數據庫中間件cobar調研筆記
13年底負責數據庫中間件設計時的調研筆記,拿出來和大家分享、輕拍。
一、cobar是什么
- 阿里開源的mysql的中間件服務
- 使用mysql協議
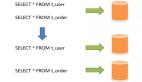
- 對上游,cobar就是傳統mysql數據庫
- 對上游,它屏蔽后端分布式mysql集群
畫外音:數據庫中間件有基于服務端的,也有基于客戶端的,cobar屬于前者。
二、cobar應用場景舉例

邏輯上:
- 數據庫dbtest(虛擬的)
- 表tb1和tb2
物理上:
- tb1表的數據在dbtest1(物理的)的tb1上
- tb2表的一部分數據在dbtest2(物理的)的tb2上,另外一部分在dbtest3(物理的)的tb2上
三、cobar使用方式
- 命令行:連dbtest虛擬庫
- JDBC:也是連dbtest虛擬庫

查看db:

可看到dbtest1、dbtest2、dbtest3對用戶透明。
查看table:

可看到有tb1和tb2兩張表。
插入一些數據,對用戶而言,后端的分布式mysql是透明的:
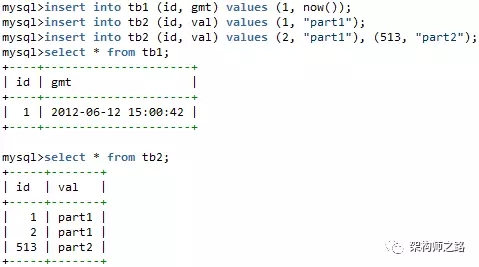
- 對tb1,數據實際上存在dbtest1的tb1中
- 對tb2,數據實際上存儲在dbtest2和dbtest3的tb2中
畫外音:從其官網上看,自12年12月之后,cobar就沒有再更新過,官方微博也非常不活躍,不清楚現在它在阿里的使用情況,知道的同學請說一說。
四、cobar不支持什么
- 不支持夸庫join,分頁,排序,子查詢
- set語句會被忽略(事務和字符集設置除外)
- 如果分庫,insert必須包含patition key(否則麻煩大了)
- 如果分庫,patition key不能被update
- 不支持讀寫分離
- 不支持存儲過程
- 如果使用JDBC,rewriteBatchedStatements,useServerPrepStmts,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()
五、cobar支持什么
1. 分布式數據庫:通過分庫實現
- 支持一張表放到不同的庫
- 支持不同的表放入不同的庫
需要注意:不支持將test拆分成test_1,test_2,test_3并放入同一個庫中這樣的拆分方式。
畫外音:后者正是360的atals的做法(atlas只支持單實例單庫分表)。
2. HA:通過到mysql的心跳實現
- 主機掛了會自動切換回備機,但主機恢復,需要手動切回
- 只檢測主備異常,不關心主備數據同步(需要dba手動配)
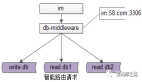
畫外音:需要注意,cobar是需要用戶自己來實現負載均衡的,方式有三種:
- 自己使用軟件例如LVS
- 自己使用硬件例如F5
- cobar提供了命令獲取集群信息,用戶可以根據這些信息做負載均衡;當然,淘寶已經實現了一個具有負載均衡功能的cobar客戶端產品-cobar.driver
3. SQL路由
在分庫的情況下,cobar會從sql中提取partition key列,來判斷SQL被路由到哪一個分庫進行執行;如果沒有帶partition key,則會將SQL分發到所有分庫執行。
4. 示例
tb1(id INT)
假設以id切分數據,后端分了N個庫:
- insert into tb1 values(1);
- => N個庫都會執行插入,因為沒有帶partition key;
- insert into tb1(id) values(1);
- => 只會路由到1個庫,帶了partition key;
- update tb1 set id=2 where id=1;
- => 不支持,不能修改partition key;
畫外音:SQL帶上partition key對cobar來說,非常非常重要,并且partition key不支持修改(修改了庫就不對了喲)。
cobar不允許在同一個連接中切換庫。
畫外音:數據庫連接和庫是綁定關系。
不建議通過cobar來執行DDL語句。
畫外音:所以建庫,建索引什么的,還是直連mysql自己搞吧。
5. COBAR自定義語句
(1) 查詢cobar節點的狀態
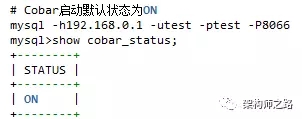
cobar允許管理員通過管理命令上線和下線cobar節點。
(2) 查詢cobar集群的狀態

被定義在一個cobar集群中的cobar節點之間都會發送心跳,所謂的心跳就是上面提到的show cobra_status; 這樣的話,就為每一個cobar節點提供了知道同一個集群內的所有cobar信息的機會。當然,被下線,或者心跳超時的cobar節點的信息不會被顯示出來。
(3) 查詢SQL語句的路由情況

SQL語句前加上explain即可知道SQL語句的路由情況。
6. 事務的支持
cobar對單庫保持事務的強一致性。
對分庫保持事務的弱一致性。
分庫后事務提交包含兩個階段:
- 執行階段:SQL按照規則被路由到多個分庫,此時發生錯誤,還能回滾
- 提交階段:提交階段出錯,無法正確回滾

兩個階段之間,執行與提交串行處理,階段內部各個分庫并行處理。
畫外音:額,基本就是不支持分布式事務。
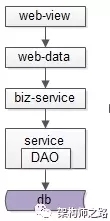
六、cobar系統架構
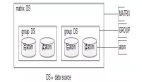
1. 系統模塊圖

