PaddlePaddle深度學(xué)習(xí)實戰(zhàn)——英法文翻譯機
自然語言處理[1]是計算機科學(xué)領(lǐng)域與人工智能領(lǐng)域中的另一個重要方向,其中很重要的一點就是語音識別(speech recognition)、機器翻譯、智能機器人。
與語言相關(guān)的技術(shù)可以應(yīng)用在很多地方。例如,日本的富國生命保險公司花費170萬美元安裝人工智能系統(tǒng),把客戶的語言轉(zhuǎn)換為文本,并分析這些詞是正面的還是負面的。這些自動化工作將幫助人類更快地處理保險業(yè)務(wù)。除此之外,現(xiàn)在的人工智能公司也在把智能客服作為重點的研究方向。
與圖像識別不同,在自然語言處理中輸入的往往是一段語音或者一段文字,輸入數(shù)據(jù)的長短是不確定的,并且它與上下文有很密切的關(guān)系,所以常用的是循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)模型。
在本節(jié)里,我們將分別介紹自然語言模型的選擇、神經(jīng)機器翻譯的原理,最后,用200余行PaddlePaddle代碼手把手帶領(lǐng)大家做一個英法翻譯機。
自然語言處理模型的選擇
下面我們就來介紹使用不同輸入和不同數(shù)據(jù)時,分別適用哪種模型以及如何應(yīng)用。
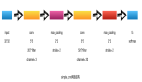
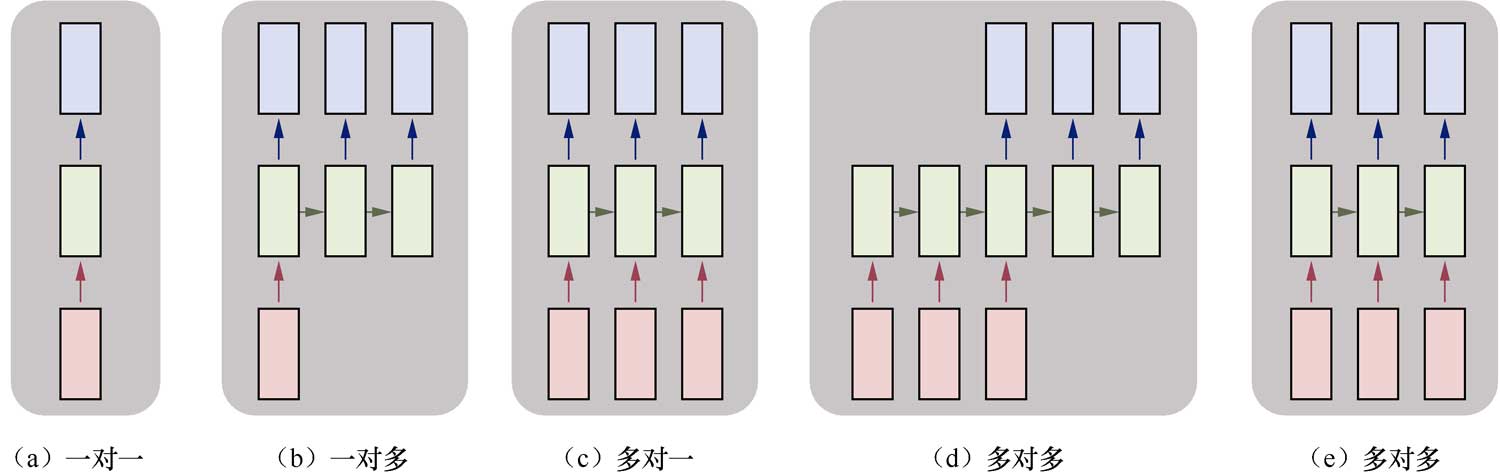
在下圖中,每一個矩形是一個向量,箭頭則表示函數(shù)(如矩陣相乘)。最下面一行為輸入向量,最上面一行為輸出向量,中間一行是RNN的狀態(tài)。
圖中從左到右分別表示以下幾種情況。
(1)一對一:沒有使用RNN,如Vanilla模型,從固定大小的輸入得到固定大小輸出(應(yīng)用在圖像分類)。
(2)一對多:以序列輸出(應(yīng)用在圖片描述,輸入一張圖片輸出一段文字序列,這種往往需要CNN和RNN相結(jié)合,也就是圖像和語言相結(jié)合,詳見第12章)。
圖
(3)多對一:以序列輸入(應(yīng)用在情感分析,輸入一段文字,然后將它分類成積極或者消極情感,如淘寶下某件商品的評論分類),如使用LSTM。
