從沒想到監控可以這么做!阿里云RDS智能診斷系統首次公開
來自阿里云RDS團隊的論文“TcpRT: Instrument and Diagnostic Analysis System for Service Quality of Cloud Databases at Massive Scale in Real-time” (TcpRT:面向大規模海量云數據庫的服務質量實時采集與診斷系統)被數據庫頂會SIGMOD 2018接收,會議將于6/10在美國休斯敦召開。
TcpRT論文介紹了RDS天象系統在云數據庫SLA數據采集、服務質量指標計算、異常檢測、故障根因分析領域的創新工作,以及大規模部署自動化的服務各類云上客戶的實踐經驗。評委評價“I have plenty of experience with manual anomaly detection. That has wasted much time for me at work, so I liked what you described.”
簡介
隨著企業上云趨勢的日益熱化,作為產業核心組件的數據庫,已成為各大云計算公司增長最快的在線服務業務。作為中國第一大云數據庫廠商,我們RDS團隊致力于為用戶提供穩定的云數據庫服務。從本質上看,RDS是一個多租戶DBaaS平臺,利用輕量級KVM、Docker鏡像等資源隔離技術將用戶所購買的數據庫實例部署在物理機上,按需分配資源并進行自動升降級,實現一套完全自動化的智能運維管理。
云數據庫對客戶業務的穩定性至關重要,因此快速發現云數據庫性能出現異常,及時定位異常原因是云數據庫廠商的一個挑戰。TcpRT是阿里云數據庫用來監控和診斷數據庫服務質量的一個基礎設施。TcpRT從主機TCP/IP協議棧的壅塞控制采集trace數據,計算數據庫延遲和網絡異常,在后臺流式計算平臺進行大規模實時數據分析和聚合,通過統計指標歷史數據的柯西分布發現異常點,并通過同一臺主機、交換機、proxy下所有實例一致性趨勢的比例來計算不同組件發生異常的概率。
到目前為止,TcpRT以每秒采集2千萬條原始trace數據、每天后臺處理百億吞吐數據、秒級檢測異常的卓越性能在阿里云持續穩定運行三年。
本文貢獻:
- 提出了一種新的對數據庫服務質量進行采集的方法,基于內核壅塞模塊實現,可以非侵入性、低代價的采集基于停等協議的關系數據庫的per connection的延遲、帶寬,分析用戶使用數據庫的模型(短連接和長連接),并且可以端到端的記錄和量化基礎網絡服務質量對數據庫服務質量的影響,包括丟包率、重傳率。
- 我們開發了一套對采集的原始數據進行數據清洗、過濾、聚合、分析的流式計算系統,系統可以做到水平擴展、容錯性、實時性、Exactly Once,具有和其他大數據平臺例如EMR、MaxCompute進行數據交換的能力。
- 我們提出了一個新的算法對TcpRT數據進行分析,來發現數據庫的服務質量有無異常,并且對異常事件的根因進行定位。
問題
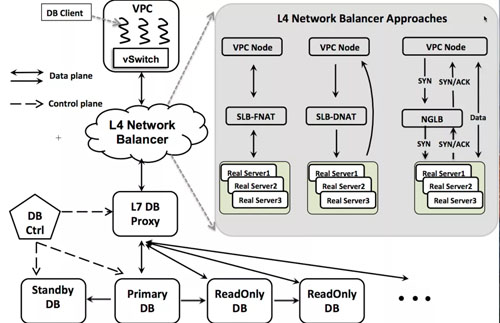
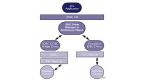
從網絡架構上看,RDS由控制層和數據鏈路層兩個部分組成,如上圖所示。其中,控制層包括一系列管理模塊,比如資源管理器,HA管理器,遷移管理器等。資源管理器負責將實例的不同副本分配在獨立的物理主機上。當實例發生故障時,HA管理器會探測到主實例的故障,并將服務連接切換到Standby節點上。而當主機負載失衡時,遷移管理器負責將數據庫實例進行遷移,保障用戶服務質量。