畫外音:從模塊圖來看,cobar的結構還是挺清晰的:
(1) 前端對上游的連接池
(2) 后端對下游mysql的連接池
(3) 對每一個請求,會經過:
- SQL分析
- SQL路由
- SQL執行
- 投遞給后端mysql
(4) 對每一個響應,需要做結果合并
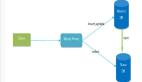
2. 數據流圖
數據流圖和上述模塊圖對應:

3. 網絡模型
采用異步網絡模型:

4. 結果合并
會把多個物理庫的結果集合并,再返回給上游:

七、cobar路由算法
- partition key是int時:好辦,直接取模
- partition key是string時:f(string) = hash(string) % 1024
假設分4個庫:
- 哈希結果0-255 -> 庫1
- 哈希結果256-511 -> 庫2
- 哈希結果512-767 -> 庫3
- 哈希結果768-1024 -> 庫4
如何擴容:
- 哈希結果0-255 -> 庫1
拆分后:
- 哈希結果0-127 -> 庫1.1
- 哈希結果128-255 -> 庫1.2
數據非均勻分布路由:
- 哈希結果0-511(513范圍) -> 庫1
- 哈希結果512-767(256范圍) -> 庫2
- 哈希結果768-895(128范圍) -> 庫3
- 哈希結果896-1023(128范圍) -> 庫4
八、cobar對于SQL的轉發
1. 帶partition key單記錄查詢

直接根據partition key路由。
2. 帶partition key的IN查詢

將IN進行拆分,請求發到對應多個分庫,然后將結果集合并。
3. 不帶partition key的where查詢

假設partition key是user字段,在product字段上的where查詢,會將請求廣播到所有分庫,然后將結果集合并。
4. 二維partition key
一張表的多個字段同時作為定位庫的拆分字段,仍以上圖的visit(product, user, info)為例,可以以product和user兩個字段來同時來定位庫。

橫坐標product屬性取hash,縱坐標user屬性取hash。

- SELECT * FROM visit WHERE product=‘ColaCola’ AND user=‘A’
對于上述業務需求,同時帶有兩個列作為查詢條件,可以直接定位到庫7。
但是,此時如果只有其中的一個字段作為查詢條件,反而得查詢多個庫,再做聚合:

- SELECT * FROM visit WHERE product=‘ColaCola’
對于上述業務需求,就必須查詢庫3,7,11,15了。
畫外音:不懂為什么要按照雙key來做路由,單key路由,對于雙key的查詢,也沒有增加多少數據掃描量啊,加入雙key反而使得某些情況下策略復雜了,帶來的收益也不高。
5. 小結
對的,對于where,cobar就是這樣的處理方式:
- 根據字段的一致性hash分布數據
- 多維拆分
- 根據where中的partition key分發查詢
- SQL語句變換,分發至各個分庫執行,對結果進行合并
九、cobar的高級特性
1. JOIN有限的處理

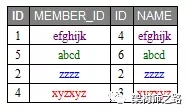
如上,兩個表都進行了分庫,JOIN需求如下:
- SELECT * FROM tb1 INNER JOIN tb2
- ON tb1.MEMBER_ID=tb2.NAME
結果集理應如下:
方案一:迭代查詢
- FOR row1 IN select * FROM tb1{
- ADD(
- SELECT* FROM tb2 WHERE
- tb2.name = row1.member_id
- )TO RESULT
- }
畫外音:我去,外層循環是對tb1中的所有記錄,在tb2來一遍掃描,bt1數據量大的情況下,這哪里受得了?
方案二:夸庫索引
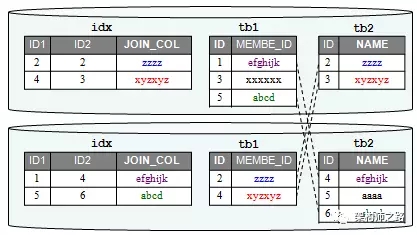
對于tb1和tb2存在的潛在JOIN需求,對JOIN列建立夸庫索引。
- 直接JOIN查詢:建立了夸庫索引后,對于JOIN的直接查詢,就是idx索引表內的數據的合并就是結果
- JOIN后帶WHERE條件:
- SELECT * FROM tb1 INNER JOIN tb2
- ON tb1.MEMBER_ID=tb2.NAME
- WHEREtb1.id=5
此時需要改寫SQL語句,直接在索引表上進行查詢:
- 此時需要改寫SQL語句,直接在索引表上進行查詢:
- SELECT * FROM idx WHERE id1=5
此處需要注意:
- 索引表的partition key:WHERE條件所在表的partition key,作為索引表的partition key
- 索引必須包含參與JOIN相關表的主鍵,JOIN字段,包含WHERE條件的字段
- 索引的更新:需要分布式事務的支持
2. GROUP BY的處理

以上表為例,patition key是ID,要在C1上進行GROUP BY操作:
- SELECT SUM(price) FROM tb1 GROUP BY c1;
改寫SQL語句,先在各個分庫上GROUP BY一次,并將sum計算出來:
- SELECT SUM(price), c1 FROM tb1 GROUP BY c1 ORDER BY c1;

各分庫進行GROUP BY + ORDER BY + sum之后,根據排序后的c1及對應sum結果,歸并一遍后即得到最終結果。
3. 小結
對于復雜語句,可以這樣處理:
- 對于JOIN,可以迭代查詢,或者使用分布式索引
- 對于GROUP BY,需要增加查詢列,以及ORDER BY
13年底的調研筆記,文中的“畫外音”是我當時的批注,希望能讓大家對cobar能有一個初步的認識,有疑問之處,歡迎交流。
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】