揭秘大眾點評賬號業務高可用的“三大法寶”
在任何一家互聯網公司,不管其主營業務是什么,都會有一套自己的賬號體系。
賬號既是公司所有業務發展留下的最寶貴資產,它可以用來衡量業務指標,例如日活、月活、留存等。
同時它也給不同業務線提供了大量潛在用戶。業務可以基于賬號來做用戶畫像,制定各自的發展路徑。
因此,賬號服務的重要性不言而喻,同時美團業務飛速發展,對賬號業務的可用性要求也越來越高。
本文將從以下幾個方面分享一些我們在高可用探索中的實踐:
- 業務監控
- 柔性可用
- 異地多活
- 總結
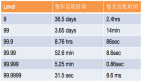
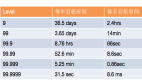
衡量一個系統的可用性有兩個指標:
- MTBF (Mean Time Between Failure),即平均多長時間不出故障。
- MTTR (Mean Time To Recovery),即出故障后的平均恢復時間。
通過這兩個指標可以計算出可用性,也就是我們大家比較熟悉的“幾個 9”。
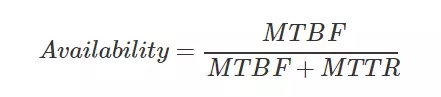
因此提升系統的可用性,就得從這兩個指標入手,要么降低故障恢復的時間,要么延長不出故障的時間。
業務監控
要降低故障恢復的時間,首先得盡早的發現故障,然后才能解決故障,這就需要依賴業務監控系統。
業務監控不同于其他監控系統,業務監控關注的是各個業務指標是否正常,比如賬號的登錄曲線。
大眾點評登錄入口有很多,從終端上分有 App、PC、M 站,從登錄類型上分有密碼登錄、快捷登錄、第三方登錄(微信/QQ/微博)、小程序登錄等。
需要監控的維度有登錄總數、成功數、失敗分類、用戶地區、App 版本號、瀏覽器類型、登錄來源 Referer、服務所在機房等等。業務監控最能從直觀上告訴我們系統的運行狀況。
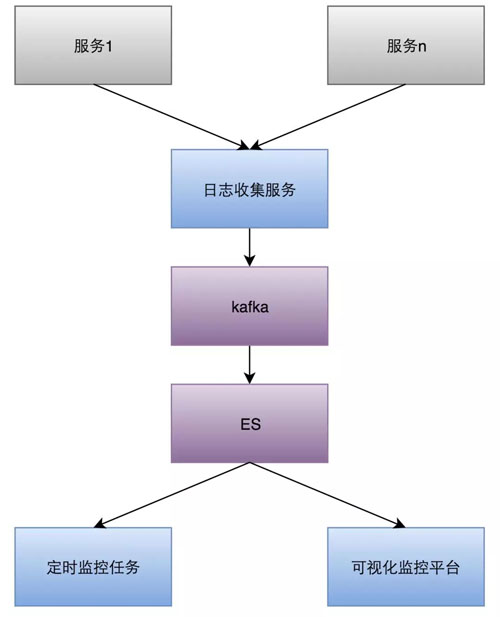
由于業務監控的維度很多很雜,有時還要增加新的監控維度,并且告警分析需要頻繁聚合不同維度的數據,因此我們采用 Elasticsearch 作為日志存儲。
整體架構如下圖:
每條監控都會根據過去的業務曲線計算出一條基線(見下圖),用來跟當前數據做對比,超出設定的閾值后就會觸發告警。
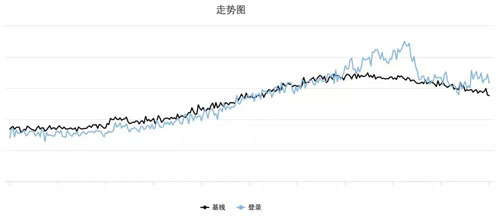
每次收到告警,我們都要去找出背后的原因,如果是流量漲了,是有活動了還是被刷了?如果流量跌了,是日志延時了還是服務出問題了?
