如何基于Spark Streaming構建實時計算平臺
1、前言
隨著互聯網技術的迅速發展,用戶對于數據處理的時效性、準確性與穩定性要求越來越高,如何構建一個穩定易用并提供齊備的監控與預警功能的實時計算平臺也成了很多公司一個很大的挑戰。
自2015年攜程實時計算平臺搭建以來,經過兩年多不斷的技術演進,目前實時集群規模已達上百臺,平臺涵蓋各個SBU與公共部門數百個實時應用,全年JStorm集群穩定性達到100%。目前實時平臺主要基于JStorm與Spark Streaming構建而成,相信關注攜程實時平臺的朋友在去年已經看到一篇關于攜程實時平臺的分享:攜程實時大數據平臺實踐分享。
本次分享將著重于介紹攜程如何基于Spark Streaming構建實時計算平臺,文章將從以下幾個方面分別闡述平臺的構建與應用:
- Spark Streaming vs JStorm
- Spark Streaming設計與封裝
- Spark Streaming在攜程的實踐
- 曾經踩過的坑
- 未來展望
2、Spark Streaming vsJStorm
攜程實時平臺在接入Spark Streaming之前,JStorm已穩定運行有一年半,基本能夠滿足大部分的應用場景。接入Spark Streaming主要有以下幾點考慮:首先攜程使用的JStorm版本為2.1.1版本,此版本的JStorm封裝與抽象程度較低,并沒有提供High Level抽象方法以及對窗口、狀態和Sql等方面的功能支持,這大大的提高了用戶使用JStorm實現實時應用的門檻以及開發復雜實時應用場景的難度。在這幾個方面,SparkStreaming表現就相對好的多,不但提供了高度集成的抽象方法(各種算子),并且用戶還可以與SparkSQL相結合直接使用SQL處理數據。
其次,用戶在處理數據的過程中往往需要維護兩套數據處理邏輯,實時計算使用JStorm,離線計算使用Hive或Spark。為了降低開發和維護成本,實現流式與離線計算引擎的統一,Spark為此提供了良好的支撐。
最后,在引入Spark Streaming之前,我們重點分析了Spark與Flink兩套技術的引入成本。Flink當時的版本為1.2版本,Spark的版本為2.0.1。相比較于Spark,Flink在SQL與MLlib上的支持相對弱于Spark,并且公司許多部門都是基于Spark SQL與MLlib開發離線任務與算法模型,使得大大降低了用戶使用Spark的學習成本。
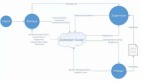
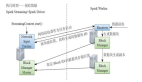
下圖簡單的給出了當前我們使用Spark Streaming與JStorm的對比:

3、Spark Streaming設計與封裝
在接入Spark Streaming的初期,首先需要考慮的是如何基于現有的實時平臺無縫的嵌入SparkStreaming。原先的實時平臺已經包含了許多功能:元數據管理、監控與告警等功能,所以第一步我們先針對SparkStreaming進行了封裝并提供了豐富的功能。整套體系總共包含了Muise Spark Core、Muise Portal以及外部系統。
3.1 Muise Spark Core
MuiseSpark Core是我們基于Spark Streaming實現的二次封裝,用于支持攜程多種消息隊列,其中HermesKafka與源生的Kafka基于Direct Approach的方式消費數據,Hermes Mysql與Qmq基于Receiver的方式消費數據。接下來將要講的諸多特性主要是針對Kafka類型的數據源。
Muisespark core主要包含了以下特性:
- Kafka Offset自動管理
- 支持Exactly Once與At Least Once語義
- 提供Metric注冊系統,用戶可注冊自定義metric
- 基于系統與用戶自定義metric進行預警
- Long running on Yarn,提供容錯機制
3.1.1 Kafka Offset自動管理
封裝muise spark core的第一目標就是簡單易用,讓用戶以最簡單的方式能夠上手使用SparkStreaming。首先我們實現了幫助用戶自動讀取與存儲Kafka Offset的功能,用戶無需關心Offset是如何被處理的。其次我們也對Kafka Offset的有效性進行了校驗,有的用戶的作業可能在停止了較長時間后重新運行會出現Offset失效的情形,我們也對此作了對應的操作,目前的操作是將失效的Offset設置為當前有效的最老的Offset。下圖展現了用戶基于muise spark core編寫一個Spark streaming作業的簡單示例,用戶只需要短短幾行代碼即可完成代碼的初始化并創建好對應的DStream:

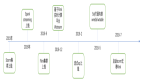
默認情況下,作業每次都是基于上次存儲的Kafka Offset繼續消費,但是用戶也可以自行決定Offset的消費起點。下圖中展示了設置消費起點的三種方式:

3.1.2 Exactly Once的實現
如果實時作業要實現端對端的exactly once則需要數據源、數據處理與數據存儲的三個階段都保證exactly once的語義。目前基于Kafka Direct API加上Spark RDD算子精確一次的保證能夠實現端對端的exactly once的語義。在數據存儲階段一般實現exactly once需要保證存儲的過程是冪等操作或事務操作。很多系統本身就支持了冪等操作,比如相同數據寫hdfs同一個文件,這本身就是冪等操作,保證了多次操作最終獲取的值還是相同;HBase、ElasticSearch與redis等都能夠實現冪等操作。對于關系型數據庫的操作一般都是能夠支持事務性操作。
官方在創建DirectKafkaInputStream時只需要輸入消費Kafka的From Offset,然后其自行獲取本次消費的End Offset,也就是當前最新的Offset。保存的Offset是本批次的End Offset,下次消費從上次的End Offset開始消費。當程序宕機或重啟任務后,這其中存在一些問題。如果在數據處理完成前存儲Offset,則可能存在作業處理數據失敗與作業宕機等情況,重啟后會無法追溯上次處理的數據導致數據出現丟失。如果在數據處理完成后存儲Offset,但是存儲Offset過程中發生失敗或作業宕機等情況,則在重啟后會重復消費上次已經消費過的數據。而且此時又無法保證重啟后消費的數據與宕機前的數據量相同數據相當,這又會引入另外一個問題,如果是基于聚合統計指標作更新操作,這會帶來無法判斷上次數據是否已經更新成功。
所以在muise spark core中我們加入了自己的實現用以保證Exactly once的語義。具體的實現是我們對Spark源碼進行了改造,保證在創建DirectKafkaInputStream可以同時輸入From Offset與End Offset,并且我們在存儲Kafka Offset的時候保存了每個批次的起始Offset與結束Offset,具體格式如下:

如此做的用意在于能夠確保無論是宕機還是人為重啟,重啟后的第一個批次與重啟前的最后一個批次數據一模一樣。這樣的設計使得后面用戶在后面對于第一個批次的數據處理非常靈活可變,如果用戶直接忽略第一個批次的數據,那此時保證的是at most once的語義,因為我們無法獲知重啟前的最后一個批次數據操作是否有成功完成;如果用戶依照原有邏輯處理第一個批次的數據,不對其做去重操作,那此時保證的是at least once的語義,最終結果中可能存在重復數據;最后如果用戶想要實現exactlyonce,muise spark core提供了根據topic、partition與offset生成UID的功能,只要確保兩個批次消費的Offset相同,則最終生成的UID也相同,用戶可以根據此UID作為判斷上個批次數據是否有存儲成功的依據。下面簡單的給出了重啟后第一個批次操作的行為。

