Hadoop生態系統應用狀況大調查:互聯網篇!
國內外對Hadoop生態系統的生存狀況爭論不休,既然如此,我們不妨摸底調查一番,看看國內一線互聯網公司(具備自我搭建大數據平臺能力的廠商)的大數據平臺是如何搭建的?是否基于Hadoop生態系統?Hadoop的存在感有多少?龐大的Hadoop生態系統中又有哪些組件真正脫穎而出了呢?(本文內容來源于公開資料整理)
BAT之阿里巴巴
如果要論數據,恐怕只有以電商起家的阿里巴巴才能擁有如此豐富且龐大的數據。有業務場景也有技術能力,阿里巴巴的大數據實力不容置疑。目前,阿里巴巴對外提供基于阿里云的大數據服務。眾多大數據產品中,筆者看到了Elasticsearch的身影。
在數據分析和搜索等方面,阿里提供基于開源Elasticsearch及商業版X-Pack插件。Elasticsearch想必大家都不陌生,是繼Hadoop之后非常受歡迎的后起之秀。阿里巴巴的大數據解決方案中會有它的出現一點也不讓人驚訝,有了Elasticsearch還有Hadoop的用武之地嗎?
在阿里巴巴早年的數加平臺(整個大數據部分統稱為數加)介紹中,阿里云大數據事業部數加平臺技術負責人陳廷曾表示,阿里統一的自主可控的大數據平臺是在Hadoop的基礎上構建的,這套平臺支撐了阿里很重要的一些業務,可見Hadoop對于阿里大數據平臺的構建起到了至關重要的作用。
BAT之騰訊
騰訊的數據量雖然也不小,但多來源于社交數據。在離線數據處理的介紹中,我們看到騰訊大數據套件基于Hadoop體系的MapReduce、HIVE、PIG、Spark技術向企業用戶提供強大的數據離線批處理能力。
除此之外,Hadoop生態體系還包括Yarn、HBase、Sqoop、Ambari、Zookeeper、Flume、Kafka、Storm、Spark Streaming、Elastic Search、Impala、Presto、HAWQ、HUE、Log Search、Solr、Kylin。
很多人認為Hadoop生態體系中實力最弱的就是MapReduce,然而目前的騰訊大數據體系中仍然可以看到MapReduce的身影,不知道之后是否會考慮更換。
BAT之百度
百度的數據與上述兩家又不同,百度的數據來源多為搜索數據,依托自身百度引擎。進入百度的大數據產品頁面,可以發現百度主打的招牌是“智能”。百度的大數據產品中應用了大規模的機器學習、深度學習等能力。

百度的大數據基礎套件“魯班”的基礎架構如下,可以很直觀地看到,百度大數據基礎套件中的Kafka和YARN均來源于Hadoop生態系統。
京東:
京東的電商業務和物流業務如今也是越做越大,京東大數據部為了解決公司越來越廣泛的實時業務需求,推出了一整套技術解決方案——JRDW(JD Realtime Data Warehouse)。
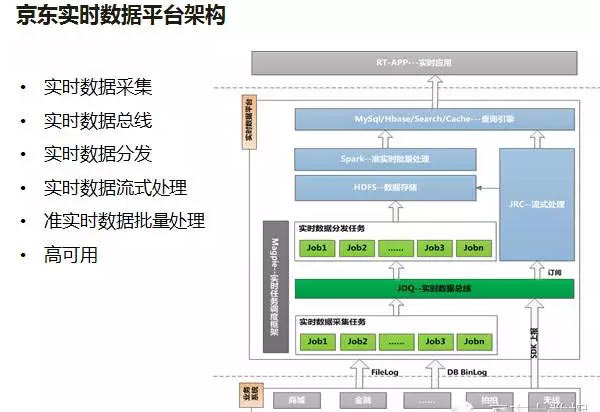
根據介紹,整個大數據平臺有不少開源組件的加入,京東大數據部門在開源組件的基礎上又針對其缺點進行了部分調整,形成了最終框架。在后期的發展中,京東意識到如果要搭建一個穩定可靠的實時任務運行平臺很重要,通過對Storm、Hadoop、HBase、Kafka等的研究,京東自主開發了高可用調度平臺Magpie。
圖中可以很直接地看出Hadoop的身影,明顯Hadoop對其大數據平臺架構的搭建過程起到了啟發作用。
美團:
美團的大數據平臺主要支撐了美團的到店餐飲、到店綜合、酒店旅游、貓眼電影、外賣配送等業務,中間則是基礎數據部,最下層基于美團云。如果將基礎數據部放大,基本如下圖所示:
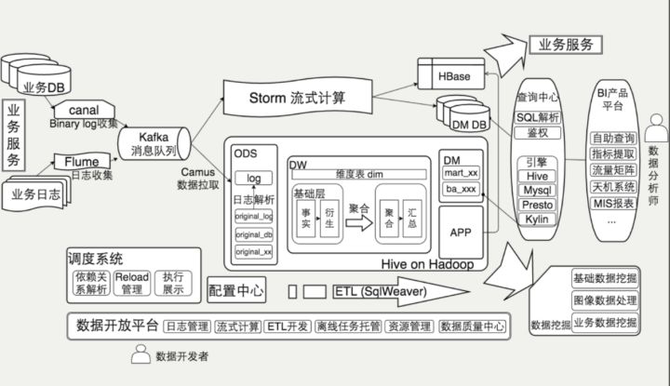
離線計算部分是基于Hadoop的數據倉庫數據應用。具體到組件,基礎服務層有HDFS和YARN的參與,計算引擎層有HBase、Kylin、Hive、Spark、Presto等來自Hadoop生態系統的組件參與。
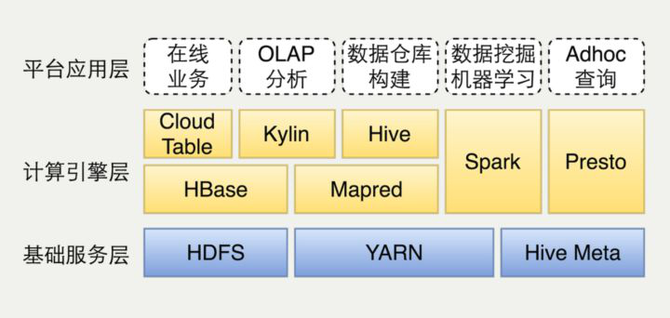
根據一年前的統計數據,這套平臺有42P+總存儲量,每天有15萬個MapReduce和Spark任務,現在想必數據量和復雜度已經再一次升高了。
網易:
網易的一站式大數據管理和應用開發平臺——網易猛犸,覆蓋了大閨蜜數據存儲與計算、應用開發、數據管理與集成等場景。
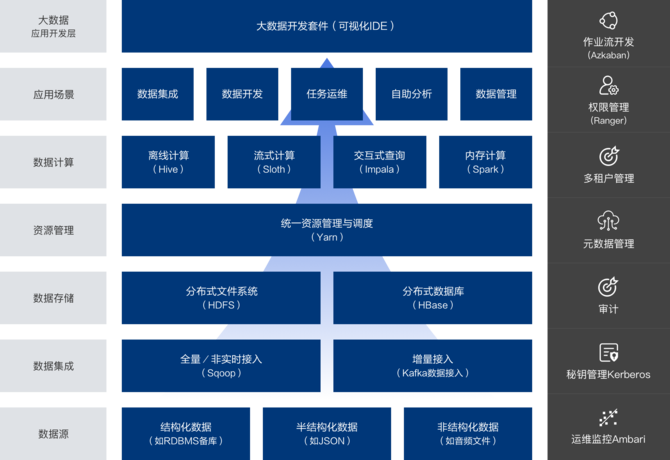
在其公布的大數據架構圖中,我們可以看到底層基本完全構建于Hadoop生態系統,數據集成、數據存儲、資源管理都和Hadoop生態系統有關。這套系統支持HDFS、Hbase、Kudu等從GB到PB級別的存儲方案,支持Hive和MapReduce等批量計算、Spark內存計算、Kylin多維分析等多種計算方案。
今日頭條:
2014年之前,今日頭條并沒有專門的人負責做數據。隨著活躍用戶數的迅猛增長,各種各樣的需求不斷,今日頭條意識到幾個數據工程師單打獨斗根本解決不了問題,于是數據平臺團隊成立了。
該團隊將Hadoop、Hive、Spark和Kylin等封裝成工具,將工具與分析模式相結合包裝成解決方案以提供給業務部門。在數據生成與采集方面,今日頭條使用Spark實現類Sqoop的分布式抓取;在數據傳輸方面,采用Kafka作為數據總線,連接在線和離線系統;在數據計算方面,今日頭條使用了Spark SQL和Hive;在Cube類查詢引擎,今日頭條已經成為Kylin國內最大使用用戶之一。
