爬機(jī)制其實(shí)也是比較完善的,如果我們用同樣的UA,同樣的IP不節(jié)制地連續(xù)對(duì)同一個(gè)網(wǎng)站多次請(qǐng)求,很可能立馬被封, 此時(shí)我們就需要使用 random-ua ,動(dòng)態(tài)代理來(lái)避免被封
- 動(dòng)態(tài)生成數(shù)據(jù)的爬取:一般通過(guò) GET 請(qǐng)求獲取的網(wǎng)頁(yè)數(shù)據(jù)是包含著我們需要的數(shù)據(jù)的,但有些數(shù)據(jù)是通過(guò) Ajax 請(qǐng)求動(dòng)態(tài)生成,這樣的話該如何爬取
- DEBUG
- 爬蟲(chóng)管理平臺(tái): 爬蟲(chóng)任務(wù)多時(shí),如何查看和管理這些爬蟲(chóng)的狀態(tài)和數(shù)據(jù)
從以上的幾個(gè)點(diǎn)我們可以看出寫一個(gè)爬蟲(chóng)框架還是要費(fèi)不少功夫的,幸運(yùn)的是,scrapy 幫我們幾乎完美地解決了以上問(wèn)題,讓我們只要專注于寫具體的解析入庫(kù)邏輯即可, 來(lái)看下它是如何實(shí)現(xiàn)以上的功能點(diǎn)的
- url 隊(duì)列管理: 使用 scrapy-redis 插件來(lái)做 url 的去重處理,利用 redis 的原子性可以輕松處理url重復(fù)問(wèn)題
- Cookie管理: 只要做一次登錄校驗(yàn),就會(huì)緩存住Cookie,在此后的請(qǐng)求中自動(dòng)帶上此Cookie,省去了我們自己管理的煩惱
- 多線程管理: 只要在中間件中指定線程次數(shù)CONCURRENT_REQUESTS = 3,scrapy就可以為我們自己管理多線程操作,無(wú)需關(guān)心任何的線程創(chuàng)建毀滅生命周期等復(fù)雜的邏輯
- User-Agent與動(dòng)態(tài)代理的管理: 使用random-useragent插件為每一次請(qǐng)求隨機(jī)設(shè)置一個(gè)UA,使用螞蟻(mayidaili.com)等代理為每一個(gè)請(qǐng)求頭都加上proxy這樣我們的 UA 和 IP 每次就基本都不一樣了,避免了被封的窘境
- 動(dòng)態(tài)數(shù)據(jù)(通過(guò) ajax 等生成)爬取: 使用Selenium + PhantomJs來(lái)抓取抓動(dòng)態(tài)數(shù)據(jù)
- DEBUG: 如何有效測(cè)試爬取數(shù)據(jù)是否正確非常重要,一個(gè)不成熟的框架很可能在我們每次要驗(yàn)證用 xpath,正則等獲取數(shù)據(jù)是否正確時(shí)每一次都會(huì)重新去下載網(wǎng)頁(yè),效率極低,但Scray-Shell 提供了很友好的設(shè)計(jì),它會(huì)先下載網(wǎng)頁(yè)到內(nèi)存里,然后你在 shell 做各種 xpath 的調(diào)試,直到測(cè)試成功!
- 使用 SpiderKeeper+Scrapyd 來(lái)管理爬蟲(chóng), GUI 操作,簡(jiǎn)單易行
可以看到 Scrapy 解決了以上提到的主要問(wèn)題,在爬取大量數(shù)據(jù)時(shí)能讓我們專注于寫爬蟲(chóng)的業(yè)務(wù)邏輯,無(wú)須關(guān)注 Cookie 管理,多線程管理等細(xì)節(jié),極大地減輕了我們的負(fù)擔(dān),很容易地做到事半功倍!
