Raft 算法原理及其在 CMQ 中的應用(下)
三 Raft在CMQ中的應用
早期我們在rabbitmq的基礎上搭建了一套可擴展消息中間件CRMQ1.0,由于rabbitmq的GM同步算法在性能等方面存在瓶頸,所以自研了基于raft算法的內部版本CRMQ2.0和騰訊云CMQ,在保證強一致高可靠的前提下,性能和可用性都有顯著提升。實現上采用了生產Confirm + 消費Ack機制保證消息不丟失,Confirm和Ack機制均通過raft來保證。生產的消息通過Raft轉為Entry同步到大多數節點并提交,完成后各節點狀態機應用該Entry,將消息內容寫入磁盤,之后由Leader節點回復客戶端Confirm,表示消息生產成功。消費時客戶端從Leader節點拉取消息,消費完成后通過Ack命令通知服務端消息已消費可刪除,Ack請求經Raft同步后,各節點應用該請求,之后消息被刪除不會再投遞。下面介紹詳細過程:
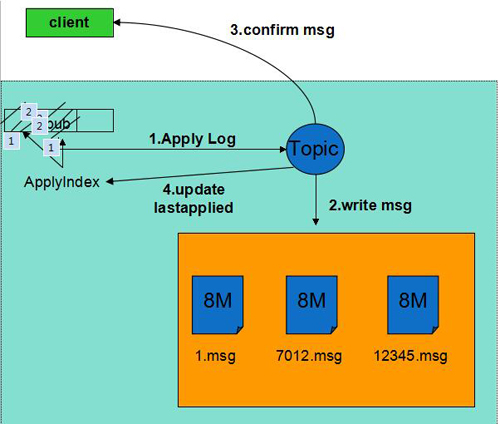
生產流程:
1)生產者將生產消息的請求發往Leader的Raft模塊。
2)Raft模塊完成Entry的創建和同步。
3)大多數節點上持久化并返回成功后Entry標記為Committed。
4)所有節點的State Machine應用該日志,取出實際的生產請求,將消息內容寫入磁盤,更新ApplyIndex。該步驟不需要刷盤。
5)Leader回復客戶端Confirm,通知生產成功。
6)如果此后機器重啟,通過raft日志恢復生產消息,保證了已Confirm的消息不丟失。
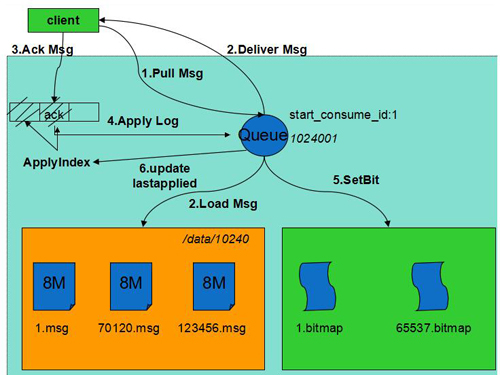
消費流程:
1)消費者從Leader節點拉取消息。
2)Leader收到后從磁盤加載未刪除的消息投遞給客戶端。
3)客戶端處理完成后Ack消息,通知服務器刪除消息。
4)Ack請求經Raft同步后標記為Committed。
5)各節點狀態機應用該日志,將消息對應的bit置位,將其設置為已刪除并更新ApplyIndex。
6)通知客戶端刪除成功。
7)如果機器重啟,通過Raft日志恢復Ack請求,保證了已刪除的消息不會再投遞。
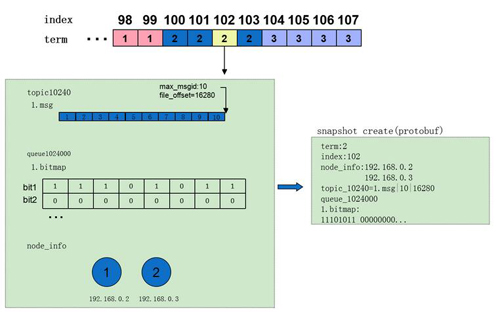
快照管理:
快照管理與業務緊密相關,不同系統快照制作的成本差異很大,CMQ中快照的內容十分輕量,一次快照的耗時在毫秒級,平均5min創建一次,各節點獨立完成。實現上內存中維護了一份動態的快照,制作快照時首先拷貝出動態快照的副本,之后處理流繼續更新動態快照,用拷貝出的副本創建快照文件,不影響實際的處理流。快照具體內容包括:
1)term:快照對應Entry的term (參照算法)
2)index:快照對應Entry的 index (參照算法)
3)node_info:Entry時的集群配置信息。
4)topic info:每個隊列一項。CMQ中同一隊列生產的消息順序寫入,分片存儲,因此只需記錄***一個分片的狀態(分片文件名,文件偏移量)。
5)queue info:每個隊列一項。CMQ中采用bitmap記錄消息的刪除情況,在內存中維護,在制作快照時dump到快照文件。
可靠性:業界統一的衡量標準為RPO(Recovery Point Objective),反映故障時數據恢復完整性的指標。由于只有提交的日志才會被應用到狀態機,且raft日志在寫入時會強制刷盤,所以故障重啟后通過快照+raft日志即可恢復,不會丟失數據,RPO=0。不過,如2.7節所述,Leader故障時可能會產生重復數據,需要通過冪等性保證或去重機制來解決該問題。
可用性:業界統一的衡量標準為RTO(Recovery Time Objective),反映故障時業務恢復及時性的指標。follower故障對系統沒有影響(RTO=0),leader故障時其他節點通過自發選出新leader,而且CMQ中前端具備自動重連功能,當連接斷開后會自動尋找新leader,系統不可用時間大大降低。目前CMQ中配置的選舉超時時間為2s~4s,在不考慮選舉沖突的前提下,RTO上限為4s。