3.1.3 Metrics系統
Musiespark core基于Spark本身的metrics系統進行了改造,添加了許多定制的metrics,并且向用戶暴露了metrics注冊接口,用戶可以非常方便的注冊自己的metrics并在程序中更新metrics的數值。最后所有的metrics會根據作業設定的批次間隔寫入Graphite,基于公司定制的預警系統進行報警,前端可以通過Grafana展現各項metrics指標。
Muisespark core本身定制的metrics包含以下三種:
- Fail,批次時間內spark task失敗次數超過4次便報警,用于監控程序的運行狀態
- Ack,批次時間內spark streaming處理的數據量小0便報警,用于監控程序是否在正常消費數據
- Lag,批次時間內數據消費延遲大于設定值便報警
其中由于我們大部分作業開啟了Back Pressure功能,這就導致在Spark UI中看到每個批次數據都能在正常時間內消費完成,然而可能此時kafka中已經積壓了大量數據,故每個批次我們都會計算當前消費時間與數據本身時間的一個平均差值,如果這個差值大于批次時間,說明本身數據消費就已經存在了延遲。
下圖展現了預警系統中,基于用戶自定義注冊的Metrics以及系統定制的Metrics進行預警。

3.1.4 容錯
其實在上面Exactly Once一章中已經詳細的描述了muise spark core如何在程序宕機后能夠保證數據正確的處理。但是為了能夠讓Spark Sreaming能夠長時間穩定的運行在Yarn集群上,還需要添加許多配置,感興趣的朋友可以查看:Long running Spark Streaming Jobs on YarnCluster。
除了上述容錯保證之外,Muise Portal(后面會講)也提供了對Spark Streaming作業定時檢測的功能。目前每過5分鐘對當前所有數據庫中狀態標記為Running的Spark Streaming作業進行狀態檢測,通過Yarn提供的REST APIs可以根據每個作業的Application Id查詢作業在Yarn上的狀態,如果狀態處于非運行狀態,則會嘗試重啟作業。
3.2 Muise Portal
在封裝完所有的Spark Streaming之后,我們就需要有一個平臺能夠管理配置作業,MuisePortal就是這樣的存在。Muise Portal目前主要支持了Storm與Spark Streaming兩類作業,支持新建作業、Jar包發布、作業運行與停止等一系列功能。下圖展現了新建作業的界面:

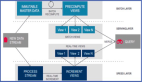
SparkStreaming作業基于Yarn Cluster模式運行,所有作業通過在Muise Portal上的Spark客戶端提交到Yarn集群上運行。具體的一個作業運行流程如下圖所示:

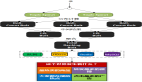
3.3 整體架構
最后這邊給出一下目前攜程實時平臺的整體架構。

4、Spark Streaming在攜程的實踐
目前Spark Streaming在攜程的業務場景主要可以分為以下幾塊:ETL、實時報表統計、個性化推薦類的營銷場景以及風控與安全的應用。從抽象上來說,主要可以分為數據過濾抽取、數據指標統計與模型算法的使用。
4.1 ETL
如今市面上有形形色色的工具可以從Kafka實時消費數據并進行過濾清洗最終落地到對應的存儲系統,如:Camus、Flume等。相比較于此類產品,Spark Streaming的優勢首先在于可以支持更為復雜的處理邏輯,其次基于Yarn系統的資源調度使得Spark Streaming的資源配置更加靈活,最后用戶可以將Spark RDD數據轉換成Spark Dataframe數據,使得可以與Spark SQL相結合,并且最終將數據輸出到HDFS和Alluxio等分布式文件系統時可以存儲為Parquet之類的格式化數據,用戶在后續使用Spark SQL處理數據時更為的簡便。
目前在ETL使用場景中較為典型的是攜程度假部門的Data Lake應用,度假部門使用Spark Streaming對數據做ETL操作最終將數據存儲至Alluxio,期間基于muise-spark-core的自定義metric功能對數據的數據量、字段數、數據格式與重復數據進行了數據質量校驗與監控,具體的監控預警已在上面說過。

4.2 實時報表統計
實時報表統計與展現也是Spark Streaming使用較多的一個場景,數據可以基于Process Time統計,也可以基于Event Time統計。由于本身Spark Streaming不同批次的job可以視為一個個的滾動窗口,某個獨立的窗口中包含了多個時間段的數據,這使得使用SparkStreaming基于Event Time統計時存在一定的限制。一般較為常用的方式是統計每個批次中不同時間維度的累積值并導入到外部系統,如ES;然后在報表展現的時基于時間做二次聚合獲得完整的累加值最終求得聚合值。下圖展示了攜程IBU基于Spark Streaming實現的實時看板。