(注意! Scrapy 雖然可以使用 Selenium + PhantomJs 來(lái)抓取動(dòng)態(tài)數(shù)據(jù),但隨著 Google 推出的 puppeter 的橫空出世,PhantomJs 已經(jīng)停止更新了,因?yàn)?Puppeter 比 PhantomJS 強(qiáng)大太多,所以如果需要大量地抓取動(dòng)態(tài)數(shù)據(jù),需要考慮性能方面的影響,Puppeter 這個(gè) Node 庫(kù)絕對(duì)值得一試,Google 官方出品,強(qiáng)烈推薦)
理解了 Scrapy 的主要設(shè)計(jì)思路與功能,我們?cè)賮?lái)看下如何用 Scrapy 來(lái)開(kāi)發(fā)我們某個(gè)音視頻業(yè)務(wù)的爬蟲(chóng)項(xiàng)目,來(lái)看一下做一個(gè)音視頻爬蟲(chóng)會(huì)遇到哪些問(wèn)題
音視頻爬蟲(chóng)實(shí)戰(zhàn)
一、先從幾個(gè)方面來(lái)簡(jiǎn)單介紹我們音視頻爬蟲(chóng)項(xiàng)目的體系
1、四個(gè)主流程
- 爬取階段
- 資源處理(包括音頻,視頻,圖片下載及處理)
- 正式入庫(kù)
- 后處理階段(類似去水印)
2、目前支持的功能點(diǎn)
- 各類視頻音頻站點(diǎn)的爬取(喜馬拉雅,愛(ài)奇藝,優(yōu)酷,騰訊,兒歌點(diǎn)點(diǎn)等)
- 主流視頻音頻站點(diǎn)的內(nèi)容同步更新(喜馬拉雅,優(yōu)酷)
- 視頻去水印(視頻 logo)
- 視頻截圖(視頻內(nèi)容無(wú)封面)
- 視頻轉(zhuǎn)碼適配(flv 目前客戶端不支持)
3、體系流程分布圖

二、分步來(lái)講下細(xì)節(jié)
1. 爬蟲(chóng)框架的技術(shù)選型
說(shuō)到爬蟲(chóng),大家應(yīng)該會(huì)很自然與 python 劃上等號(hào),所以我們的技術(shù)框架就從 python 中比較脫穎而出的三方庫(kù)選。scrapy 就是非常不錯(cuò)的一款。相信很多其他做爬蟲(chóng)的小伙伴也都體驗(yàn)過(guò)這個(gè)框架。
那么說(shuō)說(shuō)這個(gè)框架用了這么久感受最深的幾個(gè)優(yōu)點(diǎn):
- request 觸發(fā)底層采用的是 python 自帶的 yied 協(xié)程,可以節(jié)省內(nèi)容的同時(shí),回調(diào)式的編程方式也顯得優(yōu)雅舒適
- 對(duì)于 html 內(nèi)容的高效篩選處理能力,selecter 的 xpath 真的很好用
- 由于迭代時(shí)間已經(jīng)很長(zhǎng)了,具備了很完善的擴(kuò)展 api,例如:middlewares 就可以全局 hook 很多事件點(diǎn),動(dòng)態(tài) ip 代理就可以通過(guò) hook request_start 實(shí)現(xiàn)
2. 爬蟲(chóng)池 db 的設(shè)計(jì)
爬蟲(chóng)池 db 對(duì)于整個(gè)爬取鏈路來(lái)說(shuō)是非常重要的關(guān)鍵存儲(chǔ)節(jié)點(diǎn),所以在早教這邊也是經(jīng)歷了很多次的字段更迭。
最初我們的爬蟲(chóng)池 db 表只是正式表的一份拷貝,存儲(chǔ)內(nèi)容完全相同,在爬取完成后,copy 至正式表,然后就失去相應(yīng)的關(guān)聯(lián)。這時(shí)候的爬蟲(chóng)池完全就是一張草稿表,里面有很多無(wú)用的數(shù)據(jù)。
