我用Python爬了7W知乎用戶信息,終于捕獲了心儀小姐姐.....
雙十一就要來了,在舉國一片“買買買”的呼聲中,單身汪的咆哮聲也愈發凄厲了。
作為一個 Python 程序員,要如何找到小姐姐,避開暴擊傷害,在智中取勝呢?于是就有了以下的對話:

so~今天我們的目標是,爬社區的小姐姐~而且,我們又要用到新的姿勢(霧)了~scrapy 爬蟲框架~
本文主要講 scrapy 框架的原理和使用,建議至少在理解掌握 Python 爬蟲原理后再使用框架(不要問我為什么,我哭給你看)。
scrapy 原理
在寫過幾個爬蟲程序之后,我們就會知道,利用爬蟲獲取數據大概的步驟:
- 請求網頁。
- 獲取網頁。
- 匹配信息。
- 下載數據。
- 數據清洗。
- 存入數據庫。
scrapy 是一個很有名的爬蟲框架,可以很方便的進行網頁信息爬取。那么 scrapy 到底是如何工作的呢?之前在網上看了不少 scrapy 入門的教程,大多數入門教程都配有這張圖。
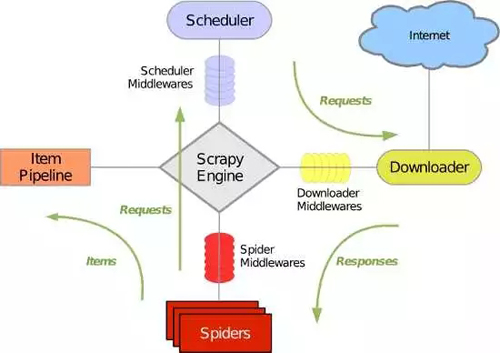
也不知道是這張圖實在太經典了,還是程序員們都懶得畫圖,我第一次看到這個圖的時候,心情是這樣的。

經過了一番深入的理解,大概知道這幅圖的意思,讓我來舉個栗子(是的,我又要舉奇怪的栗子了):
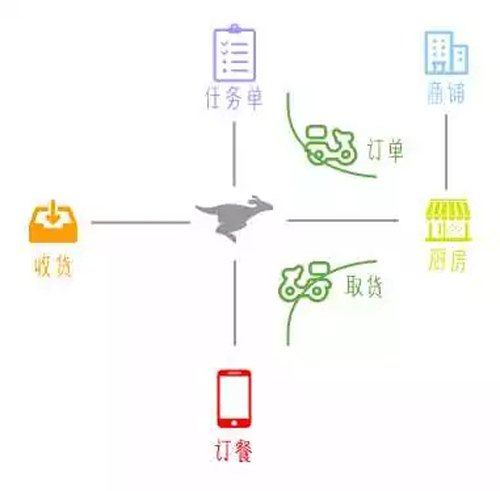
scrapy 原理圖之我要吃好吃的
當我們想吃東西的時候,我們會出門,走到街上,尋找一家想吃的店,然后點餐,服務員再通知廚房去做,最后菜到餐桌上,或者被打包帶走。這就是爬蟲程序在做的事,它要將所有獲取數據需要進行的操作,都寫好。
而 scrapy 就像一個點餐 APP 一般的存在,在訂餐列表(spiders)選取自己目標餐廳里想吃的菜(items),在收貨(pipeline)處寫上自己的收貨地址(存儲方式)。
點餐系統(scrapy engine)會根據訂餐情況要求商鋪(Internet)的廚房(download)將菜做好,由于會產生多個外賣取貨訂單(request),系統會根據派單(schedule)分配外賣小哥從廚房取貨(request)和送貨(response)。說著說著我都餓了。。。。
什么意思呢?在使用 scrapy 時,我們只需要設置 spiders(想要爬取的內容),pipeline(數據的清洗,數據的存儲方式),還有一個 middlewares,是各功能間對接時的一些設置,就可以不用操心其他的過程,一切交給 scrapy模塊來完成。
創建 scrapy 工程
安裝 scrapy 之后,創建一個新項目:
- $ scrapy startproject zhihuxjj
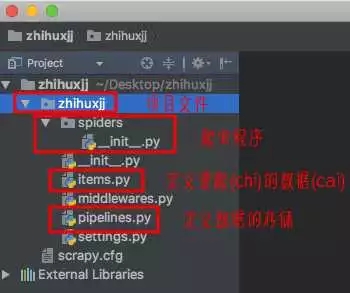
我用的是 pycharm 編譯器,在 spiders 文件下創建 zhihuxjj.py。
在 zhihuxjj.py 這個文件中,我們要編寫我們的爬取規則。
爬取規則制定(spider)
創建好了項目,讓我們來看一下我們要吃的店和菜…哦不,要爬的網站和數據。
我選用了知乎作為爬取平臺,知乎是沒有用戶從 1 到 n 的序列 id 的,每個人可以設置自己的個人主頁 id,且為唯一。
所以采選了一枚種子用戶,爬取他的關注者,也可以關注者和粉絲一起爬,考慮到粉絲中有些三無用戶,我僅選擇了爬取關注者列表,再通過關注者主頁爬取關注者的關注者,如此遞歸。
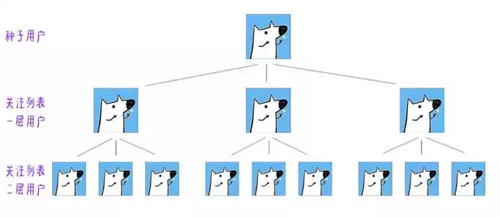
對于程序的設計,是這樣的。
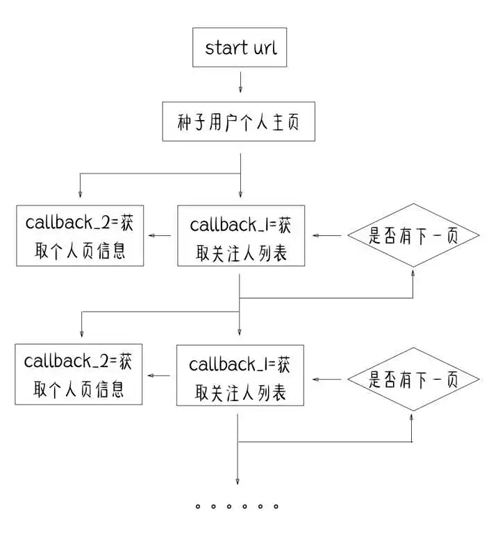
之后就是種子用戶的個人主頁,知乎粉絲多的大 V 很多,但是關注多的人就比較難發現了,這里我選擇了知乎的黃繼新,聯合創始人,想必關注了不少優質用戶(???)?。
分析一下個人主頁可知,個人主頁由'https://www.zhihu.com/people/' + 用戶 id 組成。