(4)多對多:異步的序列輸入和序列輸出(應(yīng)用在機器翻譯,如一個RNN讀取一條英文語句,然后將它以法語形式輸出)。
(5)多對多:同步的序列輸入和序列輸出(應(yīng)用在視頻分類,對視頻中每一幀打標記)。
我們注意到,在上述講解中,因為中間RNN的狀態(tài)的部分是固定的,可以多次使用,所以不需要對序列長度進行預(yù)先特定約束。更詳細的討論參見Andrej Karpathy的文章《The Unreasonable Effectiveness of Recurrent Neural Networks》[2]。
自然語言處理通常包括語音合成(將文字生成語音)、語音識別、聲紋識別(聲紋鑒權(quán)),以及它們的一些擴展應(yīng)用,以及文本處理,如分詞、情感分析、文本挖掘等。
神經(jīng)機器翻譯原理
機器翻譯的作用就是將一個源語言的序列(如英文Economic growth has slowed down in recent years)轉(zhuǎn)化成目標語言序列(如法文La croissance economique sest ralentie ces dernieres annees)。其中翻譯機器是需要利用已有的語料庫(Corpora)來進行訓(xùn)練。
所謂的神經(jīng)網(wǎng)絡(luò)機器翻譯就是利用神經(jīng)網(wǎng)絡(luò)來實現(xiàn)上述的翻譯機器。基于神經(jīng)網(wǎng)絡(luò)的很多技術(shù)都是從Bengio的那篇開創(chuàng)性論文[3]衍生出來的。這里我們介紹在機器翻譯中最常用的重要技術(shù)及演進。
自然語言處理模型演進概覽
我們知道正如卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)的演進從LeNet到AlexNet,再到VggNet、GoogLeNet,最后到ResNet,演進的方式有一定規(guī)律,并且也在ImageNet LSVRC競賽上用120萬張圖片、1000類標記上取得了很好的成績。循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural networks,RNN)的演進從vanilla RNN到隱藏層結(jié)構(gòu)精巧的GRU和LSTM,再到雙向和多層的Deep Bidirectional RNN,都有一些結(jié)構(gòu)和演化脈絡(luò),下面我們就首先來探討。