后來(lái)發(fā)現(xiàn)運(yùn)營(yíng)需要看爬蟲(chóng)的具體來(lái)源,這時(shí)候爬蟲(chóng)池里面即沒(méi)有網(wǎng)站源鏈接,也無(wú)法根據(jù)正式表的專輯 id 對(duì)應(yīng)到爬蟲(chóng)池的數(shù)據(jù)內(nèi)容。所以,爬蟲(chóng)池 db 做出了最重要的一次改動(dòng)。首先是建立爬蟲(chóng)池?cái)?shù)據(jù)與爬取源站的關(guān)聯(lián),即source_link 與 source_from 字段,分別代表內(nèi)容對(duì)應(yīng)的網(wǎng)站原鏈接以及來(lái)源聲明定義。第二步則是建立爬蟲(chóng)池內(nèi)容與正式庫(kù)內(nèi)容的關(guān)聯(lián),為了不影響正式庫(kù)數(shù)據(jù),我們添加 target_id 對(duì)應(yīng)到正式庫(kù)的內(nèi)容 id 上。此時(shí),就可以滿足告知運(yùn)營(yíng)爬取內(nèi)容具體來(lái)源的需求了。
后續(xù)運(yùn)營(yíng)則發(fā)現(xiàn),在大量的爬蟲(chóng)數(shù)據(jù)中篩選精品內(nèi)容需要一些源站數(shù)據(jù)的參考值,例如:源站播放量等,此時(shí)爬蟲(chóng)池db 和正式庫(kù) db 存儲(chǔ)內(nèi)容正式分化,爬蟲(chóng)池不再只是正式庫(kù)的一份拷貝,而是代表源站的一些參考數(shù)據(jù)以及正式庫(kù)的一些基礎(chǔ)數(shù)據(jù)。
而后來(lái)的同步更新源站內(nèi)容功能,也是依賴這套關(guān)系可以很容易的實(shí)現(xiàn)。
整個(gè)過(guò)程中,最重要的是將本來(lái)毫無(wú)關(guān)聯(lián)的 「爬取源站內(nèi)容」 、 「爬蟲(chóng)池內(nèi)容」 、「正式庫(kù)內(nèi)容」 三個(gè)區(qū)塊關(guān)聯(lián)起來(lái)。
3. 為什么會(huì)產(chǎn)生資源處理任務(wù)
本來(lái)的話,資源的下載以及一些處理應(yīng)該是在爬取階段就可以一并完成的,那么為什么會(huì)單獨(dú)產(chǎn)生資源處理這一流程。
首先,第一版的早教爬蟲(chóng)體系里面確實(shí)沒(méi)有這一單獨(dú)的步驟,是在scrapy爬取過(guò)程中串行執(zhí)行的。但是后面發(fā)現(xiàn)的缺點(diǎn)是:
- scrapy 自帶的 download pipe 不太好用,而且下載過(guò)程中并不能并行下載,效率較低
- 由于音視頻文件較大,合并資源會(huì)有各種不穩(wěn)定因素,有較大概率出現(xiàn)下載失敗。失敗后會(huì)同步丟失掉爬取信息。
- 串行執(zhí)行的情況下,會(huì)失去很多擴(kuò)展性,重跑難度大。
針對(duì)以上的問(wèn)題,我們?cè)黾恿伺老x(chóng)表中的中間態(tài),即資源下載失敗的狀態(tài),但保留已爬取的信息。然后,增加獨(dú)立的資源處理任務(wù),采用 python 的多線程進(jìn)行資源處理。針對(duì)這些失敗的內(nèi)容,會(huì)定時(shí)跑資源處理任務(wù),直到成功為止。(當(dāng)然一直失敗的,就需要開(kāi)發(fā)根據(jù)日志排查問(wèn)題了)
4. 說(shuō)說(shuō)為什么水印處理不放在資源處理階段,而在后處理階段(即正式入庫(kù)后)