數據鏈路層主要負責數據的分發和路由。通常,云用戶通過ECS和RDS實現業務上云。他們將業務部署在ECS上,并通過VPC和RDS數據庫實例進行交互。數據包通過駐留在用戶VPC網絡中的vSwitch進行打包/解包并路由。而SLB負責將這些數據包進行解析,并將DBaaS IP映射到真實服務器上。目前,SLB同時支持FNAT和DNAT兩種模式。由于出流量數據不經過SLB, DNAT比FNAT呈現出更好的性能。除此之外,我們引入NGLB進行優化。在Proxy中,我們解析客戶端/服務端協議,并提取查詢,將讀寫進行分離,同時支持橫向分區和連接池的功能。
作為客戶業務的核心組件,保障云數據庫7/24的穩定至關重要。我們通過對用戶承諾數據庫SLA服務等級協議,來保障用戶的權益。然而,云數據庫的服務質量受各種因素影響,例如突發性連接斷開、數據庫延遲發生抖動、吞吐驟然下降等,都有可能帶來用戶業務指標的下降。因此,快速發現云數據庫性能異常,及時定位根因是云數據庫廠商的一個挑戰。
可能造成云數據庫的服務質量下降的原因很多,例如網絡上的異常,比如DB主機的上聯交換機tor發生丟包,或者load balaner出現TCP incast問題;或者用戶側的問題,用戶端網絡異常或者丟包;或者多租戶機制,DB主機內核缺陷、硬件上SSD的硬件異常等等都會引起。在出現問題時,快速診斷定位解決問題是關鍵的問題。
傳統數據庫性能采集只需要采集DBMS內部處理SQL請求的延遲就夠了,但云數據庫需要end-end數據。因為對云上用戶而言,他看到的云數據庫的延遲是終端的延遲。真實的場景對trace工具提出這些需求,因此很關鍵的是要采集end-to-end數據,以及鏈路每段的延遲,終端用戶感受到的延遲是所有路徑上每個節點處理延遲以及網絡上所有延遲的總和,不僅僅要采集DB上的延遲,還要采集proxy上看到的延遲。這需要在鏈路上引入trace。還要采集網絡上的數據,主機上其實可以看到的上行亂序和下行的重傳,這個信息對推測網絡有無異常非常重要。發送和接收會走不同的網絡路徑。
傳統的trace手段需要入侵式地在業務代碼中添加埋點。第一,我們不能在客戶端埋點,因為客戶基本上都使用標準數據庫客戶端來訪問,沒有嵌入打點代碼,我們也不能期望客戶會修改自己的業務代碼,加入打點邏輯,并將打點數據采集交給我們。因此我們需要一種非侵入式的方法來獲取end-to-end性能數據。第二在服務器端埋點也有問題,應用層無法感知真正的數據接收和發送時間。應用層記錄的時間是內核把數據交付給應用層和應用層把數據交付給內核的時間。在系統負載很高,應用層進程調度需要花費大量時間的場景下,會導致請求的實際處理時間計算不準確;應用層無法感知到網絡鏈路質量。在網絡出現擁塞,大量的重傳報文,導致數據發送和接收過程大大延長,無法區分出是對端響應緩慢還是網絡鏈路質量不佳。
在這種挑戰下,TcpRT——阿里云數據庫監控和診斷服務質量系統,孕育而生。
TcpRT從主機TCP/IP協議棧的擁塞控制采集trace數據,用于監測數據庫延遲和網絡異常,并利用先進的流技術,在后臺實時計算平臺上進行大規模在線數據分析,結合離線模型,通過實時異常事件判定,以及RDS網絡關系圖譜中的趨勢一致性概率探測,快速診斷出性能異常并定位原因。
架構
