京東分布式存儲建設之路
一拍而合,京東分布式存儲起航
在項目中你經常會遇到,有一些圖片、視頻或者文本需要存儲,你希望它不丟失的同時還要能提供高速讀寫的能力。對于京東來說,這樣的需求每天都在發生著,而且要求會更高,因為這些可能是用戶的訂單數據,你希望即使在寫的時候斷電了、磁盤壞了,你的數據還在;你希望即使服務器故障了、交換機壞了甚至機房掛了,用戶還能正常訪問;你希望在大促來臨時即使用戶訪問量倍級增長,它依然能提供高速讀寫。沒錯,現在很多人都會告訴你,用JFS京東文件系統,它能滿足你的需求。
時間回到2013年,海鋒哥剛來到京東,很快地他發現京東對存儲有強烈的需求,既有海量小文件的在線存儲,又有大量離線數據的存儲,當前公司內部在這塊做的并不好,各個業務部門自己做自己的,很多慢慢開始滿足不了業務增長的需要了。一個想法油然而生,他決定做京東統一的分布式存儲平臺,滿足公司各個業務線的需要。
有另外一個存儲的小團隊,成員只有6,7個人,雖然工作年限普遍不長,有幾個還是剛畢業,但也都想著在存儲方向做出一番業績。同樣的愿景,很快大家走到了一起。在海鋒哥的領導下,系統技術部存儲組正式成立,開始京東分布式存儲的研發。
從2013年到2016年,這一做就是三年,當年的小鮮肉都成為了公司存儲方向的中堅力量,成為了存儲專家,而JFS也成為了京東業務核心底層存儲,支撐了公司1000多個業務。一路走來,踩過很多坑,也有一些體會,給大家分享下。
艱難抉擇,分布式存儲技術選型
京東有各種各樣的數據存儲需求,有大小10KB的訂單數據,每天以上億的速度增長;有大小90k-200k的圖片數據,總量超過幾十億,且每天還在以千萬的速度增長;也有幾十兆的App客戶端文件,每次更新都伴隨著巨量的用戶訪問;還有1GB甚至10GB以上的內部日志文件存儲。各個業務部門使用的存儲方式也五花八門,有用Mysql的Blob類型存儲,也有用開源的FastDFS和Hdfs。誠然,這些軟件在京東的快速發展中起了至關重要的作用,但隨著業務規模的持續增長,也開始暴露出來了各種各樣的問題。擺在我們面前的路有兩條:一種是在開源系統的基礎上做定制開發,還有一種是自研。兩種方式各有優缺點,最終經過一輪輪調研下來,我們還是決定走自研之路。這里以大家熟知的Hdfs及其生態為例,回顧下當時抉擇的過程。
毫無疑問,Hdfs是一個相當優秀的開源存儲項目,但它畢竟是為離線大文件設計,對于京東海量的在線小文件無能為力,二次開發需要對整個架構動手術。還有一種考慮,使用Hdfs存儲大文件,使用HBase存儲小文件。當然,這種方案也不適合京東,主要有兩點:***、HBase讀取文件時,請求先打到RegionServer上,由RegionServer去Hdfs取數據,再返回,相當于一次IO請求經過了兩次網絡傳輸,這對于追求***速度的很多應用場景是不合適的;第二、HBase在做Split的時候會導致服務短暫的不可用,這對很多要求提供7*24小時無間斷服務的業務則更是不可接受。
雖然自研的周期會更長,但它靈活可控,且從長期來看,也能獲得技術收益。
日夜挑燈,JFS小文件存儲
