













Java線程池的理論與實(shí)踐
前段時(shí)間公司里有個(gè)項(xiàng)目需要進(jìn)行重構(gòu),目標(biāo)是提高吞吐量和可用性,在這個(gè)過程中對(duì)原有的線程模型和處理邏輯進(jìn)行了修改,發(fā)現(xiàn)有很多基礎(chǔ)的多線程的知識(shí)已經(jīng)模糊不清,如底層線程的運(yùn)行情況、現(xiàn)有的線程池的策略和邏輯、池中線程的健康狀況的監(jiān)控等,這次重新回顧了一下,其中涉及大量java.util.concurrent包中的類。本文將會(huì)包含以下內(nèi)容:
- Java中的Thread與操作系統(tǒng)中的線程的關(guān)系
- 線程切換的各種開銷
- ThreadGroup存在的意義
- 使用線程池減少線程開銷
- Executor的概念
- ThreadPoolExecutor中的一些具體實(shí)現(xiàn)
- 如何監(jiān)控線程的健康
- 參考ThreadPoolExecutor來設(shè)計(jì)適合自己的線程模型
一、問題描述
這個(gè)項(xiàng)目所在系統(tǒng)的軟件架構(gòu)(從開發(fā)到運(yùn)維)基本上采用的是微服務(wù)架構(gòu),微服務(wù)很好地解決了我們系統(tǒng)的復(fù)雜性問題,但是隨之也帶來了一些問題,比如在此架構(gòu)中大部分的服務(wù)都擁有自己單獨(dú)的數(shù)據(jù)庫,而有些(很重要的)業(yè)務(wù)需要做跨庫查詢。相信這種「跨庫查詢」的問題很多實(shí)踐微服務(wù)的公司都碰到過,通常這類問題有以下幾種解決方案(當(dāng)然,還有更多其他的方案,這里就不一一敘述了):
- 嚴(yán)格通過服務(wù)提供的API查詢。這樣做的好處是將服務(wù)完全當(dāng)做黑盒,可以最大限度得減少服務(wù)間的依賴與耦合關(guān)系,其次還能根據(jù)實(shí)際需求服務(wù)之間使用不同的數(shù)據(jù)庫類型;缺點(diǎn)是則代價(jià)太大。
- 將關(guān)心的信息冗余到自己的庫中,并提供API讓其他服務(wù)來主動(dòng)修改。優(yōu)點(diǎn)是信息更新十分實(shí)時(shí),缺點(diǎn)是增加了服務(wù)間的依賴。
- 指令與查詢分離(CQRS)。將可能被其他服務(wù)關(guān)心的數(shù)據(jù)放入數(shù)據(jù)倉庫(或者做成類似于物化視圖、搜索引擎等),數(shù)據(jù)倉庫只提供讀的功能。優(yōu)點(diǎn)是對(duì)主庫不會(huì)有壓力,服務(wù)只要關(guān)心實(shí)現(xiàn)自己的業(yè)務(wù)就好,缺點(diǎn)是數(shù)據(jù)的實(shí)時(shí)性會(huì)受到了挑戰(zhàn)。
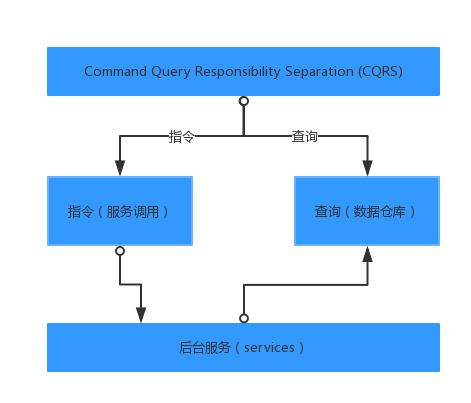
指令與查詢分離
結(jié)合實(shí)際情況,我們使用的是第3種方案。然而隨著越來越多的業(yè)務(wù)依賴讀庫,甚至依賴其中一些狀態(tài)的變化,所以讀庫的數(shù)據(jù)同步如果出現(xiàn)高延時(shí),則會(huì)直接影響業(yè)務(wù)的進(jìn)行。出了幾次這種事情后,于是下決心要改善這種情況。首先想到的就是使用線程池來進(jìn)行消息的消費(fèi)(寫入讀庫),JDK自從1.5開始提供了實(shí)用而強(qiáng)大的線程池工具——Executor框架。
二、Executor框架
Executor框架在Java1.5中引入,大部分的類都在包java.util.concurrent中,由大神Doug Lea寫成,其中常用到的有以下幾個(gè)類和接口:
java.util.concurrent.Executor一個(gè)只包含一個(gè)方法的接口,它的抽象含義是:用來執(zhí)行一個(gè)Runnable任務(wù)的執(zhí)行器。java.util.concurrent.ExecutorService對(duì)Executor的一個(gè)擴(kuò)展,增加了很多對(duì)于任務(wù)和執(zhí)行器的生命周期進(jìn)行管理的接口,也是通常進(jìn)行多線程開發(fā)最常使用的接口。java.util.concurrent.ThreadFactory一個(gè)生成新線程的接口。用戶可以通過實(shí)現(xiàn)這個(gè)接口管理對(duì)線程池中生成線程的邏輯java.util.concurrent.Executors提供了很多不同的生成執(zhí)行器的實(shí)用方法,比如基于線程池的執(zhí)行器的實(shí)現(xiàn)。
三、為什么要用線程池
Java從最開始就是基于線程的,線程在Java里被封裝成一個(gè)類java.lang.Thread。在面試中很多面試官都會(huì)問一個(gè)很基礎(chǔ)的關(guān)于線程問題:
Java中有幾種方法新建一個(gè)線程?
所有人都知道,標(biāo)準(zhǔn)答案是兩種:繼承Thread或者實(shí)現(xiàn)Runnable,在JDK源代碼中Thread類的注釋中也是這么寫的。
然而在我看來這兩種方法根本就是一種,所有想要開啟線程的操作,都必須生成了一個(gè)Thread類(或其子類)的實(shí)例,執(zhí)行其中的native方法start0()。
Java中的線程
Java中將線程抽象為一個(gè)普通的類,這樣帶來了很多好處,譬如可以很簡單的使用面向?qū)ο蟮姆椒▽?shí)現(xiàn)多線程的編程,然而這種程序?qū)懚嗔巳菀讜?huì)忘記,這個(gè)對(duì)象在底層是實(shí)實(shí)在在地對(duì)應(yīng)了一個(gè)OS中的線程。
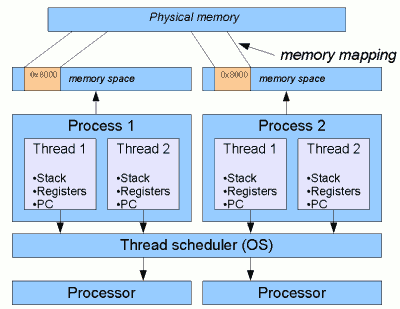
操作系統(tǒng)中的線程和進(jìn)程
上圖中的進(jìn)程(Process)可以看做一個(gè)JVM,可以看出,所有的進(jìn)程有自己的私有內(nèi)存,這塊內(nèi)存會(huì)在主存中有一段映射,而所有的線程共享JVM中的內(nèi)存。在現(xiàn)代的操作系統(tǒng)中,線程的調(diào)度通常都是集成在操作系統(tǒng)中的,操作系統(tǒng)能通過分析更多的信息來決定如何更高效地進(jìn)行線程的調(diào)度,這也是為什么Java中會(huì)一直強(qiáng)調(diào),線程的執(zhí)行順序是不會(huì)得到保證的,因?yàn)镴VM自己管不了這個(gè),所以只能認(rèn)為它是完全無序的。
另外,類java.lang.Thread中的很多屬性也會(huì)直接映射為操作系統(tǒng)中線程的一些屬性。Java的Thread中提供的一些方法如sleep和yield其實(shí)依賴于操作系統(tǒng)中線程的調(diào)度算法。
關(guān)于線程的調(diào)度算法可以去讀操作系統(tǒng)相關(guān)的書籍,這里就不做太多敘述了。
線程的開銷
通常來說,操作系統(tǒng)中線程之間的上下文切換大約要消耗1到10微秒
從上圖中可以看出線程中包含了一些上下文信息:
- CPU棧指針(Stack)、
- 一組寄存器的值(Registers),
- 指令計(jì)數(shù)器的值(PC)等,
它們都保存在此線程所在的進(jìn)程所映射的主存中,而對(duì)于Java來說,這個(gè)進(jìn)程就是JVM所在的那個(gè)進(jìn)程,JVM的運(yùn)行時(shí)內(nèi)存可以簡單的分為如下幾部分:
- 若干個(gè)棧(Stack)。每個(gè)線程有自己的棧,JVM中的棧是不能存儲(chǔ)對(duì)象的,只能存儲(chǔ)基礎(chǔ)變量和對(duì)象引用。
- 堆(Heap)。一個(gè)JVM只有一個(gè)堆,所有的對(duì)象都在堆上分配。
- 方法區(qū)(Method Area)。一個(gè)JVM只有一個(gè)方法區(qū),包含了所有載入的類的字節(jié)碼和靜態(tài)變量。
其中#1中的棧可以認(rèn)為是這個(gè)線程的上下文,創(chuàng)建線程要申請(qǐng)相應(yīng)的棧空間,而棧空間的大小是一定的,所以當(dāng)棧空間不夠用時(shí),會(huì)導(dǎo)致線程申請(qǐng)不成功。在Thread的源代碼中可以看到,啟動(dòng)線程的最后一步是執(zhí)行一個(gè)本地方法private native void start0(),代碼1是OpenJDK中start0最終調(diào)用的方法:
//代碼1
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JVMWrapper("JVM_StartThread");
JavaThread *native_thread = NULL;
bool throw_illegal_thread_state = false;
// We must release the Threads_lock before we can post a jvmti event
// in Thread::start.
{
MutexLocker mu(Threads_lock);
//省略一些代碼
jlong size =
java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
size_t sz = size > 0 ? (size_t) size : 0;
native_thread = new JavaThread(&thread_entry, sz);
}
if (native_thread->osthread() == NULL) {
THROW_MSG(vmSymbols::java_lang_OutOfMemoryError(),
"unable to create new native thread");
}
Thread::start(native_thread);
JVM_END
從代碼1中可以看到,線程的創(chuàng)建首先需要棧空間,所以過多的線程創(chuàng)建可能會(huì)導(dǎo)致OOM。
同時(shí),線程的切換會(huì)有以下開銷:
- CPU中執(zhí)行上下文的切換,導(dǎo)致CPU中的「指令流水線(Instruction Pipeline)」的中斷和CPU緩存的失效。
- 如果線程太多,線程切換的時(shí)間會(huì)比線程執(zhí)行的時(shí)間要長,嚴(yán)重浪費(fèi)了CPU資源。
- 對(duì)于共享資源的競爭(鎖)會(huì)導(dǎo)致線程切換開銷急劇增加。
根據(jù)以上的描述,所以通常建議盡可能創(chuàng)建較少的線程,減少鎖的使用(尤其是synchronized),盡量使用JDK提供的同步工具。而為了減少線程上下文切換帶來的開銷,通常使用線程池是一個(gè)有效的方法。
Java中的線程池
Executor框架中最常用的大概就是java.util.concurrent.ThreadPoolExecutor了,對(duì)于它的描述,簡單的說就是「它維護(hù)了一個(gè)線程池,對(duì)于提交到此Executor中的任務(wù),它不是創(chuàng)建新的線程而是使用池內(nèi)的線程進(jìn)行執(zhí)行」。對(duì)于「數(shù)量巨大但執(zhí)行時(shí)間很小」的任務(wù),可以顯著地減少對(duì)于任務(wù)執(zhí)行的開銷。java.util.concurrent.ThreadPoolExecutor中包含了很多屬性,通過這些屬性開發(fā)者可以定制不同的線程池行為,大致如下:
1. 線程池的大小:corePoolSize和maximumPoolSize
ThreadPoolExecutor中線程池的大小由這兩個(gè)屬性決定,前者指當(dāng)線程池正常運(yùn)行起來后的最小(核心)線程數(shù),當(dāng)一個(gè)任務(wù)到來時(shí),若當(dāng)前池中線程數(shù)小于corePoolSize,則會(huì)生成新的線程;后者指當(dāng)?shù)却?duì)列滿了之后可生成的最大的線程數(shù)。在例1中返回的對(duì)象中這兩個(gè)值相等,均等于用戶傳入的值。
2. 用戶可以通過調(diào)用java.util.concurrent.ThreadPoolExecutor上的實(shí)例方法來啟動(dòng)核心線程(core pool)
3. 可定制化的線程生成方式:threadFactory