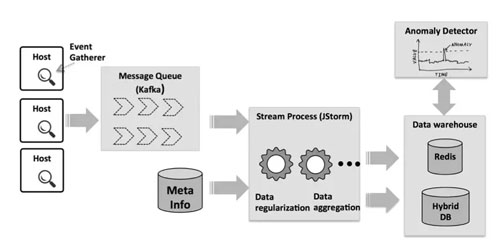
上圖是TcpRT的概要架構圖,其中包含以下個組件:
- 內核模塊——用于采集指標trace數據,包括查詢延遲、Proxy節點和DB節點的連接指標等
- 本地聚合器——負責將內核模塊采集的trace數據進行本地聚合處理,推送至Kafka消息隊列
- 流式ETL——利用流技術,在后臺流式計算平臺上將Kafka中的時序指標數據進行清洗、多粒度聚合及在線分析,利用冷熱技術將數據分離
- 在線異常監測——根據時序指標數據,擬合異常模型,通過實時異常事件判定,以及RDS網絡關系圖譜中的趨勢一致性概率探測,快速診斷出性能異常并定位原因
TcpRT內核模塊
內核模塊主要負責對網絡數據的傳輸進行整個生命周期的監控。在遵守停等協議的TCP通信機制下,服務端處理每個請求的過程分成3個階段,接收階段(Receive)、處理階段(Handle)和響應階段(Response)。如下圖所示:
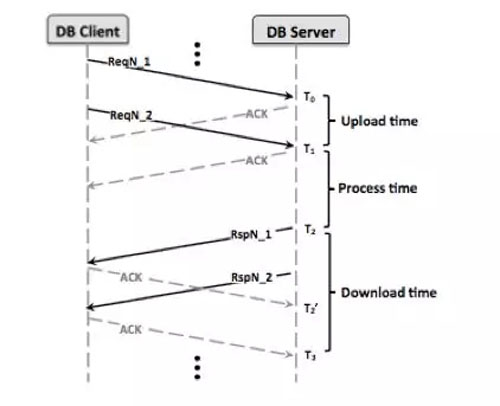
鑒于此,我們需要計算如下時間:
上行時間 = T1 - T0
處理時間 = T2 - T1
下行時間 = T3 - T2
查詢時間 = T3 - T0
RTT時間 = T2 - T2'
現有的監控方案,通常在業務層面埋點進行服務耗時監控,但此方法既不能獲得真正的數據接收和發送時間、也無法感知到網絡鏈路的質量,更需要在業務代碼中入侵式地添加埋點。因此,我們實現了一種通用、低開銷的內核模塊進行trace監控以得到上述時間。
首先,我們選擇修改Linux內核的擁塞控制算法。此算法可以感知內核發送報文的上下文,并且支持熱更新(只需增加一個驅動模塊而無需更新線上內核)。
此外,擁塞控制算法提供了以下機制:
1. 每個TCP通信是獨立的擁塞控制算法,不存在資源競爭情況
2. 可以感知到收到的每個ACK報文的上下文
3. 在已經發送的報文都已經被ACK的情況下,可以感知到當前發送的報文上下文
根據擁塞控制算法提供的事件回調,我們可以獲取到每個TCP連接下述事件:
1. 客戶端發送給服務端ACK報文
2. 在所有已經發出去的sequence都被確認的情況下,服務端發送報文
3. TCP連接建立
4. TCP連接斷開
內核任何線程都可能調用到擁塞控制算法,因此為了性能,擁塞控制算法必須保證是沒有數據爭搶的。TcpRT內核模塊保證了以下四點:
1. TcpRT所有的數據保存在每個TCP連接對象上,所有的數據讀寫都沒有跨TCP連接的共享;
2. TcpRT在每個CPU core都有獨立的寫緩沖區,防止了多個內核線程爭搶寫緩沖區加鎖;
3. 為了避免內存開銷,又保證實時性,TcpRT的寫緩沖區會在buffer滿或者時間到的情況下,刷新寫緩沖區到debugfs,供應用層采集端采集。由于寫debugfs的頻率很低,debugfs的鎖爭搶幾乎不存在,最大限度保證了性能;
4. TcpRT回寫的數據,是binary格式的,對比需要format的字符格式,在實測場景可以提高20%的性能。
此外,通過給linux內核添加setsockopt選項,通知內核一個不需要應答的請求交互過程已經結束,從而支持非停等協議。
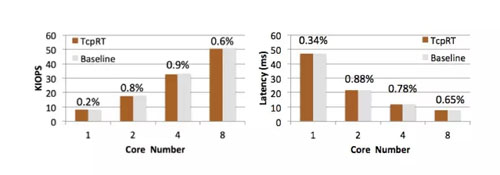
針對TcpRT內核模塊對用戶數據庫實例的性能影響,我們基于sysbench模擬了MySQL 400個客戶端連接進行壓測,結果如下圖所示,TcpRT內核模塊對系統的負載影響不到1%。