在CMQ中,Leader通過與Follower的心跳判斷自己是否已網絡分區,當檢測到分區時(大多數節點上次心跳回復時間距現在超過2s),主動斷開前端連接,前端發現后會自動尋找新Leader。這段時間內客戶端請求會超時,在連上新Leader后,客戶端重試之前超時的任務,后續請求恢復正常。
四 Raft算法性能優化
Raft算法的性能瓶頸主要有兩方面:
1) 每次日志寫入后都需要刷盤才能返回成功,而刷盤是一個比較耗時的操作。
2) 由于算法限制,所有的請求都由Leader處理,不能做到所有節點皆可提供服務。
針對以上兩個問題,我們做了以下優化:
1)Batch Processing:在請求量較大時,并不是每一條日志寫入都刷盤,還是累積一定量的日志后集中刷盤,從而減少刷盤次數。對應的,在同步到Follower時也采用批量同步的方式,Follower接收后將日志批量寫盤。
2)Multi-Raft: 進程中同時運行多個raft實例,機器之間組建多raft 組,客戶端請求路由到不同的group上,從而實現多主讀寫,提高并發性能。通過將leader分布在不同機器上,提高了系統的整體利用率。
3)Async-rpc: 在日志同步過程中采用同步rpc方式,在一端處理時另一端只能等待,性能較差。我們采用異步的方式使得leader端發送和Follower端處理并發進行。發送過程中leader端維持一個發送窗口,當待確認的rpc數達到上限停止發送,窗口值上限:

在與同屬于高可靠(多副本同步刷盤)的Rabbitmq性能對比中,相同壓測場景下CMQ速度可以達到RabbitMQ的四倍左右。
以下為TS60機器1KB消息大小時性能數據:
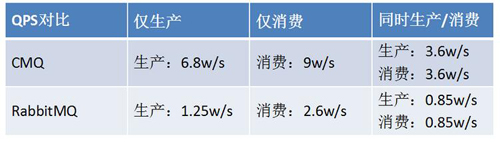
測試中CMQ采用單Raft組方式以保證測試公平性。監控顯示CPU、內存和網卡均未達到瓶頸,系統瓶頸在磁盤IO,iostat顯示w_await遠大于svctm。主要原因在于刷盤耗時,造成寫操作排隊等待。
實際生產環境CMQ中我們將raft組和磁盤進行綁定,實現raft組之間磁盤的隔離,一方面保證了磁盤的順序讀寫,另一方面充分利用機器的cpu 、內存、網卡等資源。
五 通用Raft庫
CMQ中完整實現了Raft算法并解決了很多細節難點。考慮到分布式系統設計的復雜性,如果開發者只專注于業務相關部分,將可以顯著降低開發難度,提高系統的質量,所以我們將CMQ中的raft部分以庫的方式獨立出來,使用者用它即可搭建一套強一致高可用分布式系統。目前該庫已經完成基線版本開發并在部門落地使用,驗證完成后會陸續開放給更多業務使用。
六 總結
消息中間件通常分為高可靠版本和高性能版本兩種。CMQ是一款金融級的高可靠分布式消息中間件,通過raft保證了消息的可靠不丟失。同時在性能和可用性方面相比競品都有顯著提高。此外,我們自研的高性能版本的消息中間件ckafka也已在騰訊云上線,***兼容kafka0.09~0.10版本客戶端,關于CKafka的具體技術介紹請關注后續技術文章。
Raft算法強調了Leader的地位,選舉和日志同步都是圍繞Leader展開。由Leader負責處理所有請求保證了系統的強一致性;Leader選舉和日志同步算法保證了數據的可靠不丟失;此外上述步驟只需要大多數正常互聯即可,從而極大提高了系統的可用性,少量機器故障不受影響。不過,所有請求由Leader處理并沒有充分利用從節點的資源,目前google的Spanner已支持從從節點讀取,后續我們也會在這方面作更進一步的研究。Raft算法易于理解和工程化,相信未來會應用在越來越多的分布式系統中。
原文鏈接:https://cloud.tencent.com/community/article/937437
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】