Original LSTM
1997年Hochreiter和Schmidhuber首先提出了LSTM的網(wǎng)絡(luò)結(jié)構(gòu),解決了傳統(tǒng)RNN對于較長的序列數(shù)據(jù),訓(xùn)練過程中容易出現(xiàn)梯度消失或爆炸的現(xiàn)象。Original LSTM的結(jié)構(gòu)如下:
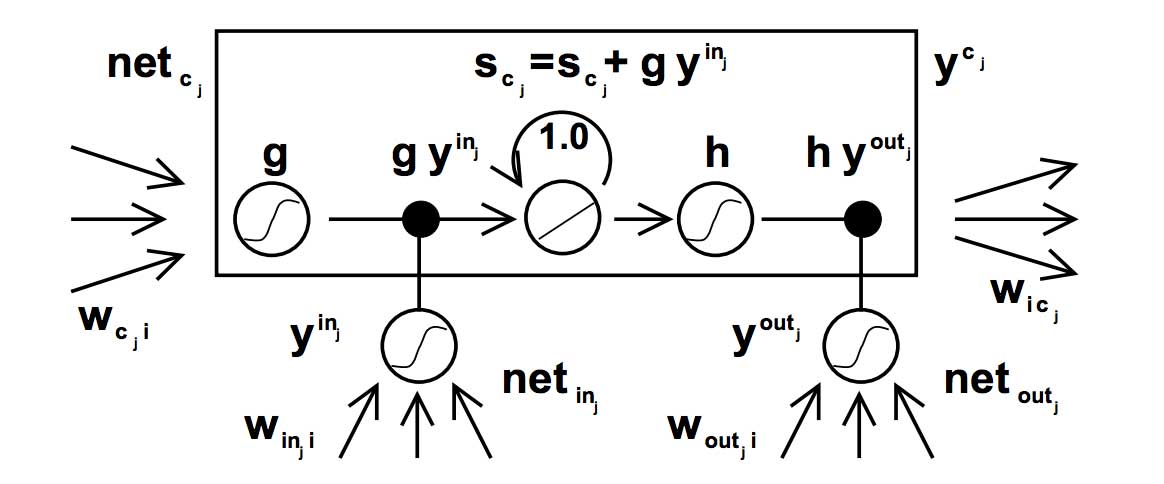
圖
Standard LSTM
但是,傳統(tǒng)的LSTM存在一個問題:隨著時間序列的增多,LSTM網(wǎng)絡(luò)沒有重置機制(比如兩句話合成一句話作為輸入的話,希望是在第一句話結(jié)束的時候進行重置),從而導(dǎo)致cell state容易發(fā)生飽和;另一方面輸出h趨近于1,導(dǎo)致cell的輸出近似等于output gate的輸出,意味著網(wǎng)絡(luò)喪失了memory的功能。相比于簡單的循環(huán)神經(jīng)網(wǎng)絡(luò),LSTM增加了記憶單元、輸入門、遺忘門及輸出門。這些門及記憶單元組合起來大大提升了循環(huán)神經(jīng)網(wǎng)絡(luò)處理長序列數(shù)據(jù)的能力。
Standard LSTM的結(jié)構(gòu)如下:
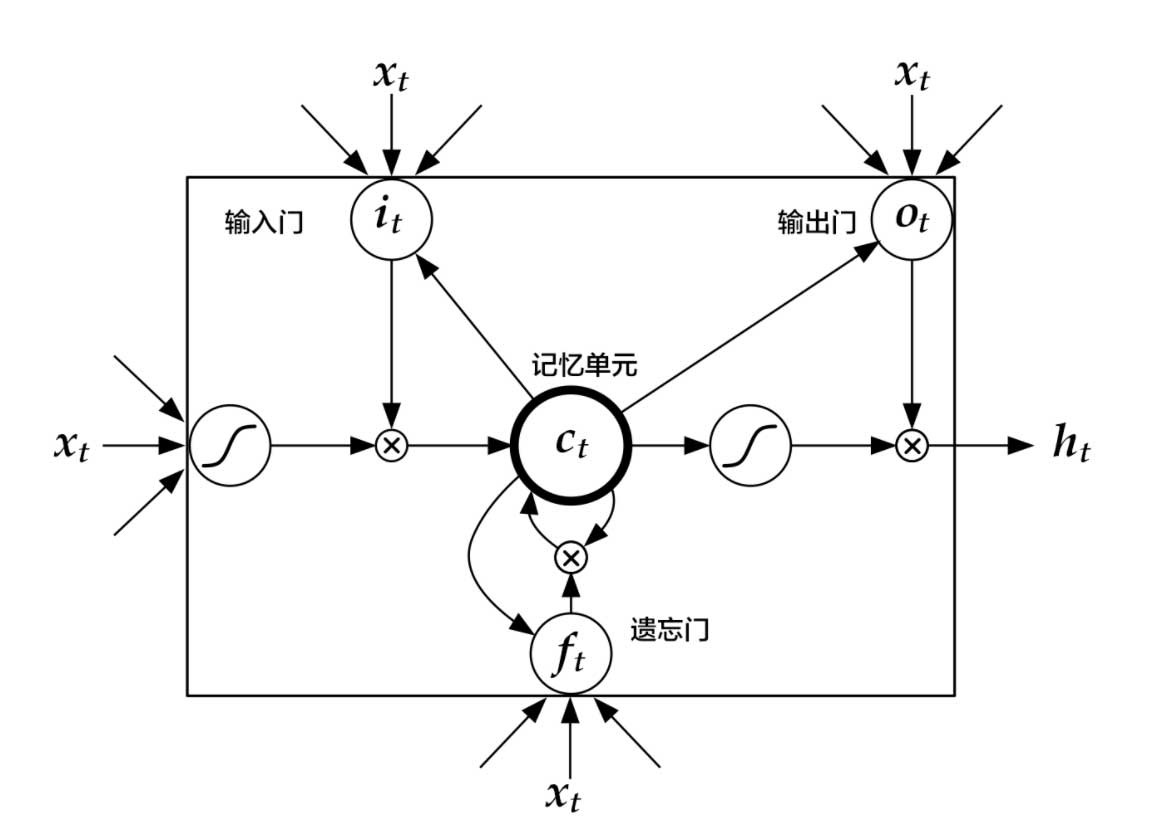
圖[4]
GRU[5]
相比于簡單的RNN,LSTM增加了記憶單元(memory cell)、輸入門(input gate)、遺忘門(forget gate)及輸出門(output gate),這些門及記憶單元組合起來大大提升了RNN處理遠距離依賴問題的能力。
GRU是Cho等人在LSTM上提出的簡化版本,也是RNN的一種擴展,如下圖所示。GRU單元只有兩個門:
- 重置門(reset gate):如果重置門關(guān)閉,會忽略掉歷史信息,即歷史不相干的信息不會影響未來的輸出。