TcpRT內核模塊,利用debugfs和用戶態通信。每秒以千萬的trace數據高速產出并吐入至debugfs中。為了減輕后臺在線分析任務的壓力,我們構建本地TcpRT聚合器,實現本地trace秒級聚合,并將聚合結果輸出到/dev/shm中。Logagent從中讀取聚合數據,發送至Kafka,并由后臺ETL接手,進行實時數據分析,流程如下圖所示:
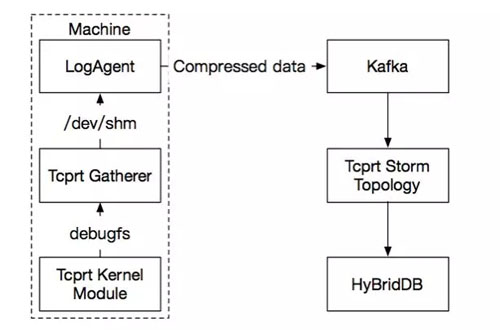
在本地聚合器中,聚合操作需要保證可交換且可結合,我們采用均值、最大值、請求個數的三元組聚合方法來保證延遲時間類指標滿足這一要求。此外,我們采用每秒同客戶端出現的不同端口數對活躍連接數進行指標特征提取。同時,抽取請求數作為特征,建立用戶長短連接的使用模型,進而對用戶使用數據庫實例的負載模式進行分析。根據歷史數據,當前仍有眾多用戶采用短連接模式,這對于諸如MySQL線程網絡模型的DB是非常不友好的,從而激發我們提供Proxy中間件將短連接轉換為長連接服務。
為了最大化聚合效果,我們在內存中維護最近5s的聚合結果,將5s前的數據輸出到/dev/shm的文件中。且為了提高查詢性能以及長時間段的聚合操作,我們將三種粒度1s, 5s, 1m的聚合結果存入到庫中。
TcpRT ETL
下圖描繪了ETL任務的拓撲結構:
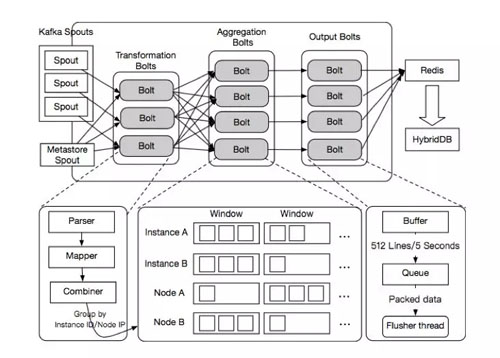
在線ETL任務主要包括四個子任務:
- 數據轉換
- 數據關聯與聚合
- 數據存儲
- 以及延遲和亂序處理
其中,延遲和亂序到達的處理是一個難點。TcpRT輸出的時序數據是以SQL執行結束時間為時間戳,如何做到實時準確地對窗口內的時序數據進行聚合并將結果刷出是一個兩難的問題。我們采用了“盡力聚合”的方法,即對窗口設定等待時間,待時間結束后將實時聚合結果刷出,若此后,還有該窗口的時序數據到來,則直接落入到數據庫中。如TcpRT聚合器中所述,所有聚合數據具有可再結合特性,這樣,我們可以對同時刻的聚合數據進行二次聚合。
在線異常監測
組件的異常往往伴隨著相關指標的抖動。比如主機發生IO Hang后,load、dirty、writeback、某些core的iowait、被阻塞的線程數等指標會明顯升高,而各實例的write,CPU使用率會明顯變低,主機維度的PT指標會明顯升高。在部分情況下,連接數會上升,長連接請求數會下降,流量會下降等。在Proxy發生異常的時候,PT可能會升高、CPU、流量、連接數均可能會下降。
傳統方法下,我們通過設定閾值進行指標抖動的檢測。然而閾值的設定強依賴于專家經驗,維護成本高,且一刀切的設定常常會“誤傷”健康指標。比如,有些數據庫實例是專門用于OLAP,它們的SQL請求處理時間往往都是秒級的,若采用常用的SQL請求處理時間作為異常判定閾值,此類數據庫實例就會觸發報警。
鑒于此,我們需要一種通用且自適應的智能模型來解決云數據庫的異常監測。
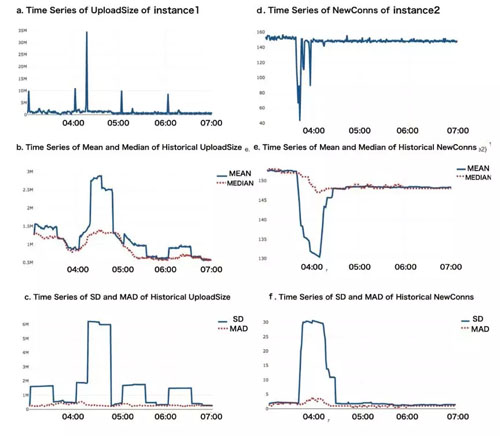
為了避免人工設定閾值,我們一開始嘗試利用control charts來進行判斷,根據樣本時間段的均值和標準差,預測未來時間段的置信區間。若實際值超出置信區間,則判定為異常。然而,若樣本本身為異常,則此時間段的參數均不可信。