我們要獲取的信息是用 callback 回調函數(敲黑板!!劃重點!!)的方式設計,這里一共設計了倆個回調函數:用戶的關注列表和關注者的個人信息。
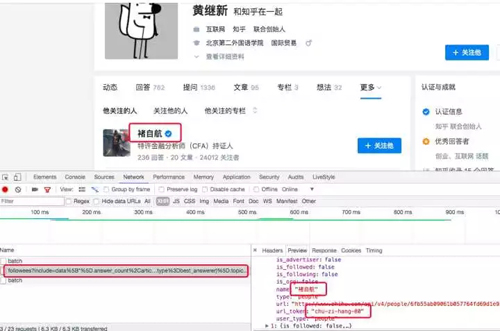
使用 chrome 瀏覽器查看上圖的頁面可知獲取關注列表的 url,以及關注者的用戶 id。
將鼠標放在用戶名上,如下圖:
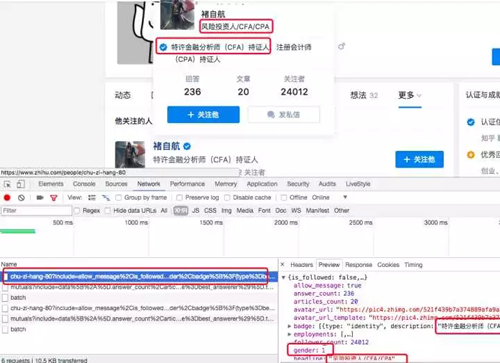
可以獲得個人用戶信息的 url,分析 url 可知:
- 關注者列表鏈接構成:'https://www.zhihu.com/api/v4/members/' + '用戶id' + '/followees?include=data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset=0&limit=20'
- 個人信息鏈接構成:'https://www.zhihu.com/api/v4/members/' + '用戶id' + '?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
so,我們在上一節中創建的 zhihuxjj.py 文件中寫入以下代碼:
- import json
- from zhihuxjj.items import ZhihuxjjItem
- from scrapy import Spider,Request
- class ZhihuxjjSpider(Spider):
- name='zhihuxjj' #scrapy用于區別其他spider的名字,具有唯一性。
- allowed_domains = ["www.zhihu.com"] #爬取范圍
- start_urls = ["https://www.zhihu.com/"]
- start_user = "jixin"
- followees_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include=data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics&offset={offset}&limit=20' #關注列表網址
- user_url = 'https://www.zhihu.com/api/v4/members/{user}?include=locations,employments,gender,educations,business,voteup_count,thanked_Count,follower_count,following_count,cover_url,following_topic_count,following_question_count,following_favlists_count,following_columns_count,avatar_hue,answer_count,articles_count,pins_count,question_count,commercial_question_count,favorite_count,favorited_count,logs_count,marked_answers_count,marked_answers_text,message_thread_token,account_status,is_active,is_force_renamed,is_bind_sina,sina_weibo_url,sina_weibo_name,show_sina_weibo,is_blocking,is_blocked,is_following,is_followed,mutual_followees_count,vote_to_count,vote_from_count,thank_to_count,thank_from_count,thanked_count,description,hosted_live_count,participated_live_count,allow_message,industry_category,org_name,org_homepage,badge[?(type=best_answerer)].topics' #個人信息鏈接
