糾刪碼存儲系統中的投機性部分寫技術
前言
多副本和糾刪碼(EC,Erasure Code)是存儲系統中常見的兩種數據可靠性方法。與多副本冗余不同,EC將m個原始數據塊編碼生成k個檢驗塊,形成一個EC組,之后系統可最多容忍任意k個原始數據塊或校驗塊損壞,都不會產生數據丟失。糾刪碼可將數據存儲的冗余度降低50%以上,大大降低了存儲成本,在許多大規模分布式存儲系統中已得到實際應用。
EC給寫操作帶來了很大的額外開銷,包括編解碼計算開銷和流程性開銷兩部分。在向量指令集SSE、AVX等的幫助下,一個現代CPU核心的EC編解碼能力就可以達到幾GB到十幾GB每秒,遠遠大于存儲設備的I/O吞吐率。這使得流程性開銷成為EC寫入性能的最重要制約因素。若一次寫操作的偏移和長度沒有對齊EC組,就需要部分更新涉及的EC組,因而將此類操作稱為部分寫。部分寫帶來了大部分的流程性開銷。
處理部分寫的最直接辦法是將不被寫的數據塊讀出來,跟新數據組合在一起,然后再整體編碼并寫入。目前Ceph、Sheepdog等系統都采用了這種辦法。一種簡單有效的改進是將被覆蓋數據的原始值讀出來,然后根據新舊數據的差值來進行增量編碼,得到各個校驗塊的差值,并“加”到各個校驗塊上。這種方法可以顯著減少系統總體I/O次數,然而它需要對涉及的數據塊和所有校驗塊進行原地讀寫(即在同一位置進行先讀后寫),在沒有緩存的情況下(常態),HDD需要花費8.3毫秒(7200RPM)的時間旋轉一周才能完成寫入請求,跟一次隨機I/O的平均尋道時間相當。這樣的流程極大地影響了寫入效率,即便應用層面發出的是順序寫操作,最終得到的性能也跟隨機寫差不多。
在實際應用當中,只有寫操作的偏移和長度都恰好跟EC組對齊才可以避免部分寫,然而應用往往無法照顧到底層存儲的實現細節和參數,所以部分寫構成了寫操作的主體,決定了EC存儲系統的實際寫性能。EC模式的部分寫性能大大低于三副本寫,這使得EC尚不適用于寫操作較多的場合,如云硬盤。
目前業內已有許多工作對這一問題進行改進,其中最具代表性的工作是2014年發表在FAST技術會議上的“Parity Logging with Reserved Space: Towards Efficient Updates and Recovery in Erasure-coded Clustered Storage”,它的核心思路是通過在校驗塊上記變更日志的方式來減少其上不必要的讀操作,同時將隨機寫變成順序追加寫,以改善寫入性能。然而它并不能改善原始數據塊上的寫流程,這構成了大多數的寫操作,所以系統總體寫性能改善有限。
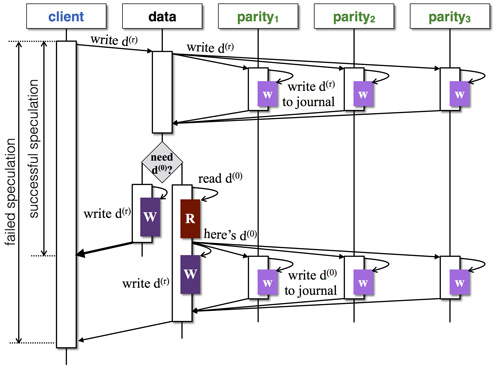