如上圖,左上圖為(ins1,*,db1)的upsize指標時序圖,可以看到(ins1,*,db1)的upsize指標會有周期性的波動。左下的兩張圖分別是歷史時間窗口設定值為30min的(ins1,*,db1)的upsize指標mean&median時序圖和SD&MAD時序圖。可以清楚看到,當upsize指標發生波動后,mean值和標準差SD值都會發生窗口時間長度的跳變,但median和MAD卻幾乎不受指標波動的影響,顯得更平穩、絲滑。
右上圖為(ins2,*,db2)的newConn指標時序圖,可以看到在03:40~04:00期間,指標發生異常,出現大量極端值,由于歷史的時間窗口設定值為30min,所以可以從左下的圖表中看到,很長一段時間內樣本的均值和標準差便會發生較大的波動,而中位數和MAD指標卻顯得平滑,對極端值并不敏感,展出超強的魯棒性。由于依賴均值和標準差進行預測,control charts具有不穩定性,易造成誤判。這啟發我們利用中位數和MAD替代均值和標準差作為預測模型參數。
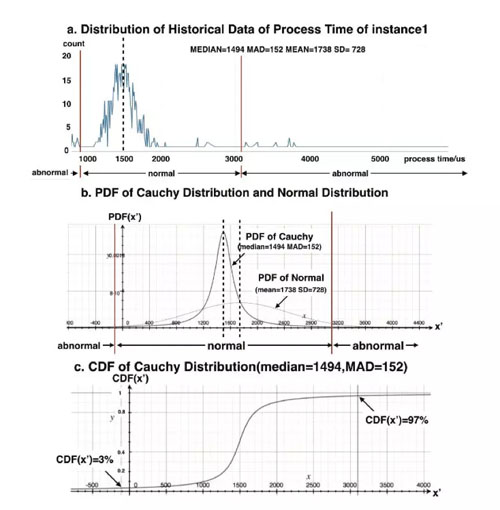
如上圖所示,通過大量觀察,我們發現,按(*,*,db) 和(*,*,proxy) 粒度聚合后的采樣點集合近似正態分布。但是,正態分布依賴平均值和標準差作為參數,如上文所述,這兩個參數波動大,會造成嚴重誤判。鑒于柯西分布與正態分布相似,且不依賴均值和標準差,可以使用中位數和MAD這種穩定的統計指標來進行回歸。從上上圖可以看到當歷史時間窗口長度設定合適的時候,中位數和MAD在面對指標波動和異常的情況下,顯得平滑且穩定,這樣回歸出的模型具有更強的穩定性。于是,我們使用中位數和MAD作為參數的回歸柯西分布來擬合異常診斷模型。
為了獲取回歸需要的樣本集,我們通過對過去一段時間(比如:最近一個小時)的每一個時間點做采樣,得到一段歷史窗口的數據點集合S{x0,x1,x2,……}。根據歷史窗口數據集,計算中位數M以及MAD,回歸出這個數據集的柯西概率分布D。

主機異常檢測
RDS主機上承載著眾多實例,各實例通常隸屬于不同用戶的不同業務。在主機正常工作時,由于實例相互獨立、并且對應的指標波動具有不確定性,所有實例呈現出一致性升高或降低的概率非常小。當主機發生異常時,由于該主機上的所有實例共享同一資源,某些關鍵指標會呈現出一致性趨勢。當一臺主機發生了IO Hang,主機上大部分實例的SQL處理延遲都呈現出升高的趨勢,各實例的數據寫入量呈現出下降的趨勢。這啟發我們利用實例趨勢一致性概率來判斷主機的異常。
首先,設定函數H(curentVal, prevMideanVal,metricType)作為判斷指標metric1是否異常的函數,取值只能是-1,0,+1。currentVal代表這一刻該指標的值,prevMideanVal代表過去一段時間(比如:1小時)采樣點集合的中位數,metricType代表該指標的類型(比如:rt,rtt,qps,流量等)。取值為-1代表這個指標在跟過去一段時間指標做對比的時候呈現出明顯下降的趨勢,0代表這個指標沒有明顯波動,+1代表這個指標與過去一段時間相比明顯上升。
我們可以利用上文的算法來實現函數H,這樣我們能算出(ins,*,dstIp,metricType)級別數據的函數H值,然后在按(ins,*,dstIp,metricType)->(*,*, dstIp,metricType)做map-reduce(agg類型為sum)。算出的值s反映了這個指標在這臺主機上的突升,突降的趨勢,用求和值s除以這個主機上的活躍實例數t得出突升/突降實例比例r,當r大于0是,總體趨勢上升,當r小于0是,總體趨勢下降,且絕對值越大概率越大。
