基于OpenGL ES 的深度學習框架編寫
背景與工程定位
背景
項目組基于深度學習實現了視頻風格化和人像摳圖的功能,但這是在PC/服務端上跑的,現在需要移植到移動端,因此需要一個移動端的深度學習的計算框架。
同類型的庫
caffe-Android-lib 目前應該是最便于集成使用的深度學習框架庫。
tensorflow和mxnet據說也有對應的android庫,因時間原因暫未測試。
CNNdroid,網址https://zhuanlan.zhihu.com/p/25259452,這個是用
renderscript 作優化的深度學習框架,不過就代碼實現和實際測試結果來看,性能一般。
工程定位
實現可實時、體積小、通用的深度學習預測框架。
可實時
跟PC或服務器不同,移動設備上的GPU可不一定有CPU強悍(多線程+neon/vfp),但在需要實時計算的場景(主要是相機預覽和視頻播放),往往都是基于OpenGL渲染環境的。
實時的情況下,深度學習框架的輸入和輸出都在GPU端,使用CPU進行計算往往需要拷貝圖像出來,算好后再傳到GPU端,因此基于GPU實現的深度學習的庫能持平CPU版本的效率就有足夠優勢了。

對每一幀相機預覽產生的數據,系統將其映射為opengl 的一個external texture,然后需要 計算出一個 mask texture,與原先的texture作混合,顯示出來。如果mask texture 的計算在cpu上進行,則需要每幀先把 graphicbuffer 的數據拷貝出來,計算出mask后上傳到 mask texture 去,產生一來一回兩次額外拷貝。
通用
本工程需要支持 caffe 產出的模型文件,支持常見的網絡如lenet、ResNet等等。這個工作量包括編寫相應層的算子,設計網絡結構,解析caffe模型的參數等。
所幸的是,目前在移動端做好深度學習的預測就足夠了,相比于兼顧訓練的結構至少省去2/3的工作量。
工程實現
方案選型
GPU加速的API

使用GPU加速有如下一些方案:
CUDA、OpenCL、OpenGL(ES)、RenderScript、Metal
CUDA只適用到NVIDIA的GPU,Metal只適用于apple系列,這兩個對android設備而言基本不用考慮。
對于OpenCL,雖然有不少移動GPU已經支持,比如 Arm 的 mali 系列(T628之后),且有相應的支持庫。但是,一方面由于Android在系統層面上沒有支持,沒有相應的系統API,兼容性還是比較差,另一方面,OpenCL 操作完成后的內存傳到OpenGL還是需要同步一下,會影響效率。
RenderScript 這個坑比較多,文檔極少,而且會有跟OpenCL一樣的需要跟OpenGL同步的問題,不做考慮。
***就只剩下 OpenGL ES,為了開發方便,用 Computer shader 實現,盡管會有一定的兼容性犧牲(Android 5.1 及以上,GPU支持openGLES 3.1),但考慮到下面兩點是值得的:
1、走渲染管線去實現通用計算,編程復雜且容易出錯,調優也很麻煩。有 computer shader之后,編程就跟opencl、metal類似,這些工作量可以大幅降低,大大加快開發。
2、支持OpenGLES 3.1版本的GPU一般都是相對較新的,性能不會太差,能夠實現加速的目的。
運算的分配
CNNdroid中僅用GPU加速卷積層的運算,其他還是由CPU+多線程執行。以前我們在早期作gpu加速的預研時,也有過類似的嘗試,但是數據傳輸和同步的性能消耗遠大于協同計算帶來的性能提升。因此這個工程中,網絡中的計算全部由GPU完成,避免數據在CPU和GPU之間反復傳輸或同步。
另外,GPU驅動在申請內存(分配紋理所需要內存空間)的時間消耗在移動設備端是不可忽略的,因此,不能在運算過程中臨時創建紋理或其他Buffer,必須事先分配好。
優化注意點
1、向量化運算
預測時,我們輸入神經網絡的數據可表示為
對于卷積層和內積層,我們把參數存儲為mat4的數組,然后其計算就完全是vec4級的向量化運算。
2、合適的localsize設計
與OpenCL不一樣,computer shader 必須手動指定 workgroup 的大小,并且指定運行的 workgroup 數量。這兩組維度,都是越大越好。
local size 一般而言越大越好,但 computer shader 所需要的寄存器越多,local size 的***值就越小,考慮到最耗時的卷積shader所能使用的local size 一般也就 64,保守起見都定為64(8乘8)。
不能對齊的情況在shader中處理,比如下面的代碼:
void main()
{
ivec3 pos = ivec3(gl_GlobalInvocationID);
if (pos.x < MAX_WIDTH && pos.y < MAX_HEIGHT)
{
/*Do something*/
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3、適當地合并/去除layer
如正則層可以直接和上一層合并(末尾加個max處理就行),dropout層可以直接丟棄。
合并可以提升性能(不過不會太多),但最重要的是減少了中間內存。
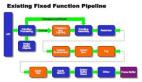
框架設計
分為兩個子模塊,引擎模塊在客戶端上運行,工具模塊用來轉換caffe的模型文件。

引擎模塊
1、數據層
Image 為一個RGBA32F格式的2D Array紋理,SSBO為一種vbo,
全稱為GL_SHADER_STORAGE_BUFFER,用于存儲自定義類型的數據(主要就是卷積層和內積層的參數)。
Program 為 著色器鏈接而成的 opengl program,NetInfo 由 proto 定義,用于規定網絡結構。
在 shader 中,image 和 SSBO 示例如下:
layout(rgba32f, binding = 0) writeonly uniform highp image2DArray uOutput;//Image
layout(rgba32f, binding = 1) readonly uniform highp image2DArray uInput;//Image
layout(binding = 2) readonly buffer kernel {
mat4 values[];
} uKernel;//SSBO- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
2、算子層
包括各類layer的實現,如卷積,正則,內積(全連接),Softmax等。
每一個layer要負責申請自己的輸出內存(image)。
3、結構層
根據 NetInfo 的信息,創建各類算子并構成DAG(有向無環圖),執行運算并輸出結果。

工具模塊
包括一個結構轉換器、參數初始化和拷貝工具。拷貝工具是比較容易出錯的,因為卷積層和內積層的參數需要補零對齊及重排。
性能與效果
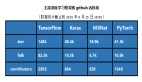
跟開源的 caffe-android-lib 對比
https://github.com/sh1r0/caffe-android-lib
庫大小
caffe-android-lib 11M
DeeplearningOGL 440K
全自主開發的,毫無疑問要小很多很多。
運行效率
Oppo R9 (MT6755, GPU: Mali-T860)上的測試結果:
連續運行十次,去除***次的結果(移動設備上一般都是動態調頻的,***次跑的時候CPU/GPU的頻率還沒調起來,會比較慢)。
Lenet 網絡:
caffe-android-lib:5.0~5.2ms(線程設為4)
DeeplearningOGL:3.6-3.8 ms
較CPU版本(包含了neon與多線程優化)提升了 50%左右的效率,已經大大超出預期了,在GPU更好的機器上(如mate8上)表現會更佳。
相比于 CNNdroid 更是好很多了。
人像摳圖的場景很流暢,且不需要隔幀計算。