如何爬取電影天堂的最新電影
前面兩篇文章介紹 requests 和 xpath 的用法。我們推崇學以致用,所以本文講解利用這兩個工具進行實戰。
0 爬取目標
本次爬取的站點選擇電影天堂,網址是: www.dytt8.net。爬取內容是整個站點的所有電影信息,包括電影名稱,導演、主演、下載地址等。具體抓取信息如下圖所示:

1 設計爬蟲程序
2.1 確定爬取入口
電影天堂里面的電影數目成千上萬,電影類型也是讓人眼花繚亂。我們為了保證爬取的電影信息不重復, 所以要確定一個爬取方向。目前這情況真讓人無從下手。但是,我們點擊主頁中的【最新電影】選項,跳進一個新的頁面。驀然有種柳暗花明又一村的感覺。
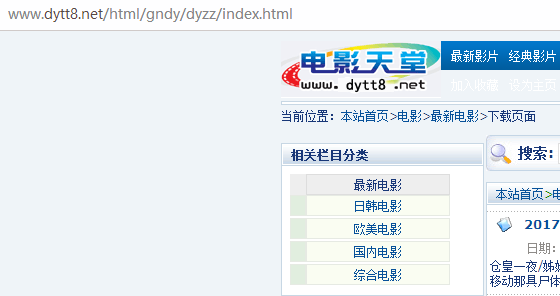
由圖可知道,電影天堂有 5 個電影欄目,分別為最新電影、日韓電影、歐美電影、國內電影、綜合電影。每個欄目又有一定數量的分頁,每個分頁有 25 條電影信息。那么程序的入口可以有 5 個 url 地址。這 5 個地址分別對應每個欄目的首頁鏈接。
2.2 爬取思路
知道爬取入口,后面的工作就容易多了。我通過測試發現這幾個欄目除了頁面的 url 地址不一樣之外,其他例如提取信息的 xpath 路徑是一樣的。因此,我把 5 個欄目當做 1 個類,再該類進行遍歷爬取。
我這里“最新電影”為例說明爬取思路。
1)請求欄目的首頁來獲取到分頁的總數,以及推測出每個分頁的 url 地址;
2)將獲取到的分頁 url 存放到名為 floorQueue 隊列中;
3)從 floorQueue 中依次取出分頁 url,然后利用多線程發起請求;
4)將獲取到的電影頁面 url 存入到名為 middleQueue 的隊列;
5)從 middleQueue 中依次取出電影頁面 url,再利用多線程發起請求;
6)將請求結果使用 Xpath 解析并提取所需的電影信息;
7)將爬取到的電影信息存到名為 contentQueue 隊列中;
8)從 contentQueue 隊列中依次取出電影信息,然后存到數據庫中。
2.3 設計爬蟲架構
根據爬取思路,我設計出爬蟲架構。如下圖所示:
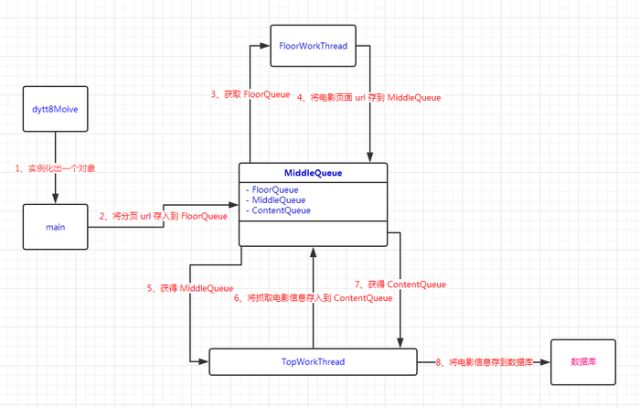
2.4 代碼實現
主要闡述幾個重要的類的代碼
- main 類
主要工作兩個:第一,實例化出一個dytt8Moive對象,然后開始爬取信息。第二,等爬取結束,將數據插入到數據庫中。
處理爬蟲的邏輯代碼如下:
- # 截止到2017-08-08, 最新電影一共才有 164 個頁面
- LASTEST_MOIVE_TOTAL_SUM = 6 #164
- # 請求網絡線程總數, 線程不要調太好, 不然會返回很多 400
- THREAD_SUM = 5
- def startSpider():
- # 實例化對象
- # 獲取【最新電影】有多少個頁面
- LASTEST_MOIVE_TOTAL_SUM = dytt_Lastest.getMaxsize()
- print('【最新電影】一共 ' + str(LASTEST_MOIVE_TOTAL_SUM) + ' 有個頁面')
- dyttlastest = dytt_Lastest(LASTEST_MOIVE_TOTAL_SUM)
- floorlist = dyttlastest.getPageUrlList()
- floorQueue = TaskQueue.getFloorQueue()
- for item in floorlist:
- floorQueue.put(item, 3)
- # print(floorQueue.qsize())
- for i in range(THREAD_SUM):
- workthread = FloorWorkThread(floorQueue, i)
- workthread.start()
- while True:
- if TaskQueue.isFloorQueueEmpty():
- break
- else:
- pass
- for i in range(THREAD_SUM):
- workthread = TopWorkThread(TaskQueue.getMiddleQueue(), i)
- workthread.start()
- while True:
- if TaskQueue.isMiddleQueueEmpty():
- break
- else:
- pass
- insertData()
- if __name__ == '__main__':
- startSpider()
創建數據庫以及表,接著再把電影信息插入到數據庫的代碼如下:
- def insertData():
- DBName = 'dytt.db'
- db = sqlite3.connect('./' + DBName, 10)
- conn = db.cursor()
- SelectSql = 'Select * from sqlite_master where type = "table" and name="lastest_moive";'
- CreateTableSql = '''
- Create Table lastest_moive (
- 'm_id' INTEGER PRIMARY KEY,
- 'm_type' varchar(100),
- 'm_trans_name' varchar(200),
- 'm_name' varchar(100),
- 'm_decade' varchar(30),
- 'm_conutry' varchar(30),
- 'm_level' varchar(100),
- 'm_language' varchar(30),
- 'm_subtitles' varchar(100),
- 'm_publish' varchar(30),
- 'm_IMDB_socre' varchar(50),
- 'm_douban_score' varchar(50),
- 'm_format' varchar(20),
- 'm_resolution' varchar(20),
- 'm_size' varchar(10),
