達(dá)觀推薦算法實(shí)現(xiàn):協(xié)同過(guò)濾之item embedding
推薦系統(tǒng)本質(zhì)是在用戶需求不明確的情況下,解決信息過(guò)載的問(wèn)題,聯(lián)系用戶和信息,一方面幫助用戶發(fā)現(xiàn)對(duì)自己有價(jià)值的信息,另一方面讓信息能夠展現(xiàn)在對(duì)它感興趣的用戶面前,從而實(shí)現(xiàn)信息消費(fèi)者和信息生產(chǎn)者的雙贏(這里的信息的含義可以非常廣泛,比如咨詢、電影和商品等,下文中統(tǒng)稱為item)。達(dá)觀數(shù)據(jù)相關(guān)推薦是達(dá)觀推薦系統(tǒng)中的重要組成部分,其價(jià)值在于,在沒(méi)有用戶畫(huà)像信息的情況下,也能給用戶以好的推薦體驗(yàn),比如資訊類,通過(guò)達(dá)觀相關(guān)推薦算法找到item相關(guān)的其他item,可以提供對(duì)某一類或者針對(duì)某一事件多角度多側(cè)面的深度閱讀。本文主要先簡(jiǎn)單介紹相關(guān)推薦的一些常用算法,然后介紹一下基于item embedding的協(xié)同過(guò)濾。
1. 達(dá)觀相關(guān)推薦的常用算法
1.1 Content-based相關(guān)推薦
基于內(nèi)容的推薦一般依賴于一套好的標(biāo)簽系統(tǒng),通過(guò)計(jì)算item之間tag集合的相似性來(lái)衡量item之間的相似性,一套好的標(biāo)簽系統(tǒng)需要各方面的打磨,一方面需要好的編輯,一方面也依賴于產(chǎn)品的設(shè)計(jì),引導(dǎo)用戶在使用產(chǎn)品的過(guò)程中,對(duì)item提供優(yōu)質(zhì)的tag。
1.2 基于協(xié)同過(guò)濾的相關(guān)推薦
協(xié)同過(guò)濾主要分為基于領(lǐng)域以及基于隱語(yǔ)義模型。
基于領(lǐng)域的算法中,ItemCF是目前業(yè)界應(yīng)用最多的算法,其主要思想為“喜歡item A的用戶大都喜歡用戶 item B”,通過(guò)挖掘用戶歷史的操作日志,利用群體智慧,生成item的候選推薦列表。主要統(tǒng)計(jì)2個(gè)item的共現(xiàn)頻率,加以時(shí)間的考量,以及熱門(mén)用戶以及熱門(mén)item的過(guò)濾以及降權(quán)。
LFM(latent factor model)隱語(yǔ)義模型是最近幾年推薦系統(tǒng)領(lǐng)域最為熱門(mén)的研究話題,該算法最早在文本挖掘領(lǐng)域被提出,用于找到文本隱含的語(yǔ)義,在推薦領(lǐng)域中,其核心思想是通過(guò)隱含特征聯(lián)系用戶和物品的興趣。主要的算法有pLSA、LDA、matrix factorization(SVD,SVD++)等,這些技術(shù)和方法在本質(zhì)上是相通的,以LFM為例,通過(guò)如下公式計(jì)算用戶u對(duì)物品i的興趣:
![]()
公式中pu,k和qi,k是模型的參數(shù),其中pu,k度量了用戶u的興趣和第k個(gè)隱類的關(guān)系,而qi,k度量了第k個(gè)隱類和物品i之間的關(guān)系。而其中的qi,k可視為將item投射到隱類組成的空間中去,item的相似度也由此轉(zhuǎn)換為在隱空間中的距離。
2. item2vec:NEURAL ITEM EMBEDDING
2.1 word2vec
