數(shù)據(jù)庫中間件TDDL調(diào)研筆記
前篇:《數(shù)據(jù)庫中間件cobar調(diào)研筆記》
13年底負責數(shù)據(jù)庫中間件設(shè)計時的調(diào)研筆記,拿出來和大家分享,輕拍。
一、TDDL是什么
- TDDL是Taobao Distribute Data Layer的簡稱
- 淘寶一個基于客戶端的數(shù)據(jù)庫中間件產(chǎn)品
- 基于JDBC規(guī)范,沒有server,以client-jar的形式存在
畫外音:數(shù)據(jù)庫中間件有基于服務(wù)端的,也有基于客戶端的,TDDL屬于后者;而cobar是一個中間層服務(wù),使用mysql協(xié)議,屬于前者。
二、TDDL不支持什么SQL
- 不支持各類join
- 不支持多表查詢
- 不支持between/and
- 不支持not(除了支持not like)
- 不支持comment,即注釋
- 不支持for update
- 不支持group by中having后面出現(xiàn)集函數(shù)
- 不支持force index
- 不支持mysql獨有的大部分函數(shù)
畫外音:分布式數(shù)據(jù)庫中間件,join都是很難支持的,cobar號稱的對join的支持即有限,又低效。
三、TDDL支持什么SQL
- 支持CURD基本語法
- 支持as
- 支持表名限定,即"table_name.column"
- 支持like/not like
- 支持limit,即mysql的分頁語法
- 支持in
- 支持嵌套查詢,由于不支持多表,只支持單表的嵌套查詢
畫外音:分布式數(shù)據(jù)庫中間件,支持的語法都很有限,但對于與聯(lián)網(wǎng)的大數(shù)據(jù)/高并發(fā)應(yīng)用,足夠了,服務(wù)層應(yīng)該做更多的事情。
四、TDDL其他特性
- 支持oracle和mysql
- 支持主備動態(tài)切換
- 支持帶權(quán)重的讀寫分離
- 支持分庫分表
- 支持主鍵生成:oracle用sequence來生成,mysql則需要建立一個用于生成id的表
- 支持單庫事務(wù),不支持夸庫事務(wù)
- 支持多庫多表分頁查詢,但會隨著翻頁,性能降低
畫外音:可以看到,其實TDDL很多東西都不支持,那么為什么它還如此流行呢?它解決的根本痛點是“分布式”“分庫分表”等。
加入了解決“分布式”“分庫分表”的中間件后,SQL功能必然受限,但是,我們應(yīng)該考慮到:MYSQL的CPU和MEM都是非常珍貴的,我們應(yīng)該將MYSQL從復(fù)雜的計算(事務(wù),JOIN,自查詢,存儲過程,視圖,用戶自定義函數(shù),,,)中釋放解脫出來,將這些計算遷移到服務(wù)層。
當然,有些后臺系統(tǒng)或者支撐系統(tǒng),數(shù)據(jù)量小或者請求量小,沒有“分布式”的需求,為了簡化業(yè)務(wù)邏輯,寫了一些復(fù)雜的SQL語句,利用了MYSQL的功能,這類系統(tǒng)并不是分布式數(shù)據(jù)庫中間件的潛在用戶,也不可能強行讓這些系統(tǒng)放棄便利,使用中間件。
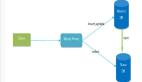
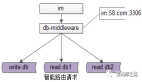
五、TDDL層次結(jié)構(gòu)
構(gòu)")
TDDL是一個客戶端jar,它的結(jié)構(gòu)分為三層:
構(gòu)分為三層")
對應(yīng)上面圖例:matrix數(shù)據(jù)水平分為了兩個group,每個group有主備atom組成。
matrix層
- 核心是規(guī)則引擎
- 實現(xiàn)分庫分表
- 主要路徑:sql解析 => 規(guī)則引擎計算(路由) => 執(zhí)行 => 合并結(jié)果
group層
- 讀寫分離
- 權(quán)重計算
- 寫HA切換
- 讀HA切換
- 動態(tài)新增slave(atom)節(jié)點
atom層
- 單個數(shù)據(jù)庫的抽象;