另外值得重視的是告警的頻次,如果告警太多就會稀釋大家的警惕性。我們曾經踩過一次坑,因為告警太多就把告警關了,結果就在關告警的這段時間業務出問題了,我們沒有及時發現。
為了提高每條告警的定位速度,我們在每條告警后面加上維度分析。如下圖(非真實數據),告警里直接給出分析結果。

柔性可用
柔性可用的目的是延長不出故障的時間,當業務依賴的下游服務出故障時不影響自身的核心功能或服務。
賬號對上層業務提供的鑒權和查詢服務即核心服務,這些服務的 QPS 非常高,業務方對服務的可用性要求很高,別說是服務故障,就連任何一點抖動都是不能接受的。
對此我們先從整體架構上把服務拆分,其次在服務內對下游依賴做資源隔離,都盡可能的縮小故障發生時的影響范圍。
另外對非關鍵路徑上的服務故障做了降級。例如賬號的一個查詢服務依賴 Redis,當 Redis 抖動的時候服務的可用性也隨之降低。
我們通過公司內部另外一套緩存中間件 Tair 來做 Redis 的備用存儲,當檢測到 Redis 已經非常不可用時就切到 Tair 上。
通過開源組件 Hystrix 或者我們公司自研的中間件 Rhino 就能非常方便地解決這類問題。
其原理是根據最近一個時間窗口內的失敗率來預測下一個請求需不需要快速失敗,從而自動降級。
這些步驟都能在毫秒級完成,相比人工干預的情況提升幾個數量級,因此系統的可用性也會大幅提高。
下圖是優化前后的對比圖,可以非常明顯的看到,系統的容錯能力提升了,TP999 也能控制在合理范圍內。
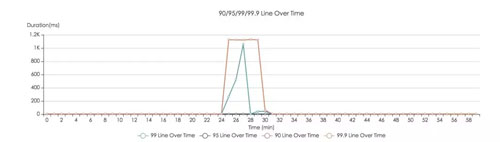
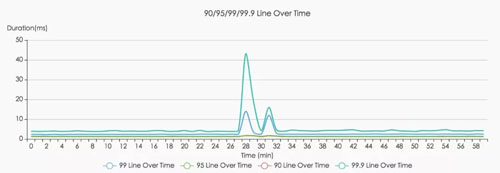
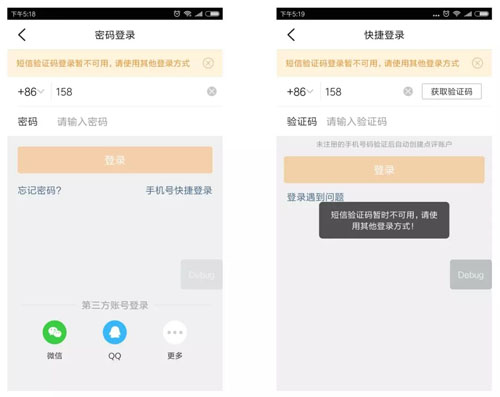
對于關鍵路徑上的服務故障,我們可以減少影響的用戶數。比如手機快捷登錄流程里的某個關鍵服務掛了,我們可以在返回的失敗文案上做優化。
并且在登錄入口掛小黃條提示,讓用戶主動去其他登錄途徑,這樣對于那些設置過密碼或者綁定了第三方的用戶還有其他選擇。
具體的做法是我們在每個登錄入口都關聯了一個計數器,一旦其中的關鍵節點不可用,就會在受影響的計數器上加 1,如果節點恢復,則會減 1。