首先需要了解我們?nèi)ニ〉脑硎怯?ffmpeg 的 delogo 功能,該功能不像轉(zhuǎn)換視頻格式那樣只是更改封裝。它需要對(duì)整個(gè)視頻進(jìn)行重新編碼,所以耗時(shí)非常久,而且對(duì)應(yīng)于 cpu 的占用也很大。
基于以上,如果放在資源處理階段,會(huì)大大較低資源轉(zhuǎn)移至 upyun 的效率,而且光優(yōu)酷而言就有不止 3 種水印類型,對(duì)于整理規(guī)則而言就是非常耗時(shí)的工作了,這個(gè)時(shí)間消耗同樣會(huì)降低爬取工作的進(jìn)行。而首先保證資源入庫(kù),后續(xù)進(jìn)行水印處理,一方面,運(yùn)營(yíng)可以靈活控制上下架,另一方面,也是給了開(kāi)發(fā)人員足夠的時(shí)間去整理規(guī)則,還有就是,水印處理出錯(cuò)時(shí),還存在源視頻可以恢復(fù)。
5. 如何去除圖片水印
不少爬蟲(chóng)抓取的圖片是有水印的,目前沒(méi)發(fā)現(xiàn)完美的去水印方法,可使用的方法:
原始圖片查找,一般網(wǎng)站都會(huì)保存原始圖和加水印圖,如果找不到原始鏈接就沒(méi)辦法
裁剪法,由于水印一般是在圖片邊角,如果對(duì)于被裁減的圖片是可接受的,可以將包含水印部分直接按比例裁掉
使用 opencv 庫(kù)處理,調(diào)用 opencv 這種圖形庫(kù)進(jìn)行圖片類似PS的圖片修復(fù),產(chǎn)生的效果也差不多,遇到復(fù)雜圖形修復(fù)效果不好。
三、遇到的問(wèn)題和解決方案
資源下載階段經(jīng)常出現(xiàn)中斷或失敗等問(wèn)題【方案:將資源下載及相關(guān)處理從爬取過(guò)程中獨(dú)立出來(lái),方便任務(wù)重跑】
雖然是不同平臺(tái),但是重復(fù)資源太多,特別是視頻網(wǎng)站【方案:資源下載前根據(jù)title匹配,完全匹配則過(guò)濾,省下了多余的下載時(shí)間消耗】
大量爬取過(guò)程中,會(huì)遇到ip被封的情況【方案:動(dòng)態(tài) ip 代理】
大型視頻網(wǎng)站資源獲取規(guī)則頻繁替換(加密,視頻切割,防盜鏈等),開(kāi)發(fā)維護(hù)成本高【方案:you-get 三方庫(kù),該庫(kù)支持大量的主流視頻網(wǎng)站的爬取,大大減少開(kāi)發(fā)維護(hù)成本】
- app相關(guān)爬取被加密【方案:反編譯】
- 優(yōu)酷和騰訊視頻會(huì)有 logo【方案:ffmpeg delogo 功能】
- 爬過(guò)來(lái)的內(nèi)容沒(méi)有主播關(guān)聯(lián)像盜版【方案:在內(nèi)容正式入庫(kù)時(shí),給內(nèi)容穿上主播馬甲】
- 爬取源站內(nèi)容仍在更新中,但是我們的平臺(tái)內(nèi)容無(wú)法更新【方案:db 存入原站鏈接,根據(jù)差異性進(jìn)行更新】
- 類似優(yōu)酷,愛(ài)奇藝等主流視頻網(wǎng)站的專輯爬取任務(wù)媒介存于服務(wù)器文本文件中,并需開(kāi)發(fā)手動(dòng)命令觸發(fā),耗費(fèi)人力【方案:整合腳本邏輯,以 db 為媒介,以定時(shí)任務(wù)檢測(cè)觸發(fā)】
- 運(yùn)營(yíng)需要添加一些類似原站播放量等的數(shù)據(jù)到運(yùn)營(yíng)后臺(tái)顯示,作為審核,加精,置頂?shù)炔僮鞯囊罁?jù)【方案:之前爬蟲(chóng)表在將數(shù)據(jù)導(dǎo)入正式表后失去關(guān)聯(lián),現(xiàn)在建立起關(guān)聯(lián),在爬蟲(chóng)表添加爬蟲(chóng)原站相關(guān)數(shù)據(jù)字段】