那么我們如何利用r值來判斷主機異常呢?如果機器突然由正常變為異常時,各實例由于都依賴這臺機器的資源進行工作,或多或少要受其影響,因此相關指標發生突變的實例比例將會發生突變,比如主機上cpu資源突然不足,大部分實例都會受影響,他們的處理時間會突升,流量突降,請求數突降,因此可以通過判斷r值是否突變來判斷主機異常。
我們可以利用上文的算法來對r值的突變進行判斷,對過去一段時間的每一個時間點都做這樣的計算,我們可以得到一段歷史窗口的突升/突降實例比例r行程的數據點集合S{R0,R1,R2,…}。根據歷史窗口數據集,我們算出數據集的中位數M,以及MAD值,回歸出這個數據集的柯西概率分布D。
因為比例r的取值是-1~1,而柯西概率分布D的自變量x范圍是負無窮到正無窮。我們需要對原來的比率r做轉化讓他的范圍擴充到正負無窮。通過定義的映射函數求出這一時刻下該指標的柯西概率分布的CDF(),如果CDF()非常小,比如小于0.1%,主機hostA的指標metric1呈現總體下降趨勢,或者非常大比如99.8%, 主機hostA的指標metric1呈現總體上升趨勢。 但是這樣做判斷,只是判斷出了r值的突升和突降,為了減少誤判,我們還要判斷出r值的突升和突降需要落到警戒范圍。因此需要一個必要條件:r值的絕對值至少為20%。
另外,當r值足夠高時,無論r值是否突升還是突降,都應該認為是異常,因此還需要一個充分條件:r值的絕對值大于AlarmRatio(主機上的活躍實例t),那么認為是異常。根據我們自己的實際情況,AlarmRatio(t)=0.8*Pow(0.987, t) + 0.2. 曲線如圖,當主機上的活躍實例比較少時,AlarmRatio值比較高,這樣為了保證判斷出異常的主機上異常的實例足夠多,這樣才有較高的說服力,而隨著主機上活躍實例數變多,AlarmRatio值會相應得變小最后收斂到0.2,這樣為了不漏掉r比較少但是異常實例數足夠多的情況。
當r=-1時,這臺機器hostA上所有的實例的指標metric1都出現了下降趨勢,當r=1時,hostA上所有實例的指標metric1都出現了上升趨勢。除了獨占實例,一臺主機上有數十甚至上百的實例,他們分屬不同的用戶,運行著不同的業務,呈現出一致的趨勢概率很小,因此在正常的時候r值往往穩定在一個較低的范圍內,當r值很高的時候,極有可能主機問題了。
但是這樣的判斷還不夠,因為還存在這兩種情況:1. 實例之間公用的某個組件出現了異常。比如網絡中間件引起的異常,路由器的異常等等。也會引起r值變高;2.有的主機上因為實例數比較少(比如:小于3)時,單純根據比例判斷還分辨不出是否是主機的問題,因為樣本數太少,不具有說服力。針對這兩種情況,我們還用了多種方法來提高準確率,比如:
1.結合物理機的資源指標(load,iowait,dirty,writeback等)的加權和來協助判斷。2.如果存在上游節點(比如:proxy),并且上游節點存在異常,則優先報上游節點的異常。因為上游節點往往還連接多個下游節點,如果是某個單獨的下游節點出現了異常,一般上游節點是不會出現異常的,因為上游節點上連接的下游節點很多,這一個點并不會明顯改變整體的指標趨勢變化,而某個節點的多個下游節點都出了問題,他們的上游節點出問題的概率更大一些。假設上游節點完全正常,下游節點近似相互獨立,一個節點出問題的概率為p,K各節點同時出問題的概率就是p^K,所以問題的原因很可能是概率更大的上游節點。