- def start_requests(self):
- yield Request(self.followees_url.format(user=self.start_user,offset=0),callback=self.parse_fo) #回調種子用戶的關注列表
- yield Request(self.user_url.format(user=self.start_user,include = self.user_include),callback=self.parse_user) #回調種子用戶的個人信息
- def parse_user(self, response):
- result = json.loads(response.text)
- print(result)
- item = ZhihuxjjItem()
- item['user_name'] = result['name']
- item['sex'] = result['gender'] # gender為1是男,0是女,-1是未設置
- item['user_sign'] = result['headline']
- item['user_avatar'] = result['avatar_url_template'].format(size='xl')
- item['user_url'] = 'https://www.zhihu.com/people/' + result['url_token']
- if len(result['locations']):
- item['user_add'] = result['locations'][0]['name']
- else:
- item['user_add'] = ''
- yield item
- def parse_fo(self, response):
- results = json.loads(response.text)
- for result in results['data']:
- yield Request(self.user_url.format(user=result['url_token'], include=self.user_include),callback=self.parse_user)
- yield Request(self.followees_url.format(user=result['url_token'], offset=0),callback=self.parse_fo) # 對關注者的關注者進行遍歷,爬取深度depth+=1
- if results['paging']['is_end'] is False: #關注列表頁是否為尾頁
- next_url = results['paging']['next'].replace('http','https')
- yield Request(next_url,callback=self.parse_fo)
- else:
- pass
這里需要劃重點的是 yield 的用法,以及 item['name'],將爬取結果賦值給 item,就是告訴系統,這是我們要選的菜…啊呸…要爬的目標數據。
設置其他信息
在 items.py 文件中,按照 spider 中設置的目標數據 item,添加對應的代碼。
- import scrapy
- class ZhihuxjjItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- user_name = scrapy.Field()
- sex = scrapy.Field()
