機器學習K-means算法在Python中的實現
作者:佚名
K-means是機器學習中一個比較常用的算法,屬于無監督學習算法,其常被用于數據的聚類,只需為它指定簇的數量即可自動將數據聚合到多類中,相同簇中的數據相似度較高,不同簇中數據相似度較低。
K-means算法簡介
K-means是機器學習中一個比較常用的算法,屬于無監督學習算法,其常被用于數據的聚類,只需為它指定簇的數量即可自動將數據聚合到多類中,相同簇中的數據相似度較高,不同簇中數據相似度較低。
K-menas的優缺點:
優點:
- 原理簡單
- 速度快
- 對大數據集有比較好的伸縮性
缺點:
- 需要指定聚類 數量K
- 對異常值敏感
- 對初始值敏感
K-means的聚類過程
其聚類過程類似于梯度下降算法,建立代價函數并通過迭代使得代價函數值越來越小
- 適當選擇c個類的初始中心;
- 在第k次迭代中,對任意一個樣本,求其到c個中心的距離,將該樣本歸到距離最短的中心所在的類;
- 利用均值等方法更新該類的中心值;
- 對于所有的c個聚類中心,如果利用(2)(3)的迭代法更新后,值保持不變,則迭代結束,否則繼續迭代。
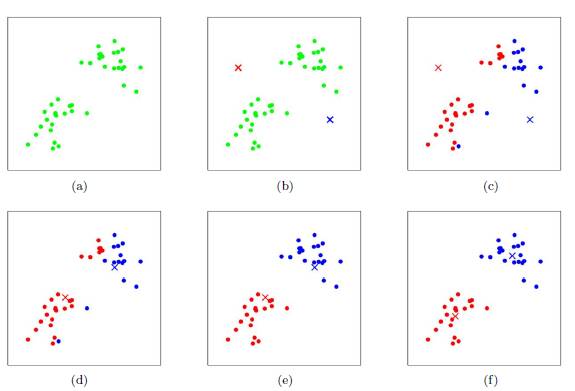
該算法的***優勢在于簡潔和快速。算法的關鍵在于初始中心的選擇和距離公式。
K-means 實例展示
python中km的一些參數:
- sklearn.cluster.KMeans(
- n_clusters=8,
- init='k-means++',
- n_init=10,
- max_iter=300,
- tol=0.0001,
- precompute_distances='auto',
- verbose=0,
- random_state=None,
- copy_x=True,
- n_jobs=1,
- algorithm='auto'
- )
- n_clusters: 簇的個數,即你想聚成幾類
- init: 初始簇中心的獲取方法
- n_init: 獲取初始簇中心的更迭次數,為了彌補初始質心的影響,算法默認會初始10個質心,實現算法,然后返回***的結果。
- max_iter: ***迭代次數(因為kmeans算法的實現需要迭代)
- tol: 容忍度,即kmeans運行準則收斂的條件
- precompute_distances:是否需要提前計算距離,這個參數會在空間和時間之間做權衡,如果是True 會把整個距離矩陣都放到內存中,auto 會默認在數據樣本大于featurs*samples 的數量大于12e6 的時候False,False 時核心實現的方法是利用Cpython 來實現的
- verbose: 冗長模式(不太懂是啥意思,反正一般不去改默認值)
- random_state: 隨機生成簇中心的狀態條件。
- copy_x: 對是否修改數據的一個標記,如果True,即復制了就不會修改數據。bool 在scikit-learn 很多接口中都會有這個參數的,就是是否對輸入數據繼續copy 操作,以便不修改用戶的輸入數據。這個要理解Python 的內存機制才會比較清楚。
- n_jobs: 并行設置
- algorithm: kmeans的實現算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式實現
雖然有很多參數,但是都已經給出了默認值。所以我們一般不需要去傳入這些參數,參數的。可以根據實際需要來調用。
下面展示一個代碼例子
- from sklearn.cluster import KMeans
- from sklearn.externals import joblib
- from sklearn import cluster
- import numpy as np
- # 生成10*3的矩陣
- data = np.random.rand(10,3)
- print data
- # 聚類為4類
- estimator=KMeans(n_clusters=4)
- # fit_predict表示擬合+預測,也可以分開寫
- res=estimator.fit_predict(data)
- # 預測類別標簽結果
- lable_pred=estimator.labels_
- # 各個類別的聚類中心值
- centroids=estimator.cluster_centers_
- # 聚類中心均值向量的總和
- inertia=estimator.inertia_
- print lable_pred
- print centroids
- print inertia
- 代碼執行結果
- [0 2 1 0 2 2 0 3 2 0]
- [[ 0.3028348 0.25183096 0.62493622]
- [ 0.88481287 0.70891813 0.79463764]
- [ 0.66821961 0.54817207 0.30197415]
- [ 0.11629904 0.85684903 0.7088385 ]]
- 0.570794546829
為了更直觀的描述,這次在圖上做一個展示,由于圖像上繪制二維比較直觀,所以數據調整到了二維,選取100個點繪制,聚類類別為3類
- from sklearn.cluster import KMeans
- from sklearn.externals import joblib
- from sklearn import cluster
- import numpy as np
- import matplotlib.pyplot as plt
- data = np.random.rand(100,2)
- estimator=KMeans(n_clusters=3)
- res=estimator.fit_predict(data)
- lable_pred=estimator.labels_
- centroids=estimator.cluster_centers_
- inertia=estimator.inertia_
- #print res
- print lable_pred
- print centroids
- print inertia
- for i in range(len(data)):
- if int(lable_pred[i])==0:
- plt.scatter(data[i][0],data[i][1],color='red')
- if int(lable_pred[i])==1:
- plt.scatter(data[i][0],data[i][1],color='black')
- if int(lable_pred[i])==2:
- plt.scatter(data[i][0],data[i][1],color='blue')
- plt.show()
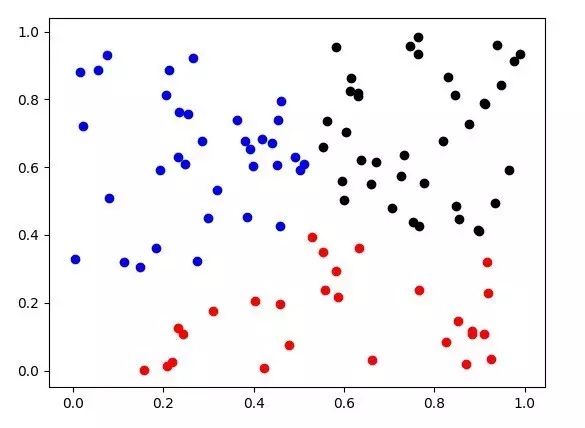
可以看到聚類效果還是不錯的,對k-means的聚類效率進行了一個測試,將維度擴寬到50維
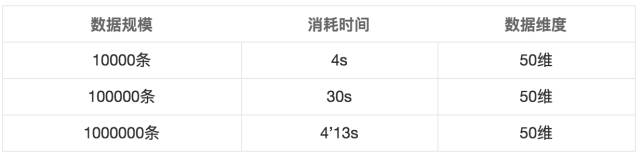
對于***的數據,擬合時間還是能夠接受的,可見效率還是不錯,對模型的保存與其它的機器學習算法模型保存類似
- from sklearn.externals import joblib
- joblib.dump(km,"model/km_model.m")
責任編輯:龐桂玉
來源:
Python開發者