Proxy異常檢測
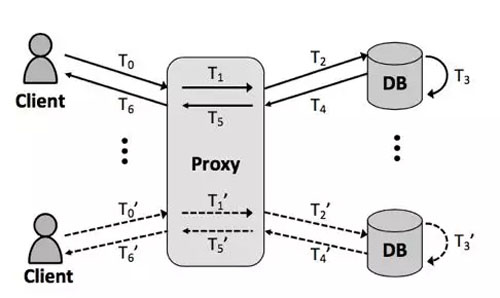
我們的大部分實例在訪問db前要經過proxy的轉發,proxy可以幫用戶做短鏈接優化,負載均衡,連接審計,注入檢測等。proxy是我們生產集群非常重要的組件,一個proxy節點最多會有上千個實例的請求(requests of thousands of instances)經過。也就是說,如果一個proxy節點發生了故障,將會影響到上千個實例,這樣的故障我們需要快速準確地發現并定位出來,否則后果不敢想象。
我們一開始對proxy的qps,連接數等設定閾值的方式來進行報警,但是由于不同分組的proxy業務量大小不一樣,因此我們需要對不同分組設定不同的閾值,而且我們的業務增長迅速,proxy會經常進行擴容,這樣閾值又要重新調整,維護起來費時費力。
我們雖然可以利用上邊所講的判斷db主機異常一樣的算法來判斷proxy異常,但是由于proxy的處理時間包含了db本地的處理時間,應用這種方式我們是無法評估出請求在單純在proxy中停留的時間。對于使用了proxy鏈路的用戶,由于在網絡中多了proxy轉發的代價,所以SQL請求的延時會稍微比不用proxy鏈路的請求要慢。因此為了不影響用戶的體驗,我們希望SQL請求在proxy節點中停留的時間越短越好。因此我們以SQL請求在proxy節點中停留和proxy與db之間的傳輸總時間prT(proxy relay time)作為衡量proxy服務質量的重要指標。如果實例ins1的請求在proxy節點的prT>=ProxyRelayTimeLimit,對于該請求,proxy代價時間過長。
由于有現成的生產集群上proxy節點和db節點都安裝了tcprt內核驅動,我們打算proxy節點和db節點的tcprt數據來做類似的工作。
如圖是ins1,ins2的SQL請求在proxy節點和db節點上的鏈路活動圖。 ins1實例的一次請求時間rt1= t0+ t1 + t2 + t3 + t4 + t5 + t6, 其中t0是SQL請求從client端到proxy端傳輸的時間, t1是接收client端發的請求到向db端發送所需的時間,t2是proxy1到db1的網絡鏈路時間,t3是db1的本地處理時間,t4是db1到proxy1的網絡鏈路時間,t5是接受到db1端發的SQL應答到向client端發送的時間,t6是應答從proxy端到client端的傳輸時間。而(ins1, *, proxy1)的tcprt處理時間proxyInTime1=t1+t2+t3+t4+t5, (ins1, proxy1, *)的tcprt處理時間proxyOutTime1=t3,通過計算diff1 = proxyInTime1-proxyOutTime1 = t1+t2+t3+t5, 可以算出SQL請求在proxy節點中停留和proxy與db之間網絡傳輸的總時間prT。
