













遇到有這六大缺陷的數據集該怎么辦?這有一份數據處理急救包
不要再向你的機器學習模型里喂垃圾了!
在這篇文章中,身兼AI工程師/音樂家/圍棋愛好者多職的“斜杠青年”Julien Despois給出了數據科學中需要避免的6大錯誤。
全文編譯整理如下:
簡介
身為一名數據科學工作者,你應該聽說過一句話:
你的結果會和你的數據一樣好。
很多人試圖通過提升模型來彌補不太理想的數據集。這等同于你的舊車因為用了廉價汽油性能不好,但你買了一輛豪華跑車。很明顯藥不對癥嘛!
在這篇文章中,我會講一講如何通過優化數據集提升模型結果,并將以圖像分類任務為例進行說明,但這些tips可被應用在各種各樣的數據集中。
今天的正餐,正式開始——
問題一:數據集太小
如果數據集太小,模型將沒有足夠樣例概括可區分特征。這將使數據過擬合,從而出現訓練誤差(training error)低但測試誤差(test error)高的情況。
解決方案1:
去收集更多數據吧~嘗試找到更多和原始數據集來源相同的數據,如果圖像很相似或者你追求的就是泛化,也可用其他來源的數據。
小貼士:這并非易事,需要你投入時間和經費。在開始之前,你要先分析確定需要多少額外數據。將不同大小的數據集得出的結果做比較,然后思考一下這個問題。
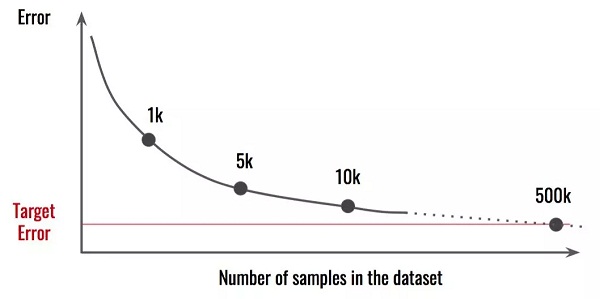
△ 數據集中數據量和錯誤率的關系
解決方案2:
通過為同一張圖像創建多個細微變化的副本來擴充數據,可以讓你以非常低的成本創造很多額外的圖像。你可以試著裁剪、旋轉或縮放圖片,也可以添加噪音、模糊、改變圖片顏色或遮擋部分內容。

△ 一張圖片的各種變化
不管怎么操作吧,只需保證這些數據仍代表相同類就好了。
雖然這種操作很厲害,但仍不如收集更多原始數據效果好。
△ 處理后圖像仍被分類為貓
小貼士:這種“擴充術”不適合所有問題,比如如果你想分類黃檸檬和綠檸檬,就不要調顏色了嘛~

數據集太小的問題解決后,第二個問題來了——
問題二:分類質量差
這是個簡單但耗時的問題,需要你瀏覽一遍數據集確認每個樣例的標簽打得對不對。
除此以外,一定為你的分類選擇合適的粒度(granularity)。基于要解決的問題,來增加或減少你的分類。
比如,要識別貓,你可以用全局分類器先確定它是動物,之后再用動物分類器確定它是一只小貓。一個大型的模型能同時做到這兩點,但分起類來也更加困難。
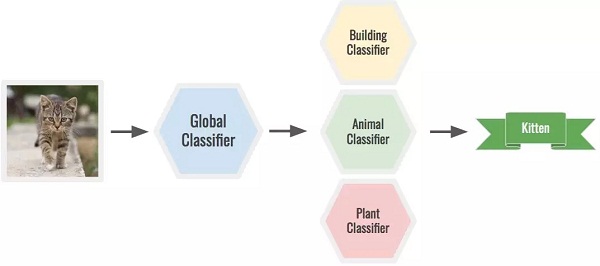
△ 小貓的分類過程
問題三:數據集質量差
就像前言中說的那樣,數據質量差會導致結果的質量差。
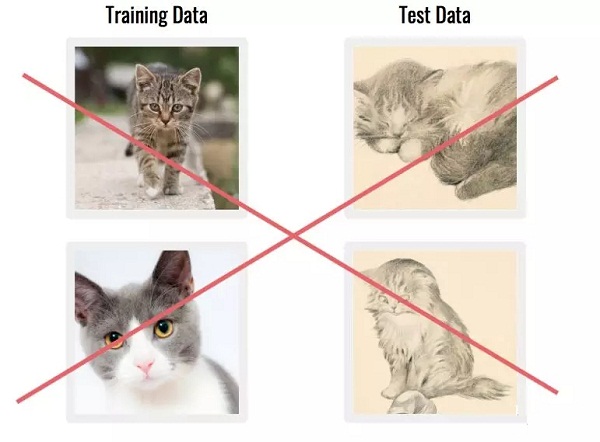
可能你的數據集中有一些樣例離達標真的很遠,比如下面這幾張圖像。