- 'm_duration' varchar(10),
- 'm_director' varchar(50),
- 'm_actors' varchar(1000),
- 'm_placard' varchar(200),
- 'm_screenshot' varchar(200),
- 'm_ftpurl' varchar(200),
- 'm_dytt8_url' varchar(200)
- );
- '''
- InsertSql = '''
- Insert into lastest_moive(m_type, m_trans_name, m_name, m_decade, m_conutry, m_level, m_language, m_subtitles, m_publish, m_IMDB_socre,
- m_douban_score, m_format, m_resolution, m_size, m_duration, m_director, m_actors, m_placard, m_screenshot, m_ftpurl,
- m_dytt8_url)
- values(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
- '''
- if not conn.execute(SelectSql).fetchone():
- conn.execute(CreateTableSql)
- db.commit()
- print('==== 創建表成功 ====')
- else:
- print('==== 創建表失敗, 表已經存在 ====')
- count = 1
- while not TaskQueue.isContentQueueEmpty():
- item = TaskQueue.getContentQueue().get()
- conn.execute(InsertSql, Utils.dirToList(item))
- db.commit()
- print('插入第 ' + str(count) + ' 條數據成功')
- count = count + 1
- db.commit()
- db.close()
TaskQueue 類
維護 floorQueue、middleQueue、contentQueue 三個隊列的管理類。之所以選擇隊列的數據結構,是因為爬蟲程序需要用到多線程,隊列能夠保證線程安全。
dytt8Moive 類
dytt8Moive 類是本程序的主心骨。程序最初的爬取目標是 5 個電影欄目,但是目前只現實了爬取最新欄目。如果你想爬取全部欄目電影,只需對 dytt8Moive 稍微改造下即可。
- class dytt_Lastest(object):
- # 獲取爬蟲程序抓取入口
- breakoutUrl = 'http://www.dytt8.net/html/gndy/dyzz/index.html'
- def __init__(self, sum):
- self.sum = sum
- # 獲取【最新電影】有多少個頁面
- # 截止到2017-08-08, 最新電影一共才有 164 個頁面
- @classmethod
- def getMaxsize(cls):
- response = requests.get(cls.breakoutUrl, headers=RequestModel.getHeaders(), proxies=RequestModel.getProxies(), timeout=3)
- # 需將電影天堂的頁面的編碼改為 GBK, 不然會出現亂碼的情況
- response.encoding = 'GBK'
- selector = etree.HTML(response.text)
- # 提取信息
- optionList = selector.xpath("//select[@name='sldd']/text()")
- return len(optionList) - 1 # 因首頁重復, 所以要減1
- def getPageUrlList(self):
- '''
- 主要功能:目錄頁url取出,比如:http://www.dytt8.net/html/gndy/dyzz/list_23_'+ str(i) + '.html
- '''
- templist = []
- request_url_prefix = 'http://www.dytt8.net/html/gndy/dyzz/'
- templist = [request_url_prefix + 'index.html']
- for i in range(2, self.sum + 1):
- templist.append(request_url_prefix + 'list_23_' + str(i) + '.html')
- for t in templist:
- print('request url is ### ' + t + ' ###')
- return templist
- @classmethod
- def getMoivePageUrlList(cls, html):
- '''
- 獲取電影信息的網頁鏈接
- '''
- selector = etree.HTML(html)
- templist = selector.xpath("//div[@class='co_content8']/ul/td/table/tr/td/b/a/@href")
- # print(len(templist))
- # print(templist)
- return templist
- @classmethod
- def getMoiveInforms(cls, url, html):
- '''
- 解析電影信息頁面的內容, 具體如下:
- 類型 : 疾速特攻/疾速追殺2][BD-mkv.720p.中英雙字][2017年高分驚悚動作]
- ◎譯名 : ◎譯\u3000\u3000名\u3000疾速特攻/殺神John Wick 2(港)/捍衛任務2(臺)/疾速追殺2/極速追殺:第二章/約翰·威克2