- 更新門(update gate):將LSTM的輸入門和遺忘門合并,用于控制歷史信息對當(dāng)前時刻隱層輸出的影響。如果更新門接近1,會把歷史信息傳遞下去。
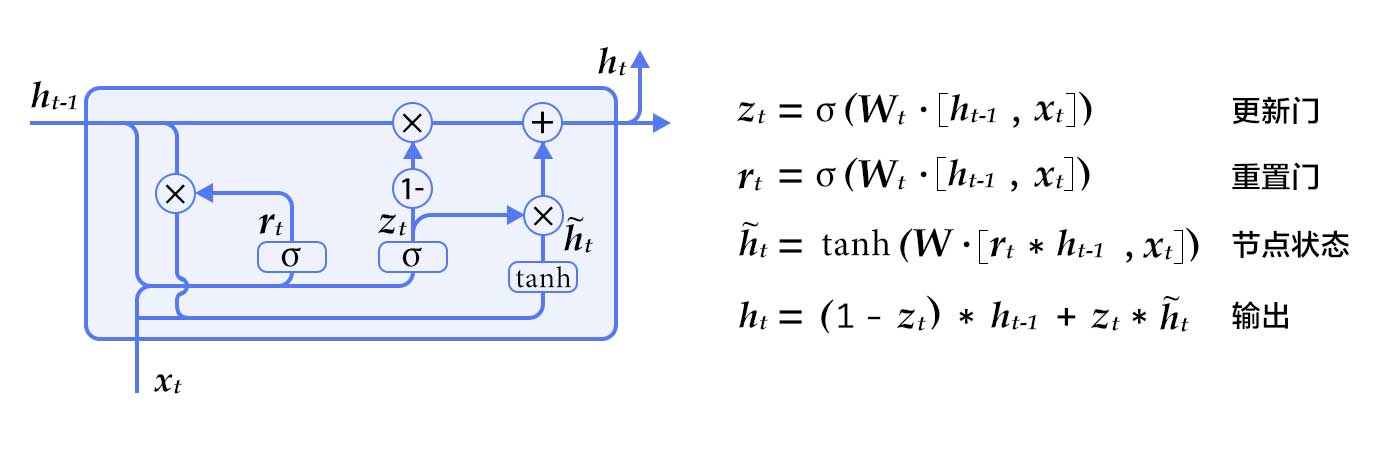
GRU(門控循環(huán)單元)
一般來說,具有短距離依賴屬性的序列,其重置門比較活躍;相反,具有長距離依賴屬性的序列,其更新門比較活躍。GRU雖然參數(shù)更少,但是在多個任務(wù)上都和LSTM有相近的表現(xiàn)。
雙向循環(huán)神經(jīng)網(wǎng)絡(luò)
雙向循環(huán)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的目的是輸入一個序列,得到其在每個時刻的特征表示,即輸出的每個時刻都用定長向量表示到該時刻的上下文語義信息。
具體來說,該雙向循環(huán)神經(jīng)網(wǎng)絡(luò)分別在時間維以順序和逆序——即前向(forward)和后向(backward)——依次處理輸入序列,并將每個時間步RNN的輸出拼接成為最終的輸出層。這樣每個時間步的輸出節(jié)點,都包含了輸入序列中當(dāng)前時刻完整的過去和未來的上下文信息。
下圖展示的是一個按時間步展開的雙向循環(huán)神經(jīng)網(wǎng)絡(luò)。該網(wǎng)絡(luò)包含一個前向和一個后向RNN,其中有六個權(quán)重矩陣:輸入到前向隱層和后向隱層的權(quán)重矩陣(W1,W3W1,W3),隱層到隱層自己的權(quán)重矩陣(W2,W5W2,W5),前向隱層和后向隱層到輸出層的權(quán)重矩陣(W4,W6W4,W6)。注意,該網(wǎng)絡(luò)的前向隱層和后向隱層之間沒有連接。
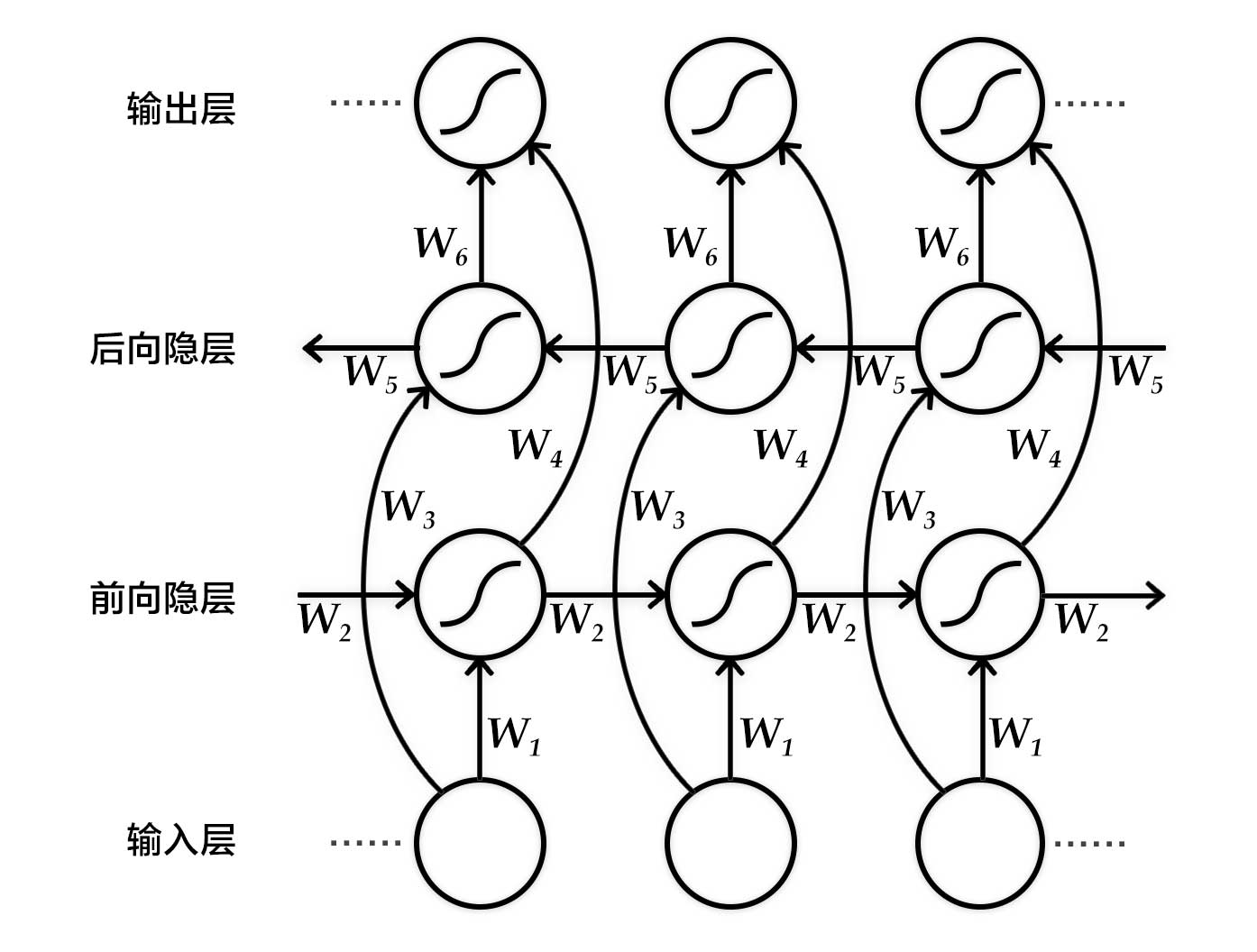
圖 按時間步展開的雙向循環(huán)神經(jīng)網(wǎng)絡(luò)
seq2seq+Attention
seq2seq模型是一個翻譯模型,主要是把一個序列翻譯成另一個序列。它的基本思想是用兩個RNNLM,一個作為編碼器,另一個作為解碼器,組成RNN編碼器-解碼器。