每個計數器還分別對應一個標志位,當計數器大于 0 時,標志位為 1,否則標志位為 0。
我們可以根據當前標志位的值得知登錄入口的可用情況,從而在登錄頁展示不同的提示文案,這些提示文案一共有 2^5 = 32 種。
下圖是我們在做故障模擬時的降級提示文案:
異地多活
除了柔性可用,還有一種思路可以來延長不出故障的時間,那就是做冗余。冗余的越多,系統的故障率就越低,并且是呈指數級降低。
不管是機房故障,還是存儲故障,甚至是網絡故障,都能依賴冗余去解決。
比如數據庫可以通過增加從庫的方式做冗余,服務層可以通過分布式架構做冗余。
但是冗余也會帶來新的問題,比如成本翻倍,復雜性增加,這就要衡量投入產出比。
目前美團的數據中心機房主要在北京上海,各個業務都直接或間接的依賴賬號服務。
盡管公司內已有北上專線,但因為專線故障或抖動引發的賬號服務不可用,間接導致的業務損失也不容忽視,我們就開始考慮做跨城的異地冗余,即異地多活。
方案設計
首先我們調研了業界比較成熟的做法,主流思路是分 set 化,優點是非常利于擴展,缺點是只能按一個維度劃分。
比如按用戶 ID 取模劃分 set,其他的像手機號和郵箱的維度就要做出妥協,尤其是這些維度還有唯一性要求,這就使得數據同步或者修改都增加了復雜度,而且極易出錯,給后續維護帶來困難。
考慮到賬號讀多寫少的特性(讀寫比是 350:1),我們采用了一主多從的數據庫部署方案,優先解決讀多活的問題。
Redis 如果也用一主多從的模式可行嗎?答案是不行,因為 Redis 主從同步機制會優先嘗試增量同步。
當增量同步不成功時,再去嘗試全量同步,一旦專線發生抖動就會把主庫拖垮,并進一步阻塞專線,形成“雪崩效應”。
因此兩地的 Redis 只能是雙主模式,但是這種架構有一個問題,就是我們得自己去解決數據同步的問題,除了保證數據不丟,還要保證數據一致。
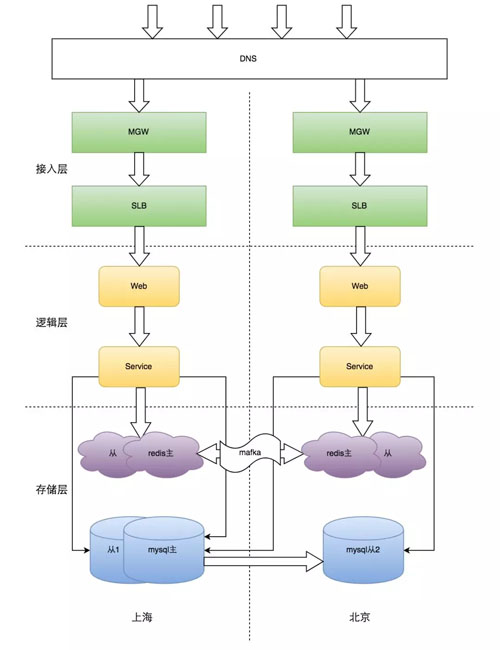
另外從用戶進來的每一層路由都要是就近的,因此 DNS 需要開啟智能解析,SLB 要開啟同城策略,RPC 已默認就近訪問。
總體上賬號的異地多活遵循以下三個原則:
- 北上任何一地故障,另一地都可提供完整服務。
- 北上兩地同時對外提供服務,確保服務隨時可用。
- 兩地服務都遵循 BASE 原則,確保數據最終一致。
最終設計方案如下:
數據同步
首先要保證數據在傳輸的過程中不能丟,因此需要一個可靠接收數據的地方,于是我們采用了公司內部的 MQ 平臺 Mafka(類 Kafka)做數據中轉站。
可是消息在經過 Mafka 傳遞之后可能是亂序的,這導致對同一個 key 的一串操作序列可能導致不一致的結果,這是不可忍受的。
但 Mafka 只是不保證全局有序,在單個 partition 內卻是有序的,于是我們只要對每個 key 做一遍一致性散列算法對應一個 partitionId,這樣就能保證每個 key 的操作是有序的。
但僅僅有序還不夠,兩地的并發寫仍然會造成數據的不一致。這里涉及到分布式數據的一致性問題,業界有兩種普遍的認知,一種是 Paxos 協議,一種是 Raft 協議。
我們吸取了對實現更為友好的 Raft 協議,它主張有一個主節點,其余是從節點,并且在主節點不可用時,從節點可晉升為主節點。
簡單來說就是把這些節點排個序,當寫入有沖突時,以排在最前面的那個節點為準,其余節點都去 follow 那個主節點的值。
在技術實現上,我們設計出一個版本號(見下圖),實際上是一個 long 型整數,其中數據源大小即表示節點的順序,把版本號存入 value 里面。
當兩個寫入發生沖突的時候只要比較這個版本號的大小即可,版本號大的覆蓋小的,這樣能保證寫沖突時的數據一致性。
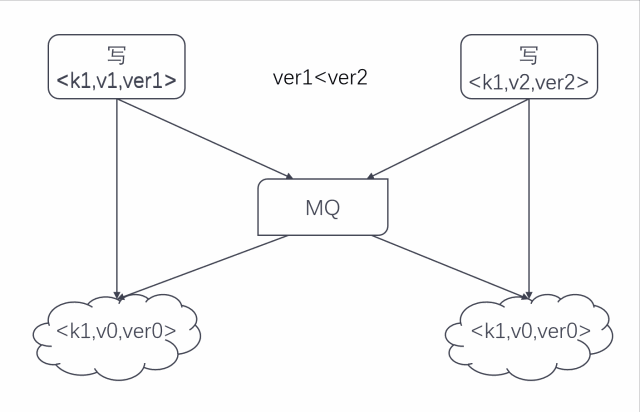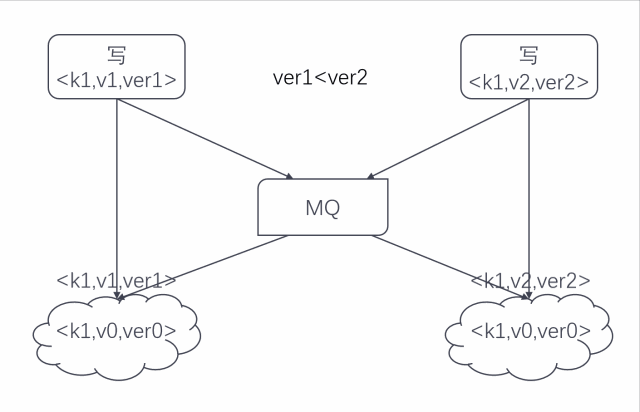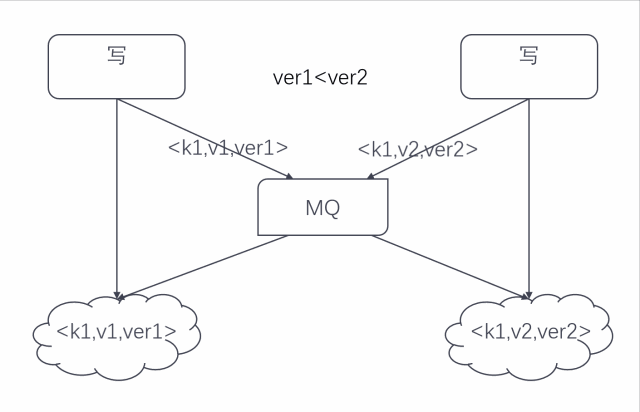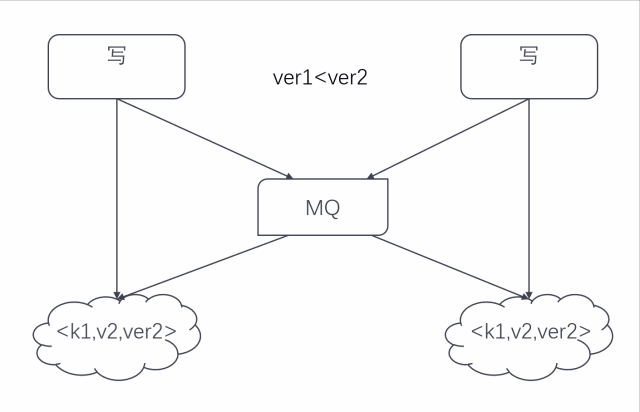
寫并發時數據同步過程如下圖:
這種同步方式的好處顯而易見,可以適用于所有的 Redis 操作且能保證數據的最終一致性。
但這也有一些弊端,由于多存了版本號導致 Redis 存儲會增加,另外在該機制下兩地的數據其實是全量同步的。