- ◎片名 : ◎片\u3000\u3000名\u3000John Wick: Chapter Two
- ◎年代 : ◎年\u3000\u3000代\u30002017
- ◎國家 : ◎產\u3000\u3000地\u3000美國
- ◎類別 : ◎類\u3000\u3000別\u3000動作/犯罪/驚悚
- ◎語言 : ◎語\u3000\u3000言\u3000英語
- ◎字幕 : ◎字\u3000\u3000幕\u3000中英雙字幕
- ◎上映日期 :◎上映日期\u30002017-02-10(美國)
- ◎IMDb評分 : ◎IMDb評分\xa0 8.1/10 from 86,240 users
- ◎豆瓣評分 : ◎豆瓣評分\u30007.7/10 from 2,915 users
- ◎文件格式 : ◎文件格式\u3000x264 + aac
- ◎視頻尺寸 : ◎視頻尺寸\u30001280 x 720
- ◎文件大小 : ◎文件大小\u30001CD
- ◎片長 : ◎片\u3000\u3000長\u3000122分鐘
- ◎導演 : ◎導\u3000\u3000演\u3000查德·史塔赫斯基 Chad Stahelski
- ◎主演 :
- ◎簡介 : 暫不要該字段
- ◎獲獎情況 : 暫不要該字段
- ◎海報
- 影片截圖
- 下載地址
- '''
- # print(html)
- contentDir = {
- 'type': '',
- 'trans_name': '',
- 'name': '',
- 'decade': '',
- 'conutry': '',
- 'level': '',
- 'language': '',
- 'subtitles': '',
- 'publish': '',
- 'IMDB_socre': '',
- 'douban_score': '',
- 'format': '',
- 'resolution': '',
- 'size': '',
- 'duration': '',
- 'director': '',
- 'actors': '',
- 'placard': '',
- 'screenshot': '',
- 'ftpurl': '',
- 'dytt8_url': ''
- }
- selector = etree.HTML(html)
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/p/text()")
- # 匹配出來有兩張圖片, 第一張是海報, 第二張是電影畫面截圖
- imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/p/img/@src")
- # print(content)
- # 為了兼容 2012 年前的頁面
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/span/text()")
- # 有些頁面特殊, 需要用以下表達式來重新獲取信息
- # 電影天堂頁面好混亂啊~
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/text()")
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/font/text()")
- if len(content) < 5:
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/p/font/text()")
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/span/text()")
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/span/text()")
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/font/text()")
- if not len(content):
- content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/text()")
- # print(content)
- # 不同渲染頁面要采取不同的抓取方式抓取圖片
- if not len(imgs):
- imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/img/@src")
- if not len(imgs):
- imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/img/@src")
- if not len(imgs):
- imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/img/@src")
- if not len(imgs):
- imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/img/@src")
- # 類型
- if content[0][0:1] != '◎':
- contentDir['type'] = '[' + content[0]
- actor = ''
- for each in content:
- if each[0:5] == '◎譯\u3000\u3000名':
- # 譯名 ◎譯\u3000\u3000名\u3000 一共占居6位
- contentDir['trans_name'] = each[6: len(each)]
- elif each[0:5] == '◎片\u3000\u3000名':
- # 片名
- contentDir['name'] = each[6: len(each)]
- elif each[0:5] == '◎年\u3000\u3000代':
- # 年份
- contentDir['decade'] = each[6: len(each)]