在文本處理領(lǐng)域,我們常用編碼器-解碼器(encoder-decoder)框架,如圖所示。
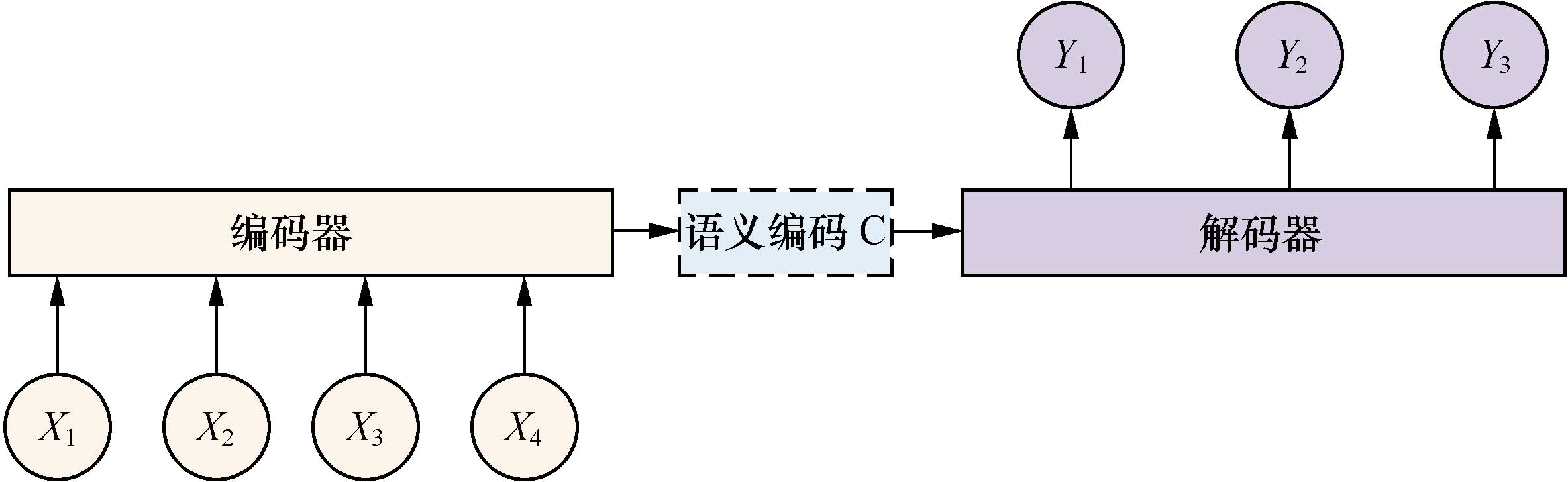
圖
這是一種適合處理由一個上下文(context)生成一個目標(target)的通用處理模型。因此,對于一個句子對<X, Y>,當(dāng)輸入給定的句子X,通過編碼器-解碼器框架來生成目標句子Y。X和Y可以是不同語言,這就是機器翻譯;X和Y可以是對話的問句和答句,這就是聊天機器人;X和Y可以是圖片和這個圖片的對應(yīng)描述(看圖說話)。
X由x1、x2等單詞序列組成,Y也由y1、y2等單詞序列組成。編碼器對輸入的X進行編碼,生成中間語義編碼C,然后解碼器對中間語義編碼C進行解碼,在每個i時刻,結(jié)合已經(jīng)生成的y1, y2,…, yi-1的歷史信息生成Yi。但是,這個框架有一個缺點,就是生成的句子中每一個詞采用的中間語義編碼是相同的,都是C。因此,在句子比較短的時候,還能比較貼切,句子長時,就明顯不合語義了。
在實際實現(xiàn)聊天系統(tǒng)的時候,一般編碼器和解碼器都采用RNN模型以及RNN模型的改進模型LSTM。當(dāng)句子長度超過30以后,LSTM模型的效果會急劇下降,一般此時會引入Attention模型,對長句子來說能夠明顯提升系統(tǒng)效果。
Attention機制是認知心理學(xué)層面的一個概念,它是指當(dāng)人在做一件事情的時候,會專注地做這件事而忽略周圍的其他事。例如,人在專注地看這本書,會忽略旁邊人說話的聲音。這種機制應(yīng)用在聊天機器人、機器翻譯等領(lǐng)域,就把源句子中對生成句子重要的關(guān)鍵詞的權(quán)重提高,產(chǎn)生出更準確的應(yīng)答。
增加了Attention模型的編碼器-解碼器框架如下圖所示。
現(xiàn)在的中間語義編碼變成了不斷變化的Ci,能夠生產(chǎn)更準確的目標Yi。
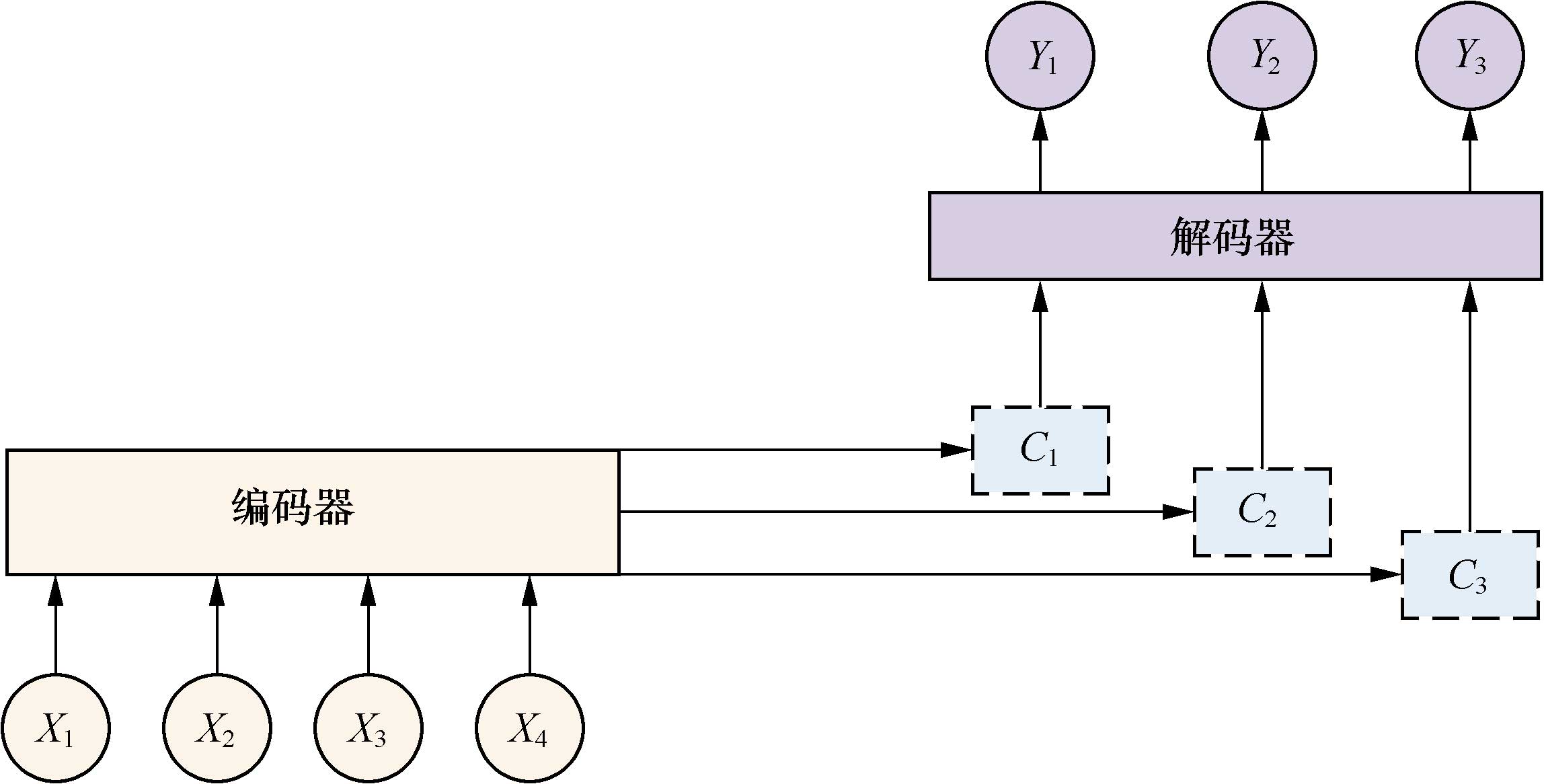
圖
目標結(jié)果展示[6]
以中英翻譯(中文翻譯到英文)的模型為例,當(dāng)模型訓(xùn)練完畢時,如果輸入如下已分詞的中文句子:
這些 是 希望 的 曙光 和 解脫 的 跡象 .