- user_sign = scrapy.Field()
- user_url = scrapy.Field()
- user_avatar = scrapy.Field()
- user_add = scrapy.Field()
- pass
在 pipeline.py 中添加存入數據庫的代碼:
- import pymysql
- def dbHandle():
- conn = pymysql.connect(
- host='localhost',
- user='root',
- passwd='數據庫密碼',
- charset='utf8',
- use_unicode=False
- )
- return conn
- class ZhihuxjjPipeline(object):
- def process_item(self, item, spider):
- dbObject = dbHandle() # 寫入數據庫
- cursor = dbObject.cursor()
- sql = "insert into xiaojiejie.zhihu(user_name,sex,user_sign,user_avatar,user_url,user_add) values(%s,%s,%s,%s,%s,%s)"
- param = (item['user_name'],item['sex'],item['user_sign'],item['user_avatar'],item['user_url'],item['user_add'])
- try:
- cursor.execute(sql, param)
- dbObject.commit()
- except Exception as e:
- print(e)
- dbObject.rollback()
- return item
因為使用了 pipeline.py,所以我們還需要在 setting.py 文件中,將 ITEM_PIPELINE 注釋解除,這里起到連接兩個文件的作用。
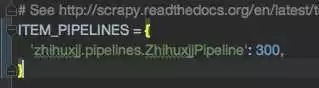
到這里,基本就都設置好了,程序基本上就可以跑了。
不過因為 scrapy 是遵循robots.txt法則的,所以讓我們來觀察一下知乎的法則:https://www.zhihu.com/robots.txt
emmmmmmm,看完法則了嗎,很好,然后我們在setting.py中,將ROBOTSTXT_OBEY 改成 False。

好像…還忘了點什么,對了,忘記設置 headers 了。
通用的設置 headers 的方法同樣是在 setting.py 文件中,將 DEFAULTREQUESTHEADERS 的代碼注釋狀態取消,并設置模擬瀏覽器頭。
知乎是要模擬登錄的,如果使用游客方式登錄,就需要添加 authorization,至于這個 authorization 是如何獲取的,我,就,不,告,訴,你......
- DEFAULT_REQUEST_HEADERS = {
- "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
- 'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
- }
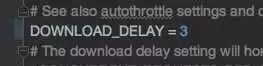
為了減少服務器壓力&防止被封,解除 DOWNLOAD_DELAY 注釋狀態,這時設置下載延遲,將下載延遲設為 3(robots 法則里要求是 10,但 10 實在太慢了_(:зゝ∠)知乎的程序員小哥哥看不見這句話看不見這句話…
寫到這里你會發現,很多我們需要進行的操作,scrapy 都已經寫好了,只需要將注釋去掉,再稍作修改,就可以實現功能了。scrapy 框架還有很多功能,可以閱讀官方文檔了解。
運行scrapy文件
寫好 scrapy 程序后,我們可以在終端輸入。
- $ scrapy crawl zhihuxjj