默認(rèn)線程由方法Executors.defaultThreadFactory()返回的ThreadFactory進(jìn)行創(chuàng)建,默認(rèn)創(chuàng)建的線程都不是daemon,開發(fā)者可以傳入自定義的ThreadFactory進(jìn)行對(duì)線程的定制化。
5. 非核心線程的空閑等待時(shí)間:keepAliveTime
6. 任務(wù)等待隊(duì)列:workQueue
這個(gè)隊(duì)列是java.util.concurrent.BlockingQueue<E>的一個(gè)實(shí)例。當(dāng)池中當(dāng)前沒有空閑的線程來執(zhí)行任務(wù),就會(huì)將此任務(wù)放入等待隊(duì)列,根據(jù)其具體實(shí)現(xiàn)類的不同,又可分為3種不同的隊(duì)列策略:
- 容量為0。如:
java.util.concurrent.SynchronousQueue等待隊(duì)列容量為0,所有需要阻塞的任務(wù)必須等待池內(nèi)的某個(gè)線程有空閑,才能繼續(xù)執(zhí)行,否則阻塞。調(diào)用Executors.newCachedThreadPool的兩個(gè)函數(shù)生成的線程池是這個(gè)策略。 - 不限容量。如:不指定容量的
java.util.concurrent.LinkedBlockingQueue等待隊(duì)列的長度無窮大,根據(jù)上文中的敘述,在這種策略下,不會(huì)有多于corePoolSize的線程被創(chuàng)建,所以maximumPoolSize也就沒有任何意義了。調(diào)用Executors.newFixedThreadPool生成的線程池是這個(gè)策略。 - 限制容量。如:指定容量的任何
java.util.concurrent.BlockingQueue<E>在某些場景下(本文中將描述這種場景),需要指定等待隊(duì)列的容量,以防止過多的資源消耗,比如如果使用不限容量的等待隊(duì)列,當(dāng)有大量的任務(wù)到來而池內(nèi)又無空閑線程執(zhí)行任務(wù)時(shí),會(huì)有大量的任務(wù)堆積,這些任務(wù)都是某個(gè)類的對(duì)象,是要消耗內(nèi)存的,就可能導(dǎo)致OOM。如何去平衡等待隊(duì)列和線程池的大小要根據(jù)實(shí)際場景去斷定,如果配置不當(dāng),可能會(huì)導(dǎo)致資源耗盡、線程上下文切換消耗、或者線程調(diào)度消耗。這些都會(huì)直接影響系統(tǒng)的吞吐。
7. 任務(wù)拒絕處理器:defaultHandler
如果任務(wù)被拒絕執(zhí)行,則會(huì)調(diào)用這個(gè)對(duì)象上的RejectedExecutionHandler.rejectedExecution()方法,JDK定義了4種處理策略,用戶可以自定義自己的任務(wù)處理策略。
8. 允許核心線程過期:allowCoreThreadTimeOut
上面說的所有情況都是基于這個(gè)變量為false(默認(rèn)值)來說的,如果你的線程池已經(jīng)不使用了(不被引用),但是其中還有活著的線程時(shí),這個(gè)線程池是不會(huì)被回收的,這種情況就造成了內(nèi)存泄漏——一塊永遠(yuǎn)不會(huì)被訪問到的內(nèi)存卻無法被GC回收。
用戶可以通過在拋棄線程池引用的時(shí)候顯式地調(diào)用shutdown()來釋放它,或者將allowCoreThreadTimeOut設(shè)置為true,則在過期時(shí)間后,核心線程會(huì)被釋放,則其會(huì)被GC回收。
四、如果線程死掉了怎么辦
幾乎所有Executors中生成線程池的方法的注釋上,都有代表相同意思的一句話,表示如果線程池中的某個(gè)線程死掉了,線程池會(huì)生成一個(gè)新的線程代替它。下面是方法java.util.concurrent.Executors.newFixedThreadPool(int)上的注釋。
If any thread terminates due to a failure during execution prior to shutdown, a new one will take its place if needed to execute subsequent tasks.