如果設(shè)定顯示翻譯結(jié)果的條數(shù)為3,生成的英語句子如下:
0 -5.36816 These are signs of hope and relief . <e>
1 -6.23177 These are the light of hope and relief . <e>
2 -7.7914 These are the light of hope and the relief of hope . <e>
左起第一列是生成句子的序號;左起第二列是該條句子的得分(從大到小),分值越高越好;左起第三列是生成的英語句子。 另外有兩個特殊標志:<e>表示句子的結(jié)尾,<unk>表示未登錄詞(unknown word),即未在訓(xùn)練字典中出現(xiàn)的詞。
PaddlePaddle最佳實踐[7]
下面我們就來用200余行代碼構(gòu)建一個英法文翻譯機。
數(shù)據(jù)集及數(shù)據(jù)預(yù)處理
本次實踐使用WMT-14[8]數(shù)據(jù)集中的bitexts(after selection)作為訓(xùn)練集,dev+test data作為測試集和生成集。
數(shù)據(jù)集格式如下:
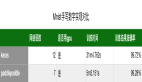
bitexts.selected數(shù)據(jù)集,共12075604行,有大量的并行數(shù)據(jù)的英文/法文對,約850M法文單詞。這個數(shù)據(jù)是相當(dāng)嘈雜的,是神經(jīng)網(wǎng)絡(luò)訓(xùn)練的一大挑戰(zhàn)。因此,官方已經(jīng)執(zhí)行了數(shù)據(jù)選擇來提取最合適的數(shù)據(jù)。
“pc”之后的數(shù)字表示百分比。 一般我們基于短語的基準系統(tǒng)僅在這些數(shù)據(jù)上進行訓(xùn)練。
ep7_pc45 Europarl版本7 (27.8M)
nc9 新聞評論版本9 (5.5M)
2008年至2011年的dev08_11舊開發(fā)數(shù)據(jù) (0.3M)
抓取常見抓取數(shù)據(jù) (90M)
ccb2_pc30 10 ^ 9平行語料庫 (81M)
un2000_pc34 聯(lián)合國語料庫 (143M)
下載后的數(shù)據(jù)文件如下:
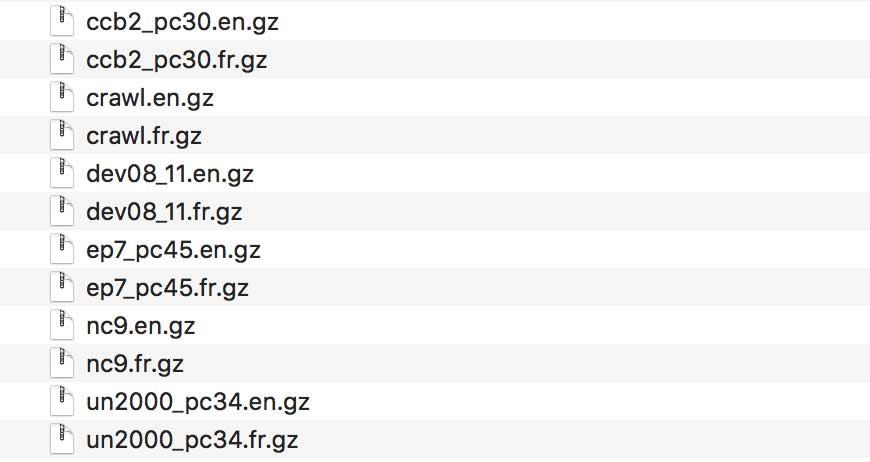
我們打開Europarl版本7(ep7_pc45)數(shù)據(jù)一探究竟。
less ep7_pc45.en

可以看到,英文版本的第8行:Me ?
less ep7_pc45.fr

可以看到,對應(yīng)法文版本的第8行Moi ?