4.3 個性化推薦與風控安全
這兩類應用的共同點莫過于它們都需要基于算法模型對用戶的行為作出相對應的預測或分類,攜程目前所有模型都是基于離線數據每天定時離線訓練。在引入Spark Streaming之后,許多部門開始積極的嘗試特征的實時提取、模型的在線訓練。并且Spark Streaming可以很好的與Spark MLlib相結合,其中最為成功的案例為信安部門以前是基于各類過濾條件抓取攻擊請求,后來他們采用離線模型訓練,Spark Streaming加Spark MLlib對用戶進行實時預測,性能上較JStorm(基于大量正則表達式匹配用戶,十分消耗CPU)提高了十倍,漏報率降低了20%。
5、曾經踩過的坑
目前攜程的Spark Streaming作業運行的YARN集群與離線作業同屬一個集群,這對作業無論是性能還是穩定性都帶來了諸多影響。尤其是當YARN或者Hadoop集群需要更新維護重啟服務時,在很大程度上會導致Spark Streaming作業出現報錯、掛掉等狀況,雖然有諸多的容錯保障,但也會導致數據積壓數據處理延遲。后期將會獨立部署Hadoop與Yarn集群,所有的實時作業都運行在獨立的集群上,不受外部的影響,這也方便后期對于Flink作業的開發與維護。后期通過Alluxio實現主集群與子集群間的數據共享。
在使用過程中,也遇到了形形色色不同的Bug,這邊簡單的介紹幾個較為嚴重的問題。首先第一個問題是,Spark Streaming每個批次Job都會通過DirectKafkaInputStream的comput方法獲取消費的Kafka Topic當前最新的offset,如果此時kafka集群由于某些原因不穩定,就會導致java.lang.RuntimeException: No leader found for partition xx的問題,由于此段代碼運行在Driver端,如果沒有做任何配置和處理的情況下,會導致程序直接掛掉。對應的解決方法是配置spark.streaming.kafka.maxRetries大于1,并且可以通過配置refresh.leader.backoff.ms參數設置每次重試的間隔時間。
其次在使用Spark Streaming與Spark Sql相結合的過程中,也會有諸多問題。比如在使用過程中可能出現out of memory:PermGen space,這是由于Spark sql使用code generator導致大量使用PermGen space,通過在spark.driver.extraJavaOptions中添加-XX:MaxPermSize=1024m-XX:PermSize=512m解決。還有Spark Sql需要創建Spark Warehouse,如果基于Yarn來運行,默認可能是在HDFS上創建相對應的目錄,如果沒有權限會報出Permission denied的問題,用戶可以通過配置config(“spark.sql.warehouse.dir”,”file:${system:user.dir}/spark-warehouse”)來解決。
6、未來展望
上面主要針對Spark Streaming在攜程實時平臺中的運用做了詳細的介紹,在使用SparkStreaming過程中還是存在一些痛點,比如窗口功能比較單一、基于Event Time統計指標過于繁瑣以及官方在新的版本中基本沒有新的特性加入等,這使得我們更加傾向于嘗試Flink。Flink基本實現了Google提出的各類實時處理的理念,引入了WaterMark的實現,感興趣的朋友可以查看Google官方文檔:The world beyond batch: Streaming 102。
目前Flink 1.4 release版本發布在即,Spark 2.2.0基于kafka數據源的Structured Streaming也支持了更多的特性。前期我們已對Flink做了充分的調研,下半年主要工作將放在Flink的對接上。在提供了諸多實時計算框架的支持后,隨之而來的是帶來了更多的學習成本,今后我們的重心將放在如何使用戶更加容易的實現實時計算邏輯。其中Apache Beam對各種實時場景提供了良好的封裝并對多種實時計算引擎做了支持,其次基于Stream Sql實現復雜的實時應用場景都將是我們主要調研的方向。