我們的改進思路仍然是在校驗塊上使用變更日志,但與傳統方法有顯著區別:(1)日志中記錄的是數據本身,而不是校驗數據的增量差值;(2)對于變更日志中涉及的每一個數據塊,都需要額外記錄1次且僅1次其變更前的數據,稱為d(0)d(0);(3)校驗塊的更新由數據塊發起,并且首次請求不附帶d(0)d(0),若校驗塊的響應明確表示需要d(0)d(0),數據塊再將d(0)d(0)發送過去。通過這樣的設計,系統可以實現在大多數情況下不需要讀取并發送d(0)d(0)到校驗塊,此為投機成功;在少數情況下投機失敗,仍然需要讀取并發送d(0)d(0)給校驗塊,但投機失敗的代價僅僅是增加一次網絡交互延遲(大約0.1~0.2毫秒),相對于機械硬盤的尋道延遲(平均幾毫秒)可以忽略不計,因而這幾乎是一個“穩賺不賠”的優化。
投機性部分寫:原理、設計與實現
考慮針對同一個數據條帶didi的一系列rr次寫操作d(1)i,d(2)i,⋯,d(r)idi(1),di(2),⋯,di(r),校驗塊為pj(j=1,2,⋯,k)pj(j=1,2,⋯,k),令 d(0)idi(0) 和 p(0)jpj(0) 分別表示 didi 和 pjpj 的原始值。根據增量編碼公式
- Δpj=aij×ΔdiΔpj=aij×Δdi
我們有 Δp(1)j=aij×Δd(1)i,Δp(2)j=aij×Δd(2)i,⋯,Δp(r)j=aij×Δd(r)iΔpj(1)=aij×Δdi(1),Δpj(2)=aij×Δdi(2),⋯,Δpj(r)=aij×Δdi(r),因而可以得到
- p(r)j=p(0)j+∑x=1rΔp(x)j=p(0)j+∑x=1raij(d(x)i−d(x−1)i)=p(0)j+aij×(d(r)i−d(0)i)pj(r)=pj(0)+∑x=1rΔpj(x)=pj(0)+∑x=1raij(di(x)−di(x−1))=pj(0)+aij×(di(r)−di(0))
根據這一公式,最終的校驗數據 p(r)j(j=1,2,⋯,k)pj(r)(j=1,2,⋯,k) 只取決于p(0)jpj(0), d(0)idi(0) 和 d(r)idi(r)。這一結論允許我們不必每次計算校驗差值,而使用數據的最終值和原始值(即 d(r)d(r) 和 d(0)d(0),省略下標)之間的差值來等價計算整個過程的校驗值增量。因而 d(0)d(0) 只需要讀取一次(在寫入 d(1)d(1) 的時候)。對于這一系列的rr次寫操作,投機只會在第一次失敗,在之后的r−1r−1次均成功,直到日志被合并進入校驗數據塊或遇到全量寫操作。對于失敗的投機,校驗塊會返回一個特定的錯誤碼,以通知數據塊將d0d0發送過來,這僅僅帶來一次網絡RTT的額外開銷,大約0.1ms~0.2ms,相對于磁盤I/O時間來說可以忽略。