- 由于自己的很多資源是爬過(guò)來(lái)的,所以資源的安全性和反扒就顯得很重要,那么怎么保證自己資源在接口吐出后仍然安全【方案:upyun的防盜鏈空間,該空間下的資源地址有相應(yīng)的時(shí)效性】
- 接口中沒(méi)有媒體文件相關(guān)信息,而自己平臺(tái)需要,例如:時(shí)長(zhǎng)【方案:ffmpeg 支持的媒體文件解析】
- 下載后的視頻很多在客戶端無(wú)法播放【方案:在資源上傳 upyun 前,進(jìn)行格式和碼率驗(yàn)證,不符合則進(jìn)行相應(yīng)的轉(zhuǎn)碼】
四、最后做下總結(jié)
對(duì)于我們視頻的音視頻爬蟲(chóng)代碼體系,不一定能通用于所有的業(yè)務(wù)線,但是同類問(wèn)題的思考與解決方案確是可以借鑒與應(yīng)用于各個(gè)業(yè)務(wù)線的,相信項(xiàng)目主對(duì)大家會(huì)有不少啟發(fā)
爬蟲(chóng)管理平臺(tái)
當(dāng)爬蟲(chóng)任務(wù)變得很多時(shí),ssh+crontab 的方式會(huì)變得很麻煩, 需要一個(gè)能隨時(shí)查看和管理爬蟲(chóng)運(yùn)行狀況的平臺(tái),
SpiderKeeper+Scrapyd 目前是一個(gè)現(xiàn)成的管理方案,提供了不錯(cuò)的UI界面。功能包括:
1.爬蟲(chóng)的作業(yè)管理:定時(shí)啟動(dòng)爬蟲(chóng)進(jìn)行數(shù)據(jù)抓取,隨時(shí)啟動(dòng)和關(guān)閉爬蟲(chóng)任務(wù)
2.爬蟲(chóng)的日志記錄:爬蟲(chóng)運(yùn)行過(guò)程中的日志記錄,可以用來(lái)查詢爬蟲(chóng)的問(wèn)題
3.爬蟲(chóng)運(yùn)行狀態(tài)查看:運(yùn)行中的爬蟲(chóng)和爬蟲(chóng)運(yùn)行時(shí)長(zhǎng)查看
總結(jié)
從以上的闡述中,我們可以簡(jiǎn)單地總結(jié)一下爬蟲(chóng)的技術(shù)選型
- 如果是結(jié)構(gòu)化數(shù)據(jù)(JSON 等),我們可以使用 curl,PHP 這些單線程模塊的語(yǔ)言來(lái)處理即可
- 如果是非結(jié)構(gòu)化數(shù)據(jù)(html 等),此時(shí) bash 由于無(wú)法處理這類數(shù)據(jù),需要用正則, xpath 來(lái)處理,可以用 php, BeautifulSoup 來(lái)處理,當(dāng)然這種情況僅限于待爬取的 url 較少的情況
- 如果待爬取的 url 很多,單線程無(wú)法應(yīng)付,就需要多線程來(lái)處理了,又或者需要 Cookie 管理,動(dòng)態(tài) ip 代理等,這種情況下我們就得考慮 scrapy 這類高性能爬蟲(chóng)框架了

根據(jù)業(yè)務(wù)場(chǎng)景的復(fù)雜度選擇相應(yīng)的技術(shù)可以達(dá)到事半功倍的效果。我們?cè)诩夹g(shù)選型時(shí)一定要考慮實(shí)際的業(yè)務(wù)場(chǎng)景。
本文轉(zhuǎn)載自微信公眾號(hào)「碼海」,可以通過(guò)以下二維碼關(guān)注。轉(zhuǎn)載本文請(qǐng)聯(lián)系碼海公眾號(hào)。