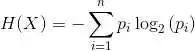使用Python從頭開始構建決策樹算法
決策樹(Decision Tree)是一種常見的機器學習算法,被廣泛應用于分類和回歸任務中。并且再其之上的隨機森林和提升樹等算法一直是表格領域的最佳模型,所以本文將介紹理解其數學概念,并在Python中動手實現,這可以作為了解這類算法的基礎知識。
在深入研究代碼之前,我們先要了解支撐決策樹的數學概念:熵和信息增益
熵:雜質的量度
熵作為度量來量化數據集中的雜質或無序。特別是對于決策樹,熵有助于衡量與一組標簽相關的不確定性。數學上,數據集S的熵用以下公式計算:
Entropy(S) = -p_pos * log2(p_pos) - p_neg * log2(p_neg)P_pos表示數據集中正標簽的比例,P_neg表示數據集中負標簽的比例。
更高的熵意味著更大的不確定性或雜質,而更低的熵意味著更均勻的數據集。
信息增益:通過拆分提升知識
信息增益是評估通過基于特定屬性劃分數據集所獲得的熵的減少。也就是說它衡量的是執行分割后標簽確定性的增加。
數學上,對數據集S中屬性a進行分割的信息增益計算如下:
Information Gain(S, A) = Entropy(S) - ∑ (|S_v| / |S|) * Entropy(S_v)S 表示原始數據集,A表示要拆分的屬性。S_v表示屬性A保存值v的S的子集。
目標是通過選擇使信息增益最大化的屬性,在決策樹中創建信息量最大的分割。
在Python中實現決策樹算法
有了以上的基礎,就可以使用Python從頭開始編寫Decision Tree算法。
首先導入基本的numpy庫,它將有助于我們的算法實現。
import numpy as np創建DecisionTree類
class DecisionTree:
def __init__(self, max_depth=None):
self.max_depth = max_depth定義了DecisionTree類來封裝決策樹。max_depth參數是樹的最大深度,以防止過擬合。
def fit(self, X, y, depth=0):
n_samples, n_features = X.shape
unique_classes = np.unique(y)
# Base cases
if (self.max_depth is not None and depth >= self.max_depth) or len(unique_classes) == 1:
self.label = unique_classes[np.argmax(np.bincount(y))]
return擬合方法是決策樹算法的核心。它需要訓練數據X和相應的標簽,以及一個可選的深度參數來跟蹤樹的深度。我們以最簡單的方式處理樹的生長:達到最大深度或者遇到純類。
確定最佳分割屬性,循環遍歷所有屬性以找到信息增益最大化的屬性。_information_gain方法(稍后解釋)幫助計算每個屬性的信息增益。
best_attribute = None
best_info_gain = -1
for feature in range(n_features):
info_gain = self._information_gain(X, y, feature)
if info_gain > best_info_gain:
best_info_gain = info_gain
best_attribute = feature處理不分割屬性,如果沒有屬性產生正的信息增益,則將類標簽分配為節點的標簽。
if best_attribute is None:
self.label = unique_classes[np.argmax(np.bincount(y))]
return分割和遞歸調用,下面代碼確定了分割的最佳屬性,并創建兩個子節點。根據屬性的閾值將數據集劃分為左右兩個子集。
self.attribute = best_attribute
self.threshold = np.median(X[:, best_attribute])
left_indices = X[:, best_attribute] <= self.threshold
right_indices = ~left_indices
self.left = DecisionTree(max_depth=self.max_depth)
self.right = DecisionTree(max_depth=self.max_depth)
self.left.fit(X[left_indices], y[left_indices], depth + 1)
self.right.fit(X[right_indices], y[right_indices], depth + 1)并且通過遞歸調用左子集和右子集的fit方法來構建子樹。
預測方法使用訓練好的決策樹進行預測。如果到達一個葉節點(帶有標簽的節點),它將葉節點的標簽分配給X中的所有數據點。
def predict(self, X):
if hasattr(self, 'label'):
return np.array([self.label] * X.shape[0])當遇到非葉節點時,predict方法根據屬性閾值遞歸遍歷樹的左子樹和右子樹。來自雙方的預測被連接起來形成最終的預測數組。
is_left = X[:, self.attribute] <= self.threshold
left_predictions = self.left.predict(X[is_left])
right_predictions = self.right.predict(X[~is_left])
return np.concatenate((left_predictions, right_predictions))下面兩個方法是決策樹的核心代碼,并且可以使用不同的算法來進行計算,比如ID3 算法使用信息增益作為特征選擇的標準,該標準度量了將某特征用于劃分數據后,對分類結果的不確定性減少的程度。算法通過遞歸地選擇信息增益最大的特征來構建決策樹,也就是我們現在要演示的算法。
_information_gain方法計算給定屬性的信息增益。它計算分裂后子熵的加權平均值,并從父熵中減去它。
def _information_gain(self, X, y, feature):
parent_entropy = self._entropy(y)
unique_values = np.unique(X[:, feature])
weighted_child_entropy = 0
for value in unique_values:
is_value = X[:, feature] == value
child_entropy = self._entropy(y[is_value])
weighted_child_entropy += (np.sum(is_value) / len(y)) * child_entropy
return parent_entropy - weighted_child_entropy熵的計算
def _entropy(self, y):
_, counts = np.unique(y, return_counts=True)
probabilities = counts / len(y)
return -np.sum(probabilities * np.log2(probabilities))_entropy方法計算數據集y的熵,它計算每個類的概率,然后使用前面提到的公式計算熵。
常見的算法還有:
C4.5 是 ID3 的改進版本,C4.5 算法在特征選擇時使用信息增益比,這是對信息增益的一種歸一化,用于解決信息增益在選擇特征時偏向于取值較多的特征的問題。
CART 與 ID3 和 C4.5 算法不同,CART(Classification And Regression Tree)又被稱為分類回歸樹,算法采用基尼不純度(Gini impurity)來度量節點的不確定性,該不純度度量了從節點中隨機選取兩個樣本,它們屬于不同類別的概率。
ID3、C4.5 和 CART 算法都是基于決策樹的經典算法,像Xgboost就是使用的CART 作為基礎模型。
總結
以上就是使用Python中構造了一個完整的決策樹算法的全部。決策樹的核心思想是根據數據的特征逐步進行劃分,使得每個子集內的數據盡量屬于同一類別或具有相似的數值。在構建決策樹時,通常會使用一些算法來選擇最佳的特征和分割點,以達到更好的分類或預測效果。