2013年中,Google發(fā)布的word2vec工具引起了大家的熱捧,很多互聯(lián)網(wǎng)公司跟進(jìn),產(chǎn)出了不少成果。16年Oren Barkan以及Noam Koenigstein借鑒word2vec的思想,提出item2vec,通過(guò)淺層的神經(jīng)網(wǎng)絡(luò)結(jié)合SGNS(skip-gram with negative sampling)訓(xùn)練之后,將item映射到固定維度的向量空間中,通過(guò)向量的運(yùn)算來(lái)衡量item之間的相似性。下面對(duì)item2vec的做簡(jiǎn)要的分享:
由于item2vec基本上是參照了google的word2vec方法,應(yīng)用到推薦場(chǎng)景中的item2item相似度計(jì)算上,所以首先簡(jiǎn)單介紹word2vec的基本原理。
Word2vec主要用于挖掘詞的向量表示,向量中的數(shù)值能夠建模一個(gè)詞在句子中,和上下文信息之間的關(guān)系,主要包括2個(gè)模型:CBOW(continuous bag-of-word)和SG(skip-gram),從一個(gè)簡(jiǎn)單版本的CBOW模型介紹,上下文只考慮一個(gè)詞的情形,如圖1所示,
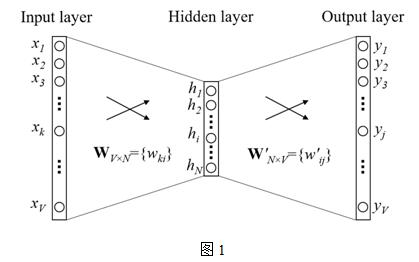
假設(shè)只有一個(gè)隱層的神經(jīng)網(wǎng)絡(luò),輸入層以及輸出層均為詞的one-hot編碼表示,詞表大小假設(shè)為V,隱層神經(jīng)元個(gè)數(shù)為N,相鄰層的神經(jīng)元為全連接,層間的權(quán)重用V*N的矩陣W表示,隱層到輸出層的activation function采用softmax函數(shù),
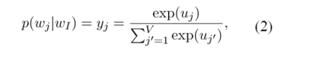
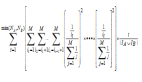
其中wI,wj為詞表中不同的詞,yj為輸出層第j個(gè)神經(jīng)元的輸出,uj為輸入層經(jīng)過(guò)權(quán)重矩陣W到隱層的score,uj’為隱層經(jīng)過(guò)權(quán)重矩陣W’到輸出層的score。訓(xùn)練這個(gè)神經(jīng)網(wǎng)絡(luò),用反向傳播算法,先計(jì)算網(wǎng)絡(luò)輸出和真實(shí)值的差,然后用梯度下降反向更新層間的權(quán)重矩陣,得到更新公式:
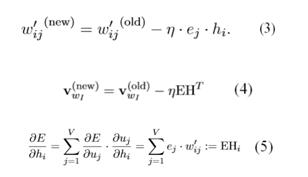
其中,η為更新的步長(zhǎng),ej為模型預(yù)測(cè)以及真實(shí)值之間的誤差,h為隱層向量。
圖2為上下文為多個(gè)詞時(shí)的情況,中間的隱層h計(jì)算由
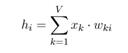
改為
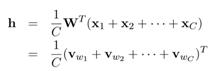
即輸入向量為多個(gè)上下文向量相加求平均,后續(xù)的參數(shù)學(xué)習(xí)與上文的單個(gè)詞的上下文情況類似。遍歷整個(gè)訓(xùn)練集context-target詞對(duì),經(jīng)過(guò)多次迭代更新模型參數(shù),對(duì)模型中的向量的影響將會(huì)累積,最終學(xué)到對(duì)詞的向量表示。
Skip-gram跟CBOW的輸入層和輸出層正好對(duì)調(diào),區(qū)別就是CBOW是上下文,經(jīng)過(guò)模型預(yù)測(cè)當(dāng)前詞,而skip-gram是通過(guò)當(dāng)前詞來(lái)預(yù)測(cè)上下文。
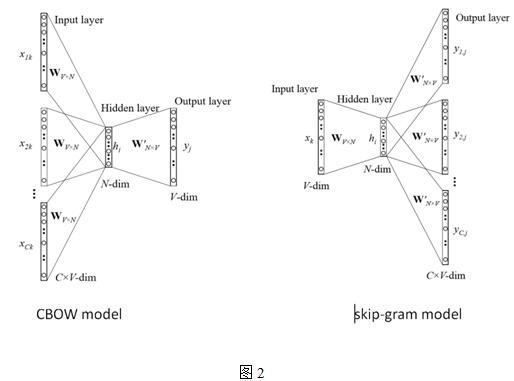