線程死亡的原因
我們都知道守護(hù)線程(daemon)會(huì)在所有的非守護(hù)線程都死掉之后也死掉,除此之外導(dǎo)致一個(gè)非守護(hù)線程死掉有以下幾種可能:
- 自然死亡,
Runnable.run()方法執(zhí)行完后返回。 - 執(zhí)行過程中有未捕獲異常,被拋到了
Runnable.run()之外,導(dǎo)致線程死亡。 - 其宿主死亡,進(jìn)程關(guān)閉或者機(jī)器死機(jī)。在Java中通常是
System.exit()方法被調(diào)用 - 其他硬件問題。
線程池要保證其高可用性,就必須保證線程的可用。如一個(gè)固定容量的線程池,其中一個(gè)線程死掉了,它必須要能監(jiān)控到線程的死亡并生成一個(gè)新的線程來代替它。ThreadPoolExecutor中與線程相關(guān)的有這樣幾個(gè)概念:
java.util.concurrent.ThreadFactory,在Executors中有兩種ThreadFactory,但其提供的線程池只使用了一種java.util.concurrent.Executors.DefaultThreadFactory,它是簡單的使用ThreadGroup來實(shí)現(xiàn)。java.lang.ThreadGroup,從Java1開始就存在的類,用來建立一個(gè)線程的樹形結(jié)構(gòu),可以用它來組織線程間的關(guān)系,但其并沒有對(duì)其包含的子線程的監(jiān)控。java.util.concurrent.ThreadPoolExecutor.Worker,ThreadPoolExecutor對(duì)線程的封裝,其中還包含了一些統(tǒng)計(jì)功能。
ThreadPoolExecutor中如何保障線程的可用
在ThreadPoolExecutor中使用了一個(gè)很巧妙的方法實(shí)現(xiàn)了對(duì)線程池中線程健康狀況的監(jiān)控,代碼2是從ThreadPoolExecutor類源碼中截取的一段代碼,它們?cè)谝黄鹫f明了其對(duì)線程的監(jiān)控。
可以看到,在ThreadPoolExecutor中的線程被封裝成一個(gè)對(duì)象Worker,而將其中的run()代理到ThreadPoolExecutor中的runWorker(),在runWorker()方法中是一個(gè)獲取任務(wù)并執(zhí)行的死循環(huán)。如果任務(wù)的運(yùn)行出了什么問題(如拋出未捕獲異常),processWorkerExit()方法會(huì)被執(zhí)行,同時(shí)傳入的completedAbruptly參數(shù)為true,會(huì)重新添加一個(gè)初始任務(wù)為null的Worker,并隨之啟動(dòng)一個(gè)新的線程。
//代碼2
//ThreadPoolExecutor的動(dòng)態(tài)內(nèi)部類
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
/** 對(duì)象中封裝的線程 */
final Thread thread;
/** 第一個(gè)要運(yùn)行的任務(wù),可能為null. */
Runnable firstTask;
/** 任務(wù)計(jì)數(shù)器 */
volatile long completedTasks;
//省略其他代碼
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
try {
beforeExecute(wt, task);
try {
task.run();
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
五、回到我的問題
由于各種各樣的原因,我們并沒有使用數(shù)據(jù)庫自帶的主從機(jī)制來做數(shù)據(jù)的復(fù)制,而是將主庫的所有DML語句作為消息發(fā)送到讀庫(DTS),同時(shí)自己實(shí)現(xiàn)了數(shù)據(jù)的重放。第一版的數(shù)據(jù)同步服務(wù)十分簡單,對(duì)于主庫的DML消息處理和消費(fèi)(寫入讀庫)都是在一個(gè)線程內(nèi)完成的.這么實(shí)現(xiàn)的優(yōu)點(diǎn)是簡單,但缺點(diǎn)是直接導(dǎo)致了表與表之間的數(shù)據(jù)同步會(huì)受到影響,如果有一個(gè)表A忽然來了很多的消息(往往是批量修改數(shù)據(jù)造成的),則會(huì)占住消息處理通道,影響其他業(yè)務(wù)數(shù)據(jù)的及時(shí)同步,同時(shí)單線程寫庫吞吐太小。
上文說到,首先想到的是使用線程池來做消息的消費(fèi),但是不能直接套用上邊說的Executor框架,由于以下幾個(gè)原因:
- ThreadPoolExecutor中默認(rèn)所有的任務(wù)之間是不互相影響的,然而對(duì)于數(shù)據(jù)庫的DML來說,消息的順序不能被打亂,至少單表的消息順序必須有序,不然會(huì)影響最終的數(shù)據(jù)一致。