因為完整的數(shù)據(jù)集數(shù)據(jù)量較大,為了驗證訓(xùn)練流程,PaddlePaddle接口paddle.dataset.wmt14中默認提供了一個經(jīng)過預(yù)處理的較小規(guī)模的數(shù)據(jù)集(wmt14)。該數(shù)據(jù)集有193319條訓(xùn)練數(shù)據(jù),6003條測試數(shù)據(jù),詞典長度為30000。我們可以在這個數(shù)據(jù)集上對模型進行實驗;但真正需要訓(xùn)練,還是建議采用原始數(shù)據(jù)集。
我們對這個較小規(guī)模的數(shù)據(jù)集進行預(yù)處理。預(yù)處理后的文件如下:

預(yù)處理流程包括3步:
1.將每個源語言到目標語言的平行語料庫文件合并為一個文件;
2.合并每個XXX.src和XXX.trg文件為XXX。 - XXX中的第i行內(nèi)容為XXX.src中的第i行和XXX.trg中的第i行連接,用'\t'分隔。 如train和test中處理后如下,下圖每一行是一句法文和英文的平行語料,紅框處代表兩句之間用’\t’的分隔:

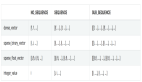
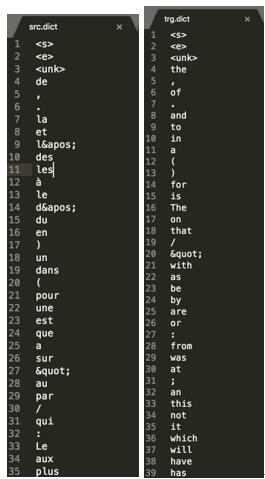
3.創(chuàng)建訓(xùn)練數(shù)據(jù)的“源字典”和“目標字典”。每個字典都有DICTSIZE個單詞,包括:語料中詞頻最高的(DICTSIZE - 3)個單詞,和3個特殊符號<s>(序列的開始)、<e>(序列的結(jié)束)和<unk>(未登錄詞)。得到的src.dict(法文詞典)和trg.dict(英文詞典)分別如下:
最佳實踐[9]
數(shù)據(jù)處理好后,接下來我們就開始編寫代碼搭建神經(jīng)網(wǎng)絡(luò)及訓(xùn)練。[10]
paddle初始化
首先,進行paddle的初始化,直接導(dǎo)入Python版本的Paddle庫,和TensorFlow很相似。
# 加載 paddle的python包
import sys
import paddle.v2 as paddle
# 配置只使用cpu,并且使用一個cpu進行訓(xùn)練
paddle.init(use_gpu=False, trainer_count=1)
# 訓(xùn)練模式False,生成模式True
is_generating = False
全局變量及超參數(shù)定義
這里,因為我們對數(shù)據(jù)預(yù)處理做了30000維的數(shù)據(jù)字典,所以在全局變量中也填寫對應(yīng)的值。
dict_size = 30000 # 字典維度
source_dict_dim = dict_size # 源語言字典維度
target_dict_dim = dict_size # 目標語言字典維度
word_vector_dim = 512 # 詞向量維度
encoder_size = 512 # 編碼器中的GRU隱層大小
decoder_size = 512 # 解碼器中的GRU隱層大小
beam_size = 3 # 柱寬度
max_length = 250 # 生成句子的最大長度
構(gòu)建模型
首先,構(gòu)建編碼器框架:
輸入是一個文字序列,被表示成整型的序列。序列中每個元素是文字在字典中的索引。所以,我們定義數(shù)據(jù)層的數(shù)據(jù)類型為integer_value_sequence(整型序列),序列中每個元素的范圍是[0, source_dict_dim]。
src_word_id = paddle.layer.data(
name='source_language_word',
type=paddle.data_type.integer_value_sequence(source_dict_dim))
將上述編碼映射到低維語言空間的詞向量s。
src_embedding = paddle.layer.embedding(
input=src_word_id, size=word_vector_dim)
用雙向GRU編碼源語言序列,拼接兩個GRU的編碼結(jié)果得到h。
src_forward = paddle.networks.simple_gru(
input=src_embedding, size=encoder_size)
src_backward = paddle.networks.simple_gru(
input=src_embedding, size=encoder_size, reverse=True)
encoded_vector = paddle.layer.concat(input=[src_forward, src_backward])
接著,構(gòu)建基于注意力機制的解碼器框架:
對源語言序列編碼后的結(jié)果(即上面的encoded_vector),過一個前饋神經(jīng)網(wǎng)絡(luò)(Feed Forward Neural Network),得到其映射。
encoded_proj = paddle.layer.fc(
act=paddle.activation.Linear(),
size=decoder_size,
bias_attr=False,
input=encoded_vector)
構(gòu)造解碼器RNN的初始狀態(tài)。
backward_first = paddle.layer.first_seq(input=src_backward)
decoder_boot = paddle.layer.fc(
size=decoder_size,
act=paddle.activation.Tanh(),
bias_attr=False,
input=backward_first)
定義解碼階段每一個時間步的RNN行為。
def gru_decoder_with_attention(enc_vec, enc_proj, current_word):
decoder_mem = paddle.layer.memory(
name='gru_decoder', size=decoder_size, boot_layer=decoder_boot)
context = paddle.networks.simple_attention(
encoded_sequence=enc_vec,
encoded_proj=enc_proj,
decoder_state=decoder_mem)
decoder_inputs = paddle.layer.fc(
act=paddle.activation.Linear(),
size=decoder_size * 3,
bias_attr=False,
input=[context, current_word],
layer_attr=paddle.attr.ExtraLayerAttribute(
error_clipping_threshold=100.0))
gru_step = paddle.layer.gru_step(
name='gru_decoder',
input=decoder_inputs,
output_mem=decoder_mem,
size=decoder_size)
out = paddle.layer.mixed(
size=target_dict_dim,
bias_attr=True,
act=paddle.activation.Softmax(),
input=paddle.layer.full_matrix_projection(input=gru_step))
return out
那在訓(xùn)練模式下的解碼器如何調(diào)用呢?
首先,將目標語言序列的詞向量trg_embedding,直接作為訓(xùn)練模式下的current_word傳給gru_decoder_with_attention函數(shù)。
其次,使用recurrent_group函數(shù)循環(huán)調(diào)用gru_decoder_with_attention函數(shù)。
接著,使用目標語言的下一個詞序列作為標簽層lbl,即預(yù)測目標詞。
最后,用多類交叉熵損失函數(shù)classification_cost來計算損失值。
代碼如下:
if not is_generating:
trg_embedding = paddle.layer.embedding(
input=paddle.layer.data(
name='target_language_word',
type=paddle.data_type.integer_value_sequence(target_dict_dim)),
size=word_vector_dim,
param_attr=paddle.attr.ParamAttr(name='_target_language_embedding'))
group_inputs.append(trg_embedding)
# For decoder equipped with attention mechanism, in training,
# target embeding (the groudtruth) is the data input,
# while encoded source sequence is accessed to as an unbounded memory.
# Here, the StaticInput defines a read-only memory
# for the recurrent_group.
decoder = paddle.layer.recurrent_group(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs)
lbl = paddle.layer.data(
name='target_language_next_word',
type=paddle.data_type.integer_value_sequence(target_dict_dim))
cost = paddle.layer.classification_cost(input=decoder, label=lbl)
那生成(預(yù)測)模式下的解碼器如何調(diào)用呢?