運行文件,但也可以在文件夾中添加 main.py,并添加以下代碼。
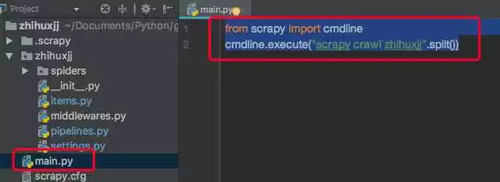
然后直接用 pycharm 運行 main.py 文件即可,然后我們就可以愉快的爬知乎用戶啦~(小姐姐我來啦~)
查找小姐姐
經過了 X 天的運行,_(:зゝ∠)_爬到了 7w 條用戶數據,爬取深度 5。(這爬取速度讓我覺得有必要上分布式爬蟲了…這個改天再嘮)
有了數據我們就可以選擇,同城市的用戶進行研究了……先國際慣例的分析一下數據。
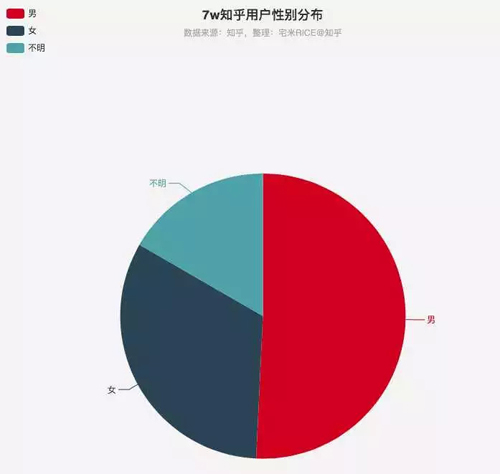
知乎用戶性別分布
在 7w 用戶中,明顯男性超過了半數,標明自己是女性的用戶只占了 30% 左右,還有一部分沒有注明性別,優質的小姐姐還是稀缺資源呀~
再來看看小姐姐們都在哪個城市。(從 7w 用戶中篩選出性別女且地址信息不為空的用戶)
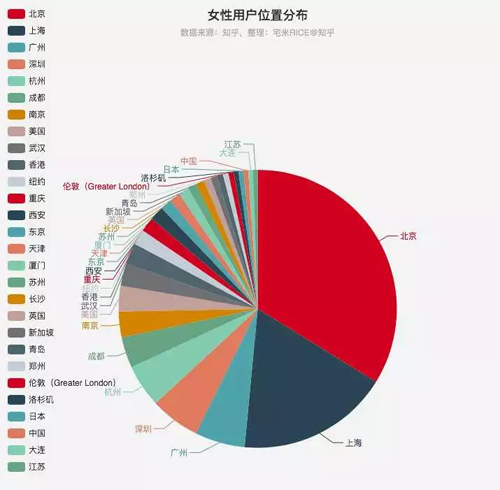
知乎女性用戶位置分布
看來小姐姐們還是集中在北上廣深杭的,所以想發現優質小姐姐的男孩紙們還是要向一線看齊啊,當然也不排除在二三線的小姐姐們沒有標記出自己的地理位置。
emmmmm……這次的分析,就到此為止,你們可以去撩小姐姐們了。
研究小姐姐
意不意外?開不開心?這里還有一章。正所謂,授之以魚,不如授之以漁;撒了心靈雞湯,還得加一只心靈雞腿;找到了小姐姐,我們還要了解小姐姐…………
讓我再舉個栗子~來研究一個小姐姐。(知乎名:動次,已獲取小姐姐授權作為示例。)
知乎用戶:動次
讓我們來爬一下她的動態,chrome 右鍵檢查翻 network 這些套路我就不說了,直接講研究目標。
- 贊同的答案和文章(了解小姐姐的興趣點)
- 發布的答案和文章(了解小姐姐的世界觀、人生觀、價值觀)
- 關注的問題和收藏夾(了解小姐姐需求)
- 提出的問題(了解小姐姐的疑惑)
代碼也不貼了,會放在 GitHub 的,來看一下輸出。

研究動次的結果輸出
因為你乎風格,所以對停用詞進行了一些加工,添加了“如何”、“看待”、“體驗”等詞語,得到了小姐姐回答問題的詞頻。小姐姐的回答里出現了喜歡、朋友、爺爺等詞語。
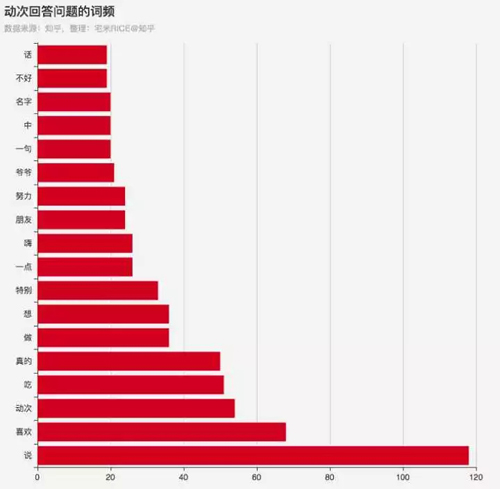
動次回答問題的詞頻
還有!!在關注、贊同和輸出中,都有的詞(?ω?)。(是不是可以靠美味捕獲小姐姐呢……

再來一張劉看山背景的,答題詞云。

動次的回答問題詞云
后記
本文涉及項目會持續更新,會將研究對象拓展至各平臺,并進行后續優化,有興趣的盆友可以關注 GitHub 項目。
結尾引用知乎用戶陳壯壯在《當你追求女生時,你們聊些什么?》的回答。(因為窮我就不申請轉載了你們自己點進去看吧(?﹏?),你們只要知道我有顆帶你們撩妹的心就行了)
安裝scrapy:
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/install.html
pycharm編譯器:
http://www.jianshu.com/p/23e52f7b8ec7
回調函數:
https://www.zhihu.com/question/19801131
yield的用法:
https://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/
robots.txt法則:
scrapy官方文檔:
http://scrapy-chs.readthedocs.io/zh_CN/1.0/index.html
動次:https://www.zhihu.com/people/wang-dong-ci/activities
GitHub項目:
https://github.com/otakurice/danshengoustyle
當你追求女生時,你們聊些什么?
https://www.zhihu.com/question/25955712/answer/37668446