△ 三張不合格的貓咪圖像樣例
這些圖像會干擾模型的正確分類,你需要將這些圖像在數據集中剔除。
雖然是個漫長枯燥的過程,但對結果的提升效果很明顯。
另一個常見問題是,數據集可能是由與實際應用程序不匹配的數據組成的。如果圖像來自完全不同來源,這個問題可能尤為嚴重。
解決方案:先思考一下這項技術的長期應用,因為它關系到獲取生產中的數據。嘗試用相同的工具查找/構建一個數據集。
△ 使用與實際應用差別太大的數據訓練模型非常不明智
問題四:分類不平衡
如果每個分類的樣例數量與其他類別數量差距太大,則模型可能傾向于數量占主導地位的類,因為它會讓錯誤率變低。
解決方案1:
你可以收集更多非代表性的分類。然而這通常需要花費時較多間和金錢,也可能根本不可行。
解決方案2:
對數據進行過采樣/降采樣處理。這意味著你可能需要從那些比例過多的分類中移除一些樣例,也可以在比例較少的類別中進行上面提到過的樣例擴充處理。
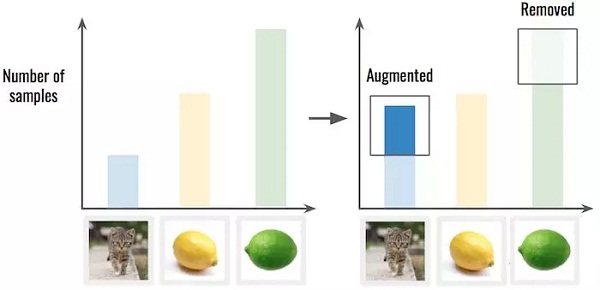
△ 先擴充樣例不足的分類(貓咪),這將使類別的分布更平滑
問題五:數據不平衡
如果你的數據沒有專門的格式,或者它的值沒有在特定的范圍,模型處理起來可能很困難。如果圖像有特定的縱橫比或像素值,得到的結果會更好。
解決方案1:
裁剪或拉伸數據,使其與其他樣例的格式相同,如下圖所示。

△ 裁剪和拉伸是改善格式的兩種方法
解決方案2:
將數據規范化,使每個樣例在相同的值范圍內。

問題六:沒有驗證或測試
數據集被清理、擴充并打上標簽后,你就需要把它們分個組了。
許多數據研究人員會將這些數據分成兩組:80%用于訓練,20%用于測試,這將會使發現過擬合變容易。
然而,如果你在同一個測試集上嘗試多個模型,情況則有所不同。選擇測試精度的***模型,實際上是對測試集進行過擬合處理。
解決方案:
將數據集分為訓練、驗證和測試三組,這可以保護你的測試集,防止它因為所選的模型而過擬合。那這個過程就變成了:
- 在訓練集上訓練模型
- 在驗證集上測試它們,確保它們沒有過擬合
- 選擇***模型,并用測試集測試,看看你的模型準確性有多高。

注意:提醒一句,記得經常用整個數據集去訓練模型,數據越多,效果越好。
總結
***,送廣大數據科學工作者一句N字箴言:
擁有***模型的人不是贏家,擁有***數據的人才是。





















