













云計算開源產業聯盟發布融合數據白皮書,Apache CarbonData成為主流融合存儲技術
為了更好的探討如何引導IT基礎設施向更加智能化的方向發展,構建部署靈活、自動化的云環境,開創產業的嶄新未來,12月22日,由中國信息通信研究院主辦,云計算開源產業聯盟承辦,中國移動蘇州研發中心協辦的“2017首屆全球存儲大會”在北京國賓酒店舉行。在會議上,云計算開源產業聯盟融合數據項目組組長,中國信息通信研究院馬飛博士代表項目組,發布了《融合數據白皮書***部分:融合數據存儲》。

馬飛博士表示,在大數據時代,大型企業數據爆發式增長。在企業快速轉型過程中,企業數據處理場景日益豐富,數據分析要求越來越靈活,從傳統的報表分析、OLAP、OLTP業務,到新興的批處理、實時數據分析、機器學習,新的數據分析模式層出不窮。但是,不同數據處理架構對底層數據的存儲/組織、檢索(引擎),乃至處理接口都提出不同要求,對一份數據需要配套構建多套不同結構的數據集,導致數據冗余嚴重,數據不能共享。這導致了平臺維護成本、數據冗余和數據轉換代價的與日俱增,嚴重阻礙了大數據分析技術的應用和發展。而融合數據存儲通過一份數據存儲,可以實現海量復雜數據(總量達到EB級的,單表數據達百億行級別以上,單表屬性維度達百維以上的數據)的歸并,并支持多維度任意組合查詢和分析,支持多種快速查詢需求(如過濾查詢、快速掃描、詳單查詢等)的統一響應。將有效解決多業務場景下多份數據存儲的問題。因此,融合數據是大數據未來的發展方向。

馬飛博士介紹了不同行業對融合數據存儲的不同需求,以及目前業界典型的大數據系統存儲方案,在面對行業融合數據存儲需求時的局限和不足。并介紹了以Apache社區的ORC、Parquet和CarbonData等為代表的目前業界主流的融合存儲技術,這些主流技術的技術對比,以及在10億數據規模下的過濾查詢場景和聚合計算場景下的性能對比。

表1 開源融合數據存儲技術特性對比
|
ORC |
Parquet |
CarbonData |
|
|
開源 |
Apache***項目 |
Apache***項目 |
Apache***項目 |
|
社區活躍度 |
中 (10 commits/month) |
中 (10 commits/month) |
高 (300+commits/month) |
|
大數據生態集成 |
支持所有計算框架集成,與Hive集成較好 |
支持所有計算框架集成,與Spark集成較好 |
支持所有計算框架集成,與Spark集成較好 |
|
開發語言 |
Java |
Java |
Java,Scala |
|
索引 |
粗粒度,不支持全局索引 |
粗粒度,不支持全局索引 |
支持全局索引 |
|
編碼 |
RLE、DELTA |
RLE、DELTA |
全局字段編碼、RLE、DELTA |
|
數據更新、刪除 |
支持 |
不支持 |
支持 |
|
數據分區 |
支持 |
支持 |
支持 |
|
數據壓縮率 |
3-9倍 |
3-8倍 |
3-7倍 |
|
數據預聚合 |
不支持 |
不支持 |
支持 |
|
實時數據導入 |
不支持 |
不支持 |
支持 |
|
時序數據分析 |
部分支持 |
部分支持 |
支持 |
|
文本數據分析 |
不支持 |
不支持 |
支持 |
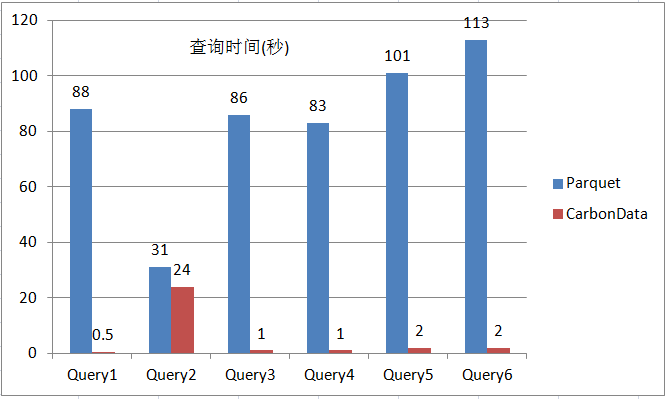
圖6 Parquet和CarbonData在過濾查詢場景下的性能對比
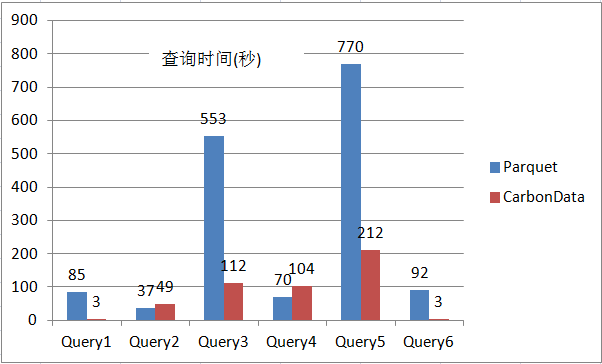
圖7 Parquet和CarbonData在聚合計算場景下的性能對比
***,馬飛博士也就融合存儲技術的發展進行了展望。希望一方面用戶企業積極參與開源社區的活動,通過貢獻需求與場景,推動融合數據存儲技術的業務落地。另一方面利用產業組織、會展活動、技術交流等場合加強廠商間的溝通與合作,共同促進技術的發展與應用水平的提升。
Apache® CarbonData™介紹:
Apache® CarbonData™是由華為開源貢獻的大數據高效存儲格式解決方案。Apache® CarbonData™致力于推動大數據開源技術的持續發展,以一份數據同時滿足多種業務場景訴求,打造高效、開放、完整生態的大數據新融合數倉存儲方案。目前,CarbonData技術已經在華為云MRS服務獲得使用。華為云MRS服務,在完全兼容開源組件的基礎上,融合CarbonData優勢,支持大規模的數據存儲、分析和計算,為客戶提供云時代企業級一站式大數據服務,幫助企業輕松駕馭海量數據,洞察數據價值,在商海中占得先機。
點擊了解華為云存儲產品:http://www.huaweicloud.com/product/

