由于網絡延遲正常情況下在內部網絡中比較穩定的,如果diff1值變大了,多出的部分,往往是proxy節點貢獻的,因此我們可以大致通過diff1估計實例ins1在proxy1停留的的大致時間。對于經過proxy的每個實例,如果prT>=ProxyRelayTimeLimit,則認為prT過大。我們算出proxy1上的各個實例的prT值,得到prT值過長的實例數量占proxy1上活躍實例數的比例r。我們可以根據r的突升和范圍來判斷proxy及下游網絡鏈路是否對用戶形成影響。 為了判斷r的突升,首先,利用上面判斷db主機異常的方法,回歸出這個數據集的柯西概率分布D。
因為比例r的取值是0~1,而柯西概率分布D的自變量x范圍是負無窮到正無窮。我們需要對原來的比率r做轉化讓他的范圍擴充到正負無窮。通過映射函數,我們求出這一時刻下該指標的柯西概率分布的CDF(x’),由于r越小表明proxy越健康,所以只有當r>M是才會進一步判斷proxy是否異常,如果CDF(x’)非常大比如:大于99.8%, 說明比率r突然明顯上升,需要引起注意。為了減少誤判,我們還要判斷出r值的突升和突降需要落到警戒范圍。因此需要一個必要條件:r值的絕對值至少為20%。
不過如果r本身就很大的話比如:由于proxy升級到了一個有bug的版本上,所有的實例從新版本上線后就一直慢,由于數據集的中位數變成了100%,上面的方法就無法判斷了。我們還要再加個異常的充分條件,那就是:如果r>MaxRatio(比如:80%),就判斷為異常。使用回歸分布的方法適合當r發生巨變時來判斷異常,主要是為了找到proxy的急性病;而后加的判斷異常的充分條件適用于當r從一開始就不正常,或者r緩慢變成不正常的情況,是為了找到proxy的慢性病。
網絡異常檢測
為了容忍交換機單點故障,每個節點(代理節點和數據庫節點)會上聯到一對TOR交換機上。TOR中的高丟包率會導致大量TCP數據包重新傳輸,并導致查詢延遲變高、失敗連接增加,從而導致用戶數據庫性能下降。因此,在短時間內,識別網絡故障并定位異常網絡設備,通過修復或者更換的方式去解決網絡異常是至關重要的。 通過TcpRT采集的TCP連接上亂序數據包,重傳數據包,RTT抖動和RST數據包的數量,可用于網絡故障排查。
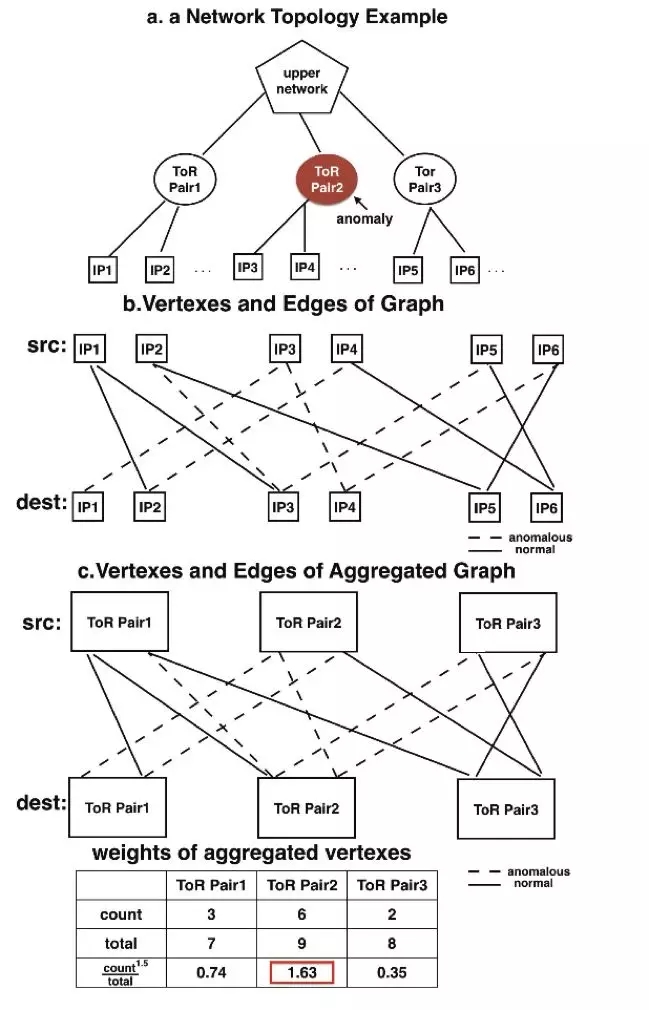
如上圖所示,在分布式體系結構中,每個節點相互通信,比如,Proxy節點到數據庫節點的請求重定向。我們繪制一個二分圖來表示節點之間的關系,頂點是Proxy節點和正在通信的數據庫節點,如果兩個節點存在相互通信,那么這兩個節點存在一條鏈接邊。用虛線標記的鏈接表示在兩個節點之間觀察到大量網絡異常事件(無序,重傳等),否則我們使用實線代替。
根據主機到TOR交換機對的連接信息,通過把主機節點替換成相應的TOR交換機對,我們將上圖b轉換成上圖c。直觀上,相連虛線數越多的頂點異常可能性越高。因此,我們定義公式count^1.5/total來衡量TOR交換機對發生異常的概率,其中count表示虛線數,total表示線(虛+實)數。count^1.5/total值越大,該TOR交換機對越有可能是異常。
小結
到目前為止,TcpRT以每秒采集2千萬條原始trace數據、每天后臺處理百億吞吐數據、秒級檢測異常的卓越性能在阿里云持續穩定運行三年。今年TcpRT的監控能力將包裝成云產品開放給RDS客戶,給客戶提供更好的數據庫與應用診斷能力。在技術上,我們也在基于TcpRT開發更多的算法,發掘更多的異常行為。
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】