- elif each[0:5] == '◎產\u3000\u3000地':
- # 產地
- contentDir['conutry'] = each[6: len(each)]
- elif each[0:5] == '◎類\u3000\u3000別':
- # 類別
- contentDir['level'] = each[6: len(each)]
- elif each[0:5] == '◎語\u3000\u3000言':
- # 語言
- contentDir['language'] = each[6: len(each)]
- elif each[0:5] == '◎字\u3000\u3000幕':
- # 字幕
- contentDir['subtitles'] = each[6: len(each)]
- elif each[0:5] == '◎上映日期':
- # 上映日期
- contentDir['publish'] = each[6: len(each)]
- elif each[0:7] == '◎IMDb評分':
- # IMDb評分
- contentDir['IMDB_socre'] = each[9: len(each)]
- elif each[0:5] == '◎豆瓣評分':
- # 豆瓣評分
- contentDir['douban_score'] = each[6: len(each)]
- elif each[0:5] == '◎文件格式':
- # 文件格式
- contentDir['format'] = each[6: len(each)]
- elif each[0:5] == '◎視頻尺寸':
- # 視頻尺寸
- contentDir['resolution'] = each[6: len(each)]
- elif each[0:5] == '◎文件大小':
- # 文件大小
- contentDir['size'] = each[6: len(each)]
- elif each[0:5] == '◎片\u3000\u3000長':
- # 片長
- contentDir['duration'] = each[6: len(each)]
- elif each[0:5] == '◎導\u3000\u3000演':
- # 導演
- contentDir['director'] = each[6: len(each)]
- elif each[0:5] == '◎主\u3000\u3000演':
- # 主演
- actor = each[6: len(each)]
- for item in content:
- if item[0: 4] == '\u3000\u3000\u3000\u3000':
- actor = actor + '\n' + item[6: len(item)]
- # 主演
- contentDir['actors'] = actor
- # 海報
- if imgs[0] != None:
- contentDir['placard'] = imgs[0]
- # 影片截圖
- if imgs[1] != None:
- contentDir['screenshot'] = imgs[1]
- # 下載地址
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/table/tbody/tr/td/a/text()")
- # 為了兼容 2012 年前的頁面
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/table/tbody/tr/td/font/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/table/tbody/tr/td/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/table/tbody/tr/td/font/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/table/tbody/tr/td/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/table/tbody/tr/td/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/span/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/div/table/tbody/tr/td/font/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/span/table/tbody/tr/td/font/a/text()")
- if not len(ftp):
- ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/span/div/table/tbody/tr/td/font/a/text()")
- contentDir['ftpurl'] = ftp[0]
- # 頁面鏈接
- contentDir['dytt8_url'] = url
- print(contentDir)
- return contentDir
getMoiveInforms 方法是主要負責解析電影信息節點并將其封裝成字典。在代碼中,你看到 Xpath 的路徑表達式不止一條。因為電影天堂的電影詳情頁面的排版參差不齊,所以單單一條內容提取表達式、海報和影片截圖表達式、下載地址表達式遠遠無法滿足。
選擇字典類型作為存儲電影信息的數據結構,也是自己爬坑之后才決定的。這算是該站點另一個坑人的地方。電影詳情頁中有些內容節點是沒有,例如類型、豆瓣評分,所以無法使用列表按順序保存。
2 爬取結果
我這里展示自己爬取最新欄目中 4000 多條數據中前面部分數據。
附:源代碼地址(https://link.jianshu.com/?t=https://github.com/monkey-soft/MoivesSpider)