廚師到位,菜已洗凈,接下來就是從哪里下手了。要做京東統一的分布式存儲,這是一件非常困難的事情,因為即便是現在,也沒有見到能同時很好的支持海量在線小文件和離線大文件的開源解決方案。很慶幸的是,當時我們并沒有選擇一步到位的***解決方案,而是緊扣業務,高度定制,分期展開這條路。
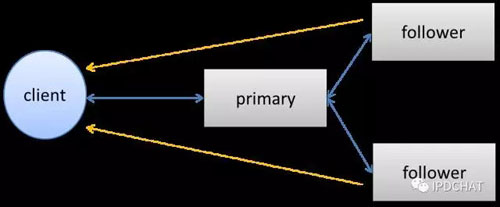
小文件存儲則被選為了桌上的***道菜。無論是商品圖片、交易訂單,還是庫房訂單,這些電商數據都需要非常強的可靠性、可用性和一致性。在復制協議上,我們采取了三副本強一致性復制,由1Primary +2Followers構成,如下圖所示。寫操作時,由Client將數據發送到主上,然后由主同時發給兩個從副本,三副本都寫入成功后才返回給用戶成功。而在讀取時,優先在從上讀取,來提高系統的并發能力。
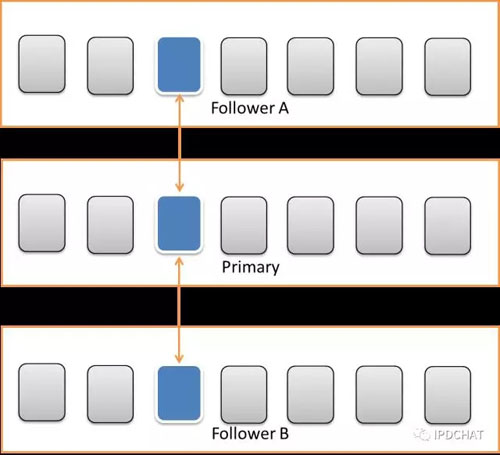
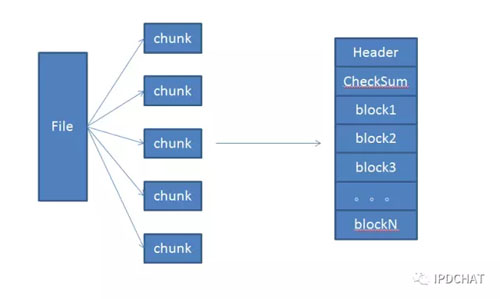
在數據存儲上,考慮到文件比較小,如果用戶上傳一個文件,對應在服務器上建一個文件存儲數據的話,那么一塊2T的盤上面將存放幾千萬甚至上億個文件,給服務器帶來沉重的負擔。我們采取了事先建好大文件,然后不停的追加寫入方式,使用偏移量和大小來訪問數據。當然為了避免單個大文件集中讀寫造成文件鎖資源競爭激烈,我們采取了多文件追加方式,如下圖所示:
現在已記不清經過多少個日日夜夜的挑燈夜戰,慢慢地加班餐的小姑娘因為熟識了,會有意給我們多舀一些菜;團隊的年輕小伙伴白凈的臉上多了一圈黑眼圈。終于,在4個月后的一天,我們迎來了***個孩子,京東小文件存儲系統終于正式落地。當然,它也沒令大家失望,在與同類的開源軟件對比測試中,性能等各項指標都占優。
一個新系統的推廣總是很艱難的,最初我們開始推廣給在一些非核心業務的數據存儲上,慢慢的應用起來。當然,我們也一直在準備著一條大魚的到來。
小試牛刀,京東新圖片系統
時間回到了2014年,老一些的員工可能還有印象,隨著圖片數據量和訪問量的暴增,老的圖片服務已經達到了性能瓶頸。客服每天都會收到大量用戶投訴圖片訪問速度慢,IO異常、多副本數據不一致的情況也時有發生,告警郵件都快塞滿了相關業務部門的郵箱。
老的圖片系統最早可以追溯到好多年前,當時也是選擇了一個業內使用廣泛的開源存儲方案。最初的一兩年一直相安無事,但隨著數據量的暴增,開始暴露各種各樣的問題。最開始業務部門還能通過修改配置,加一些緩存策略來解決,到了后來,這些完全不起作用了,需要從整體存儲架構上優化。
這時候的JFS在一些非核心的業務上獲得了較好口碑,于是,圖片的業務部門找到我們,希望能將圖片業務遷移到JFS上來。
時間已經到了14年的4月份,離京東上市的日期也就一個月了。我們需要在JFS存儲之上開發一個新的圖片系統,還需要在不影響現有的業務情況下,完成20億歷史圖片的遷移,這其中蘊藏的巨大風險大家都心知肚明,但并沒有經過太多復雜的權衡,我們很快應允了下來。
再接下來就是一段與時間賽跑的歷程,團隊成員快速分工,幾個同事用了一周的時間完成新圖片系統搭建,同時另幾個同事完成了數據雙寫、遷移和校驗方案的實現,然后再用了三個星期完成了全部20億存量數據遷移和校驗。最終在公司上市前夕,完成了新老圖片系統的切換,徹底解決了圖片訪問慢的問題。