這對于那些僅用做緩存的存儲來說是非常浪費資源的,因為緩存有數據庫可以回源。
而賬號服務幾乎一半的 Redis 存儲都是緩存,因此我們需要對緩存同步做優化。
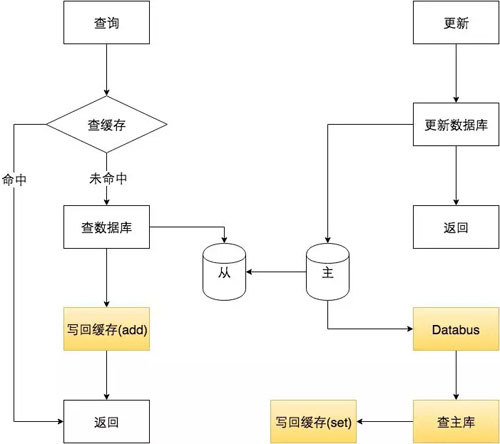
賬號服務的緩存加載與更新模式如下圖:
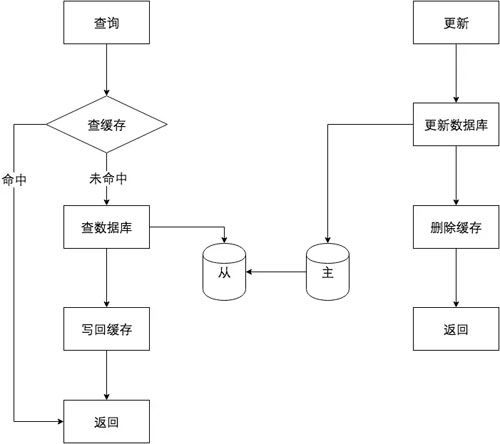
我們優化的方向是在緩存加載時不同步,只有在數據庫有更新時才去同步。
但是數據更新這個流程里不能再使用 delete 操作,這樣做有可能使緩存出現臟數據,比如下面這個例子:
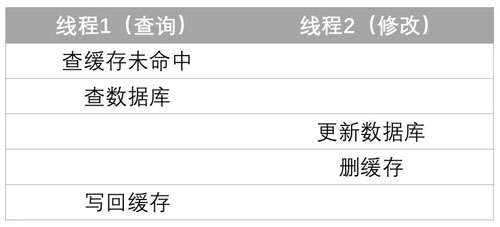
我們對這個問題的解決辦法是用 set(若 key 不存在則添加,否則覆蓋)代替 delete。
而緩存的加載用 add(若 key 不存在則添加,否則不修改),這樣能保證緩存更新時的強一致性卻不需要增加額外存儲。
考慮到賬號修改的入口比較多,我們希望緩存更新的邏輯能拎出來單獨處理減少耦合。
***發現公司內部數據同步組件 Databus 非常適用于該場景,其主要功能是把數據庫的變更日志以消息的形式發出來。
于是優化后的緩存模式如下圖:
從理論變為工程實現的時候還有些需要注意的地方,比如同步消息沒發出去、數據收到后寫失敗了。
因此我們還需要一個方法來檢測數據不一致的數量,為了做到這點,我們新建了一個定時任務去 scan 兩地的數據做對比統計,如果發現有不一致的還能及時修復掉。
項目上線后,我們也取得一些成果,首先性能提升非常明顯,異地的調用平均耗時和 TP99、TP999 均至少下降 80%。
并且在一次線上專線故障期間,賬號讀服務對外的可用性并沒有受影響,避免了更大范圍的損失。
總結
服務的高可用需要持續性的投入與維護,比如我們會每月做一次容災演練。
高可用也不止體現在某一兩個重點項目上,更多的體現在每個業務開發同學的日常工作里。
任何一個小 Bug 都可能引起一次大的故障,讓你前期所有的努力都付之東流,因此我們的每一行代碼,每一個方案,每一次線上改動都應該是仔細推敲過的。
高可用應該成為一種思維方式。***希望我們能在服務高可用的道路上越走越遠。