首先,在序列生成任務(wù)中,由于解碼階段的RNN總是引用上一時刻生成出的詞的詞向量,作為當(dāng)前時刻的輸入,
其次,使用beam_search函數(shù)循環(huán)調(diào)用gru_decoder_with_attention函數(shù),生成出序列id。
if is_generating:
# In generation, the decoder predicts a next target word based on
# the encoded source sequence and the previous generated target word.
# The encoded source sequence (encoder's output) must be specified by
# StaticInput, which is a read-only memory.
# Embedding of the previous generated word is automatically retrieved
# by GeneratedInputs initialized by a start mark <s>.
trg_embedding = paddle.layer.GeneratedInput(
size=target_dict_dim,
embedding_name='_target_language_embedding',
embedding_size=word_vector_dim)
group_inputs.append(trg_embedding)
beam_gen = paddle.layer.beam_search(
name=decoder_group_name,
step=gru_decoder_with_attention,
input=group_inputs,
bos_id=0,
eos_id=1,
beam_size=beam_size,
max_length=max_length)
訓(xùn)練模型
1.構(gòu)造數(shù)據(jù)定義
我們獲取wmt14的dataset reader。
if not is_generating:
wmt14_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.wmt14.train(dict_size=dict_size), buf_size=8192),
batch_size=5)
2.構(gòu)造trainer
根據(jù)優(yōu)化目標cost,網(wǎng)絡(luò)拓撲結(jié)構(gòu)和模型參數(shù)來構(gòu)造出trainer用來訓(xùn)練,在構(gòu)造時還需指定優(yōu)化方法,這里使用最基本的SGD方法。
if not is_generating:
optimizer = paddle.optimizer.Adam(
learning_rate=5e-5,
regularization=paddle.optimizer.L2Regularization(rate=8e-4))
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=optimizer)
3.構(gòu)造event_handler
可以通過自定義回調(diào)函數(shù)來評估訓(xùn)練過程中的各種狀態(tài),比如錯誤率等。下面的代碼通過event.batch_id % 2 == 0 指定每2個batch打印一次日志,包含cost等信息。
if not is_generating:
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 2 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
4.啟動訓(xùn)練
if not is_generating:
trainer.train(
reader=wmt14_reader, event_handler=event_handler, num_passes=2)
隨后,就可以開始訓(xùn)練了。訓(xùn)練開始后,可以觀察到event_handler輸出的日志如下:
Pass 0, Batch 0, Cost 148.444983, {'classification_error_evaluator': 1.0}
.........
Pass 0, Batch 10, Cost 335.896802, {'classification_error_evaluator': 0.9325153231620789}
.........
預(yù)測模型
我們加載預(yù)訓(xùn)練的模型,然后從wmt14生成集中讀取樣本,試著生成結(jié)果。
1.加載預(yù)訓(xùn)練的模型
if is_generating:
parameters = paddle.dataset.wmt14.model()
2. 數(shù)據(jù)定義
從wmt14的生成集中讀取前3個樣本作為源語言句子。
if is_generating:
gen_creator = paddle.dataset.wmt14.gen(dict_size)
gen_data = []
gen_num = 3
for item in gen_creator():
gen_data.append((item[0], ))
if len(gen_data) == gen_num:
break
3. 構(gòu)造infer
根據(jù)網(wǎng)絡(luò)拓撲結(jié)構(gòu)和模型參數(shù)構(gòu)造出infer用來生成,在預(yù)測時還需要指定輸出域field,這里使用生成句子的概率prob和句子中每個詞的id。
if is_generating:
beam_result = paddle.infer(
output_layer=beam_gen,
parameters=parameters,
input=gen_data,
field=['prob', 'id'])
4.打印生成結(jié)果
根據(jù)源/目標語言字典,將源語言句子和beam_size個生成句子打印輸出。
if is_generating:
# load the dictionary
src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
gen_sen_idx = np.where(beam_result[1] == -1)[0]
assert len(gen_sen_idx) == len(gen_data) * beam_size
# -1 is the delimiter of generated sequences.
# the first element of each generated sequence its length.
start_pos, end_pos = 1, 0
for i, sample in enumerate(gen_data):
print(" ".join([src_dict[w] for w in sample[0][1:-1]]))
for j in xrange(beam_size):
end_pos = gen_sen_idx[i * beam_size + j]
print("%.4f\t%s" % (beam_result[0][i][j], " ".join(
trg_dict[w] for w in beam_result[1][start_pos:end_pos])))
start_pos = end_pos + 2
print("\n")
生成開始后,可以觀察到輸出的日志如下:

日志的第一行為源語言的句子。下面的三行分別是分數(shù)由高到低排列的生成的英文翻譯結(jié)果。
總結(jié)
這里我們著重講解了自然語言處理當(dāng)中神經(jīng)機器翻譯的原理,以及如何用200余行PaddlePaddle代碼做一個英法翻譯機。更多的,PaddlePaddle在
線性回歸、識別數(shù)字、圖像分類、詞向量、個性化推薦、情感分析、語義角色標注等各個領(lǐng)域也有非常成熟的應(yīng)用和簡潔易上手示例,期待和大家一起探討。
1.廣義的自然語言處理包含語音處理及文本處理,狹義的單指理解和處理文本。這里指廣義的概念。 ↑
2.http://karpathy.github.io/2015/05/21/rnn-effectiveness/ ↑
3.《A Neural Probabilistic Language Model》 ↑
4.https://github.com/PaddlePaddle/book/blob/develop/06.understand_sentiment/README.cn.md ↑
5.http://staging.paddlepaddle.org/docs/develop/book/08.machine_translation/index.cn.html#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE ↑
6.http://staging.paddlepaddle.org/docs/develop/book/08.machine_translation/index.cn.html#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE ↑
7.http://staging.paddlepaddle.org/docs/develop/book/08.machine_translation/index.cn.html#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE ↑
8.http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/ ↑
9.http://staging.paddlepaddle.org/docs/develop/book/08.machine_translation/index.cn.html#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE ↑
10.https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/train.py ↑