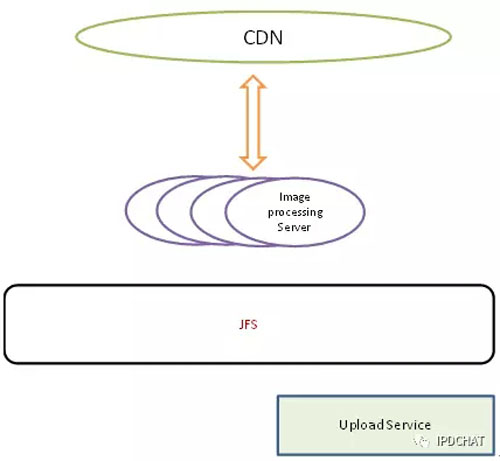
京東的圖片規格很多,同一副圖片可能有10多種不同的規格,因此我們在源站只存一副原圖,CDN沒有***的圖片回源站進行實時壓縮,這樣不僅節約了存儲空間,也滿足了業務不斷變化的需求。如下圖所示:
當然,在解決最核心的圖片存儲和簡單圖片處理后,我們也做了一些工作推動了京東圖片技術的發展。在縮放效率上,我們和Intel進行了緊密合作,通過代碼重構、ICC編譯、IPP編譯將圖片縮放速度提升到最初的3倍以上。在2014年我們創新性的將圖片Webp格式引入京東,與無線部門緊密合作,將移動端的圖片全部替換成Webp格式。圖片整體大小下降了50%,給CDN節約了30%的流量,也給用戶節約了巨大的下行流量,讓用戶訪問速度更快,大大提升了用戶體驗。
繼續前行,JFS大文件存儲
對于大文件來說,單客戶端的上傳和下載性能同樣是一個重要的指標。小文件的復制協議1Primary+2Followers方式已不再是***的,Primary拿到數據后同時發送給兩個從副本,這樣,Primary的帶寬資源將成為系統的瓶頸。因此,在大文件存儲復制協議的選擇上,JFS采取了鏈式復制來***限度利用系統的帶寬資源。鏈式復制結構如下圖所示。而在數據發送和接受上,我們使用了流式處理,大大提高大文件的傳輸效率。

在數據存儲上,恰恰與小文件相反,我們將一個大文件分成多個塊來存儲,這樣可以規避局部過熱的文件造成了單機磁盤IO過載,同時,分成多塊后也更利于整個系統資源的調度。
快速發展,京東對象存儲
前面的小文件存儲和大文件存儲,從可靠性、可用性和穩定性方面,已經滿足了大部分的業務需求,但使用起來不是很方便,上傳和下載都需要通過SDK,用戶排查問題不是那么便捷,且對多語言的支持也不好。接下來我們瞄準了亞馬遜的S3產品形態。
簡單對象存儲,支持Http協議;支持文本、圖片、視頻等任何類型數據的存儲;支持1個字節到1TB大小的數據存儲;支持list操作,用戶數據可以有層次結構。這對于業務場景眾多、應用復雜的京東來說,太合適了。
于是,我們決定在JFS上面構建對象存儲,提供用戶更便捷的訪問。
對象存儲包含幾個部分,除了前面我們已經提到的大小文件存儲,還需要構建Gateway、賬戶和Bucket管理、日志處理等等,當然還有最復雜的元數據管理。
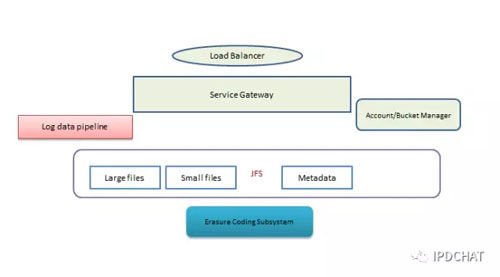
對象存儲的元數據管理是一個業內難題。雖然對象存儲并無目錄的概念,但要支持按前綴進行List操作,即能通過Prefix和Delimiter的結合,實現層次查詢。在數據量不大時,類似于Hdfs的NameNode將全部用戶Key都存在內存中就能滿足需求,但當對象的數量過億或者十億時,將會耗盡內存,無法做到橫向擴展。很多KV存儲能做到隨意橫向擴展,但不能很好的支持對象存儲List請求。