目前為止,對(duì)詞表中的每個(gè)詞,有兩種向量表示:input vector和output vector,對(duì)應(yīng)輸入層到隱層權(quán)重矩陣W的行向量和隱層到輸出層權(quán)重矩陣W'的列向量,從等式4、5可以看出,對(duì)每一個(gè)訓(xùn)練樣本,都需要遍歷詞表中的每一個(gè)詞,因此,學(xué)習(xí)output vector的計(jì)算量是非常大的,如果訓(xùn)練集或者詞表的規(guī)模大的話,在實(shí)際應(yīng)用中訓(xùn)練不具可操作性。為解決這個(gè)問(wèn)題,直覺(jué)的做法是限制每個(gè)訓(xùn)練樣本需要更新的output vectors,google提出了兩個(gè)方法:hierarchical softmax和negative sampling,加快了模型訓(xùn)練的速度,再次不做展開(kāi)討論。
2.2 item2vec
由于wordvec在NLP領(lǐng)域的巨大成功,Oren Barkan and Noam Koenigstein受此啟發(fā),利用item-based CF學(xué)習(xí)item在低維latent space的embedding representation,優(yōu)化item的相關(guān)推薦。
詞的上下文即為鄰近詞的序列,很容易想到,詞的序列其實(shí)等價(jià)于一系列連續(xù)操作的item序列,因此,訓(xùn)練語(yǔ)料只需將句子改為連續(xù)操作的item序列即可,item間的共現(xiàn)為正樣本,并按照item的頻率分布進(jìn)行負(fù)樣本采樣。
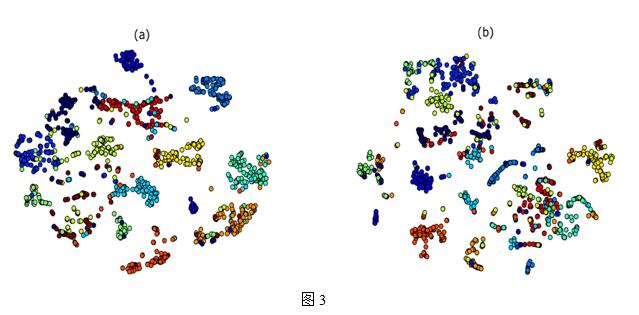
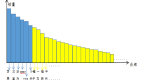
Oren Barkan and Noam Koenigstein以SVD作為baseline,SVD的隱類以及item2vec的維度都取40,用Microsoft Xbox Music service收集的 user-artists數(shù)據(jù)集,對(duì)結(jié)果進(jìn)行聚類,如圖3所示,圖a是item2vec的聚合效果,圖b是SVD分解的聚合效果,看起來(lái)item2vec的聚合效果要更好些。
作者嘗試將item2vec應(yīng)用到達(dá)觀數(shù)據(jù)的相關(guān)推薦當(dāng)中,由于資訊、短視頻類的場(chǎng)景一般的連續(xù)item操作會(huì)比較多,因此天然的非常適合用item2vec來(lái)訓(xùn)練item的向量表示,從實(shí)際的訓(xùn)練結(jié)果和線上評(píng)估來(lái)看,item2vec對(duì)CTR提升是有明顯幫助的。
本文作者:
范雄雄,達(dá)觀數(shù)據(jù)個(gè)性化推薦引擎工程師,工作包括推薦系統(tǒng)的架構(gòu)設(shè)計(jì)和開(kāi)發(fā)、推薦效果優(yōu)化等,所在團(tuán)隊(duì)開(kāi)發(fā)的個(gè)性化推薦系統(tǒng)曾創(chuàng)造上線后效果提升300%的記錄。復(fù)旦大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)專業(yè)碩士,曾在愛(ài)奇藝開(kāi)發(fā)多款大數(shù)據(jù)產(chǎn)品,對(duì)個(gè)性化推薦、數(shù)據(jù)挖掘和分析、用戶行為建模、大數(shù)據(jù)處理有較深入的理解和實(shí)踐經(jīng)驗(yàn)。
【本文為51CTO專欄作者“達(dá)觀數(shù)據(jù)”的原創(chuàng)稿件,轉(zhuǎn)載可通過(guò)51CTO專欄獲取聯(lián)系】