- ip /port /user /passwd /connection 動態(tài)修改,動態(tài)化jboss數(shù)據(jù)源
- thread count(線程計數(shù)):try catch模式,保護業(yè)務(wù)處理線程
- 動態(tài)阻止某些sql的執(zhí)行
- 執(zhí)行次數(shù)的統(tǒng)計和限制
整個SQL執(zhí)行過程
- BEGIN(sql+args),輸入是sql和參數(shù)
- sql解析
- 規(guī)則計算
- 表名替換
- 選擇groupDS執(zhí)行sql
- 根據(jù)權(quán)重選擇atomDS
- 具備重試策略的在atomDS執(zhí)行sql
- 讀寫控制,并發(fā)控制,執(zhí)行sql,返回結(jié)果
- 合并結(jié)果集
- END(ResultSet),輸出是結(jié)果集
畫外音:感覺難點在SQL的解析上。
六、TDDL***實踐
- 盡可能使用1對多規(guī)則中的1進行數(shù)據(jù)切分(patition key),例如“用戶”就是一個簡單好用的緯度
- 買家賣家的多對多問題,使用數(shù)據(jù)增量復(fù)制的方式冗余數(shù)據(jù),進行查詢
- 利用表結(jié)構(gòu)的冗余,減少走網(wǎng)絡(luò)的次數(shù),買家賣家都存儲全部的數(shù)據(jù)
畫外音:這里我展開一下這個使用場景。
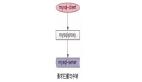
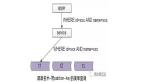
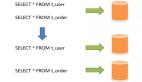
以電商的買家賣家為例,業(yè)務(wù)方既有基于買家的查詢需求,又有基于賣家的查詢需求,但通常只能以一個緯度進行數(shù)據(jù)的分庫(patition),假設(shè)以買家分庫, 那賣家的查詢需求如何實現(xiàn)呢?

如上圖所示:查詢買家所有買到的訂單及商品可以直接定位到某一個分庫,但要查詢賣家所有賣出的商品,業(yè)務(wù)方就必須遍歷所有的買家?guī)欤缓髮Y(jié)果集進行合并,才能滿足需求。
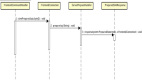
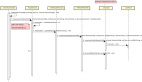
所謂的“數(shù)據(jù)增量復(fù)制”“表結(jié)構(gòu)冗余”“減少網(wǎng)絡(luò)次數(shù)”,是指所有的數(shù)據(jù)以買家賣家兩個緯度冗余存儲兩份,如下圖:

采用一個異步的消息隊列機制,將數(shù)據(jù)以另一個緯度增量復(fù)制一份,在查詢的時候,可以直接以賣家直接定位到相應(yīng)的分庫。
這種方式有潛在的數(shù)據(jù)不一致問題。
繼續(xù)tddl***實踐:
(1) 利用單機資源:單機事務(wù),單機join
(2) 存儲模型盡量做到以下幾點:
- 盡可能走內(nèi)存
- 盡可能將業(yè)務(wù)要查詢的數(shù)據(jù)物理上放在一起
- 通過數(shù)據(jù)冗余,減少網(wǎng)絡(luò)次數(shù)
- 合理并行,提升響應(yīng)時間
- 讀瓶頸通過增加slave(atom)解決
- 寫瓶頸通過切分+路由解決
畫外音:相比數(shù)據(jù)庫中間件內(nèi)核,***實踐與存儲模型,對我們有更大的借鑒意義。
七、TDDL的未來?
- kv是一切數(shù)據(jù)存取最基本的組成部分
- 存儲節(jié)點少做一點,業(yè)務(wù)代碼就要多做一點
- 想提升查詢速度,只有冗余數(shù)據(jù)一條路可走
- 類結(jié)構(gòu)化查詢語言,對查詢來說非常方便
畫外音:潛臺詞是,在大數(shù)據(jù)量高并發(fā)下,SQL不是大勢所趨,no-sql和定制化的協(xié)議+存儲才是未來方向?
13年底的調(diào)研筆記,文中的“畫外音”是我當時的批注,希望能讓大家對TDDL能有一個初步的認識,有疑問之處,歡迎交流。
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】