我們的方案也不是一個***的解決方案,但已經能滿足京東百億級別元數據管理,這里發出來供大家探討下。我們采取Mysql+Jimdb(京東自研的高速KV緩存系統),將元數據扁平化持久存儲在Mysql中,同時借助于Mysql的B樹結構實現元數據的List層次查詢。使用Jimdb作為緩存,提供高并發能力。當然,僅僅Mysql并不能做到***橫向擴展,我們在Mysql之上做了一個自動分庫分表的系統ET,能在不影響業務的情況下,實現Mysql的分裂和數據在線遷移。如下圖所示:
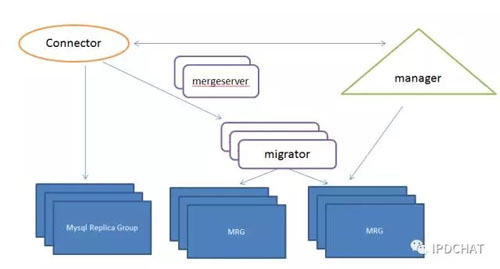
正常情況下,Client直接連到對應的Mysql復制組。當某組Mysql記錄數目達到一定限度后,Manager觸發分裂,啟動一個Migrator作為Mysql代理,和Manager緊密配合完成實時數據處理和歷史數據遷移。
對象存儲一經推出就受到業務部門的廣泛歡迎,目前已經支持了京東1200多個業務數據的存儲,雙十一***峰值每秒同時25000個對象實時讀寫,存儲的對象達到百億級別,數據量超過10PB。
持續創新,電子簽收后臺系統
電子簽收小票的存儲就是對象存儲的一個重要應用。
京東一天的訂單量就有成百上千萬,以前每天都要保留幾百萬張的紙質小票,堆積在倉庫里面。出現糾紛時,還需要從上億張紙質小票中找到用戶當時簽收的小票,這無疑是一項繁瑣、費時費錢、又不環保的工作,且大大提升了京東物流的管理成本。從環保維度和成本維度考量,運營系統青龍研發部創新性的提出了使用電子簽收。
整個電子簽收產生的海量簽名圖片需要高安全性、高穩定性、高持久性的保存。且根據國家的快遞管理辦法規定,物流的簽收保存是一年,再加上簽收的金融小票,意味著系統需要能夠存儲百億級別的用戶簽收圖片。海量的數據存儲也給青龍研發帶來了一些困難。
這無疑是對象存儲很好的一個應用場景,但其定制化的加解密、文字轉圖片、圖片合成也給對象存儲提出了更高的要求。為了更好的支持業務創新,我們在對象存儲的基礎上,研發了電子簽收后臺系統。能夠根據傳回來的簽收信息,按照指定樣式生成簽收小票圖片,并與用戶簽名圖片合成;按照業務高安全性要求,加密存儲數據,保護用戶數據的絕對安全;對經POS機加密傳回來的數據,在用戶查看時解密展示給用戶。
初衷未改,JFS統一存儲
JFS小文件和大文件存儲的實現,已經能夠解決京東大量應用場景。但離我們的One team,One storage的愿景還很遠。接下來我們開始了小文件和大文件存儲的整合。同樣的三副本強一致性復制,在復制協議上,我們進行了統一,同時兼顧到小文件和大文件性能,采取了鏈式復制。而在文件存儲上,大小文件處理迥異,無法強行統一起來,因此我們將大小文件存儲作為可插拔的不同存儲引擎,分管集群中不同類型文件的存儲。
面向未來,京東分布式存儲展望
對于未來,我們也在規劃著讓JFS支持共享存儲,可以直接掛載在容器上。這樣,應用的非結構化數據直接存到了分布式存儲上,減少了日志等數據先存在本地磁盤,再收集到分布式存儲上的環節。同時,和容器技術的結合更緊密,也支持了容器故障的快速調度和轉移。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】