滴滴:
作為目前最大且最活躍的獨角獸企業,滴滴的大數據架構部門十分年輕,成立時間僅一年有余。去年,滴滴宣布向各地交通管理部門開放“滴滴交通信息平臺”數據,而滴滴當時的平臺日訂單量已經超過2000萬,流量高峰期每分鐘接到的用戶需求高達兩萬次。
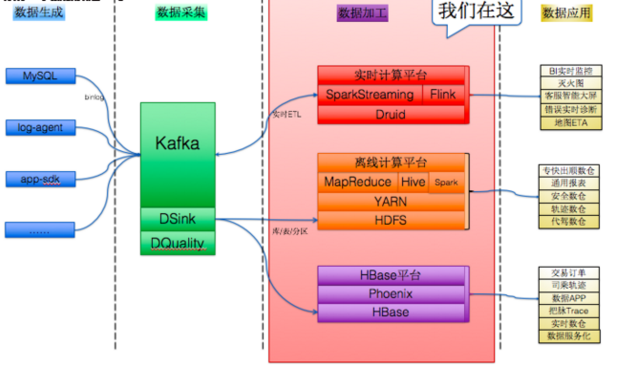
從圖中不難看出,滴滴大數據平臺分為多個組成部分,數據加工和數據采集兩階段明顯用到了不少Hadoop生態系統的組件,數據加工部分完全依托Hadoop生態系統。
知乎
截止2017年8月,知乎注冊用戶數破億,全站DAU達2600萬,月瀏覽量180億......知乎大數據架構分為數據采集、數據計算、數據服務和數據產品層。
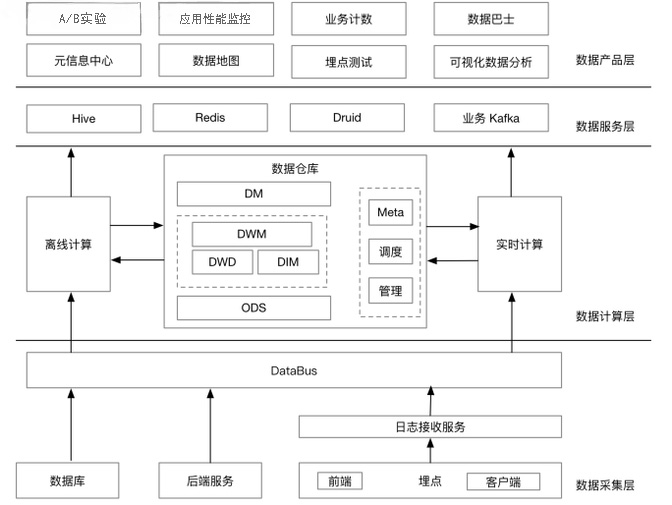
對于很多公司都會出現的MySQL數據實時查詢需求,知乎調研了Hive和HBase,但最后選擇了將BinLog實時打入Kafka,起一套Spark Streaming程序,將數據寫入Kudu,這樣做的性能會更高一些。雖然這部分組件來源Hadoop生態系統,但知乎內部架構師曾表示公司正在考慮采用TiDB。
新浪
新浪同樣掌握著大量社交數據,在之前有關新浪大數據體系架構的介紹中,我們可以了解到新浪的技術架構同樣基于Hadoop生態圈,最下面是日志接受傳輸,然后進入Hadoop層,在這之上是ETL數據的整合,隨后是中央數據倉庫,數據挖掘、實時統計與計算等操作。
近幾年,隨著新技術的不斷發展,新浪的大數據體系也在不斷改變,但Hadoop生態體系依舊占據著重要位置。
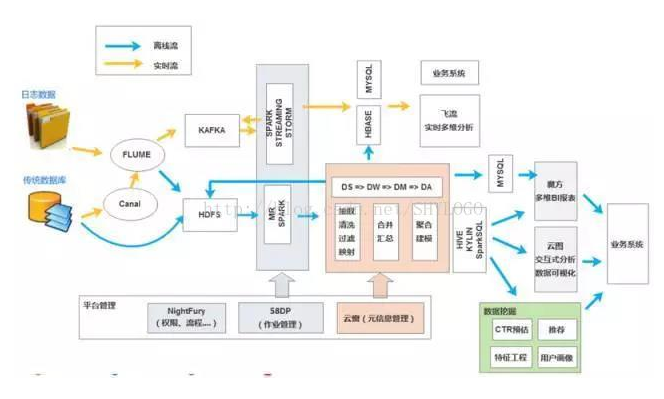
58同城
58的大數據體系主要分為數據應用、數據應用平臺、數據基礎平臺三層。在接入層,58使用了Canal/Sqoop解決數據接入問題,另一部分數據使用Flume,其中Sqoop和Flume均來源于Hadoop生態體系;存儲層全是熟人:HDFS、HBase、Kafka;調度層是Yarn;計算層全部來自于Hadoop生態體系,比如MR、Hive等。
......
總結
最新調查結果顯示,中國每年進口最多的不是石油,而是芯片。國內一線互聯網公司的大數據生態體系建設基本被Hadoop包圓,這種存在感快趕上芯片在中國的地位了。龐大的Hadoop生態體系中,MapReduce、HDFS、Kafka和Yarn的出現頻度最高。然而,不少言論都認為MapReduce的市場競爭力在逐漸減弱,如今這個應用狀況似乎一點失寵的意思都沒有啊!