- ThreadPoolExecutor中所有的線程共享一個(gè)等待隊(duì)列,然而為了防止表與表之間的影響,每個(gè)線程應(yīng)該有自己的任務(wù)等待隊(duì)列。
- 寫庫操作的吞吐直接受到提交事務(wù)數(shù)的影響,所以此多線程框架要可以支持任務(wù)的合并。
重復(fù)造輪子是沒有意義的,但是在我們這種場景下JDK中現(xiàn)有的Executor框架不符合要求,只能自己造輪子。
我的實(shí)現(xiàn)
首先把線程抽象成「DML語句的執(zhí)行器(Executor)」。其中包含了一個(gè)Thread的實(shí)例,維護(hù)了自己的等待隊(duì)列(限定容量的阻塞隊(duì)列),和對(duì)應(yīng)的消息執(zhí)行邏輯。
除此之外還包含了一些簡單的統(tǒng)計(jì)、線程健康監(jiān)控、合并事務(wù)等處理。
Executor的對(duì)象實(shí)現(xiàn)了
Thread.UncaughtExceptionHandler接口,并綁定到其工作線程上。同時(shí)ExecutorGroup也會(huì)再生成一個(gè)守護(hù)線程專門來守護(hù)池內(nèi)所有線程,作為額外的保險(xiǎn)措施。
把線程池的概念抽象成執(zhí)行器組(ExecutorGroup),其中維護(hù)了執(zhí)行器的數(shù)組,并維護(hù)了目標(biāo)表到特定執(zhí)行器的映射關(guān)系,并對(duì)外提供執(zhí)行消息的接口,其主要代碼如下:
//代碼3
public class ExecutorGroup {
Executor[] group = new Executor[NUM];
Thread boss = null;
Map<String, Integer> registeredTables = new HashMap<>(32);
// AtomicInteger cursor = new AtomicInteger();
volatile int cursor = 0;
public ExecutorGroup(String name) {
//init group
for(int i = 0; i < NUM; i++) {
logger.debug("啟動(dòng)線程{},{}", name, i);
group[i] = new Executor(this, String.format("sync-executor-%s-%d", name, i), i / NUM_OF_FIRST_CLASS);
}
startDaemonBoss(String.format("sync-executor-%s-boss", name));
}
//額外的保險(xiǎn)
private void startDaemonBoss(String name) {
if (boss != null) {
boss.interrupt();
}
boss = new Thread(() -> {
while(true) {
//休息一分鐘。。。
if (this.group != null) {
for (int i = 0; i < group.length; i++) {
Executor executor = group[i];
if (executor != null) {
executor.checkThread();
}
}
}
}
});
boss.setName(name);
boss.setDaemon(true);
boss.start();
}
public void execute(Message message){
logger.debug("執(zhí)行消息");
//省略消息合法性驗(yàn)證
if (!registeredTables.containsKey(taskKey)) {
//已注冊(cè)
// registeredTables.put(taskKey, cursor.getAndIncrement());
registeredTables.put(taskKey, cursor++ % NUM);
}
int index = registeredTables.get(taskKey);
logger.debug("執(zhí)行消息{},注冊(cè)索引{}", taskKey, index);
try {
group[index].schedule(message);
} catch (InterruptedException e) {
logger.error("準(zhǔn)備消息出錯(cuò)", e);
}
}
}
完成后整體的線程模型如下圖所示:
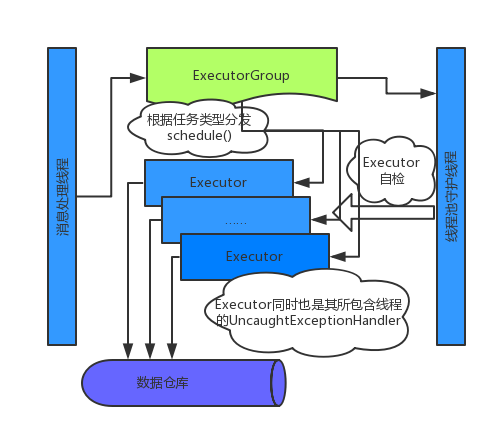
新的線程模型
Java1.7新加入的TransferQueue
Java1.7中提供了新的隊(duì)列類型TransferQueue,但只提供了一個(gè)它的實(shí)現(xiàn)java.util.concurrent.LinkedTransferQueue<E>,它有更好的性能表現(xiàn),可它是一個(gè)無容量限制的隊(duì)列,而在我們的這個(gè)場景下必須要限制隊(duì)列的容量,所以要自己實(shí)現(xiàn)一個(gè)有容量限制的隊(duì)列。




