現實當中的I/O負載也存在大塊順序的操作,這將產生整個EC組的全量寫操作。對于這種操作,我們將直接計算出校驗數據,并將其寫入校驗塊,同時在變更日志中記錄一個特殊操作I,表示將I之前的變更記錄取消掉,因為最新的數據已經直接寫到校驗塊內了。
根據上述原理,我們設計出如下圖所示的部分寫流程(以三個校驗塊為例):
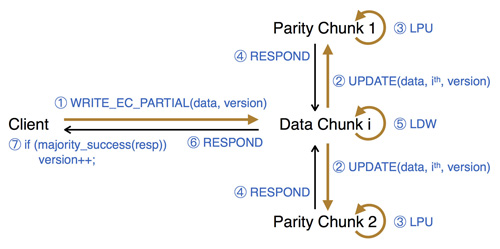
我們基于美團云現有的分布式塊存儲系統(參見之前的博客文章“分布式塊存儲系統Ursa的設計與實現”)將這一設計實現出來,稱為PBS,提供強一致性保障。系統的寫操作流程整體如下圖所示(以兩個校驗塊為例):
實驗
EC編解碼性能
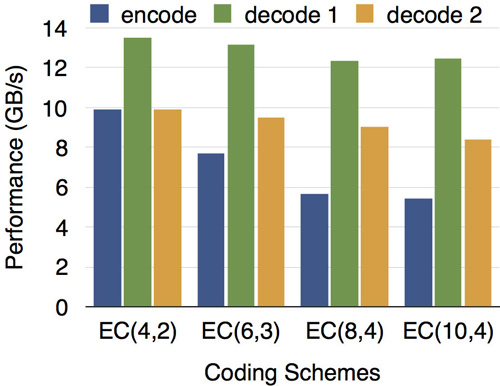
我們針對EC(4,2)、EC(6,3)、EC(8,4)、EC(10,4)等多種配置測試了編解碼運算性能。如下圖所示,在SSE、AVX等向量運算指令集的幫助下,現代CPU的1個核心每秒就能完成5~13GB數據量的編解碼工作,遠遠大于同時期各種外部存儲設備的吞吐率,所以編解碼運算已不再成為EC存儲系統的瓶頸。測試中所用CPU型號為Xeon E5-2650v3 @ 2.3GHz,圖中encode表示編碼,decode 1和2分別表示解碼1個和2個數據塊。
PBS部分寫的性能
所有的測試均在虛擬機內掛載PBS完成。我們的測試環境為3臺服務器,每臺配備10塊硬盤,7200RPM。測試了隨機寫IOPS,以及隨機寫的延遲,來衡量部分寫的性能,其中I/O大小為4KB,EC組的條帶大小為16KB。測試結果分別如下圖所示,其中HDD表示單塊7200RPM的物理硬盤的基準性能,R3表示三副本模式,PBS-1和PBS-2分別表示PBS在投機失敗(首次寫)和投機成功(第二次及以后)的情況,EC表示增量編碼方法,EC-PLog表示前文所述的在FAST'14技術大會發表的工作,代表了已有方法中的最好結果。
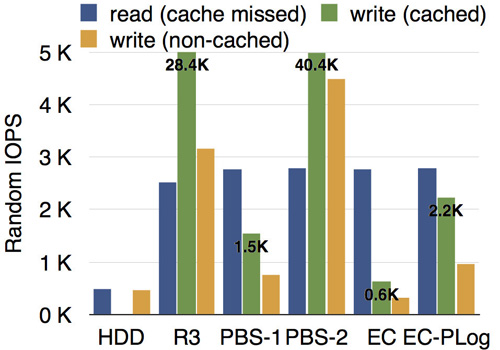
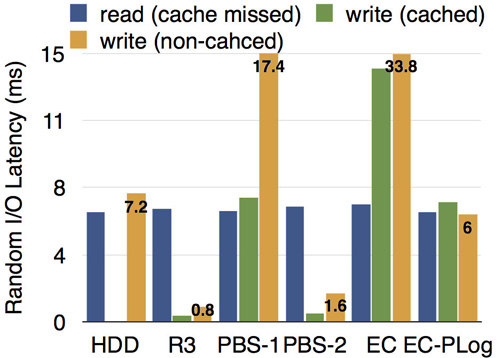
從結果可以看出,各種情況下的讀性能大致相當,PBS-1(投機失敗,小概率)比EC-PLog略低,PBS-2(投機成功,大概率)遠遠好于EC-PLog,甚至可以與三副本模式的性能相媲美。
故障恢復
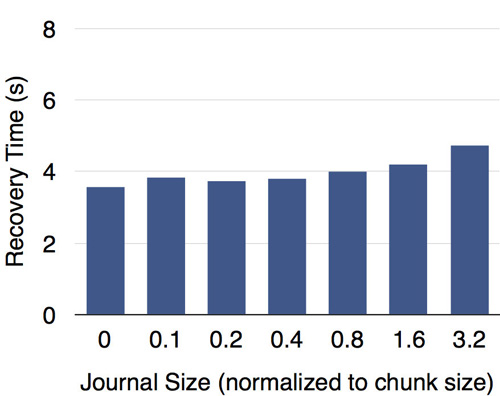
我們在內存中為日志建立了索引,因而在(故障恢復中)讀取日志時可以快速定位數據偏移。如下圖所示,測試結果表明日志大小對故障恢復速度的影響有限。