大數據小課堂——深入淺出Kafka
從是否正確出發,而不是從能否接受出發。
Start with what is right rather than what is acceptable.
弗蘭茲·卡夫卡
1 背景
假設你意氣風發,要開發新一代的互聯網應用,以期在互聯網事業中一展宏圖。借助云計算,很容易開發出如下原型系統:
1. Web應用:部署在云服務器上,為個人電腦或者移動用戶提供的訪問體驗。
2. SQL數據庫:為Web應用提供數據持久化以及數據查詢。
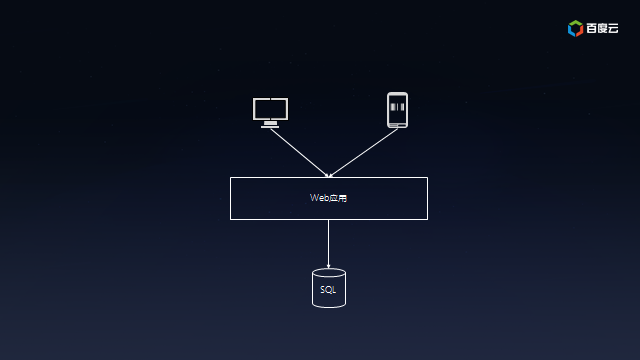
這套架構簡潔而高效,很快便能夠部署到百度云等云計算平臺,以便快速推向市場。互聯網不就是講究小步快跑嘛!
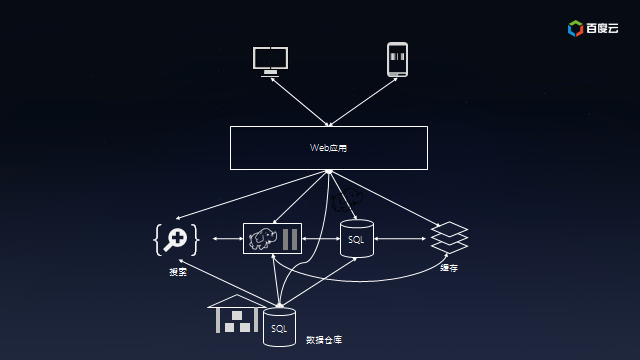
好景不長。隨著用戶的迅速增長,所有的訪問都直接通過SQL數據庫使得它不堪重負,不得不加上緩存服務以降低SQL數據庫的荷載;為了理解用戶行為,開始收集日志并保存到Hadoop上離線處理,同時把日志放在全文檢索系統中以便快速定位問題;由于需要給投資方看業務狀況,也需要把數據匯總到數據倉庫中以便提供交互式報表。此時的系統的架構已經盤根錯節了,考慮將來還會加入實時模塊以及外部數據交互,真是痛并快樂著……
這時候,應該跑慢一些,讓靈魂跟上來。
本質上,這是一個數據集成問題。沒有任何一個系統能夠解決所有的事情,所以業務數據根據不同用途存而放在不同的系統,比如歸檔、分析、搜索、緩存等。數據冗余本身沒有任何問題,但是不同系統之間像意大利面條一樣復雜的數據同步卻是挑戰。
這時候就輪到Kafka出場了。
Kafka可以讓合適的數據以合適的形式出現在合適的地方。Kafka的做法是提供消息隊列,讓生產者單往隊列的末尾添加數據,讓多個消費者從隊列里面依次讀取數據然后自行處理。之前連接的復雜度是O(N^2),而現在降低到O(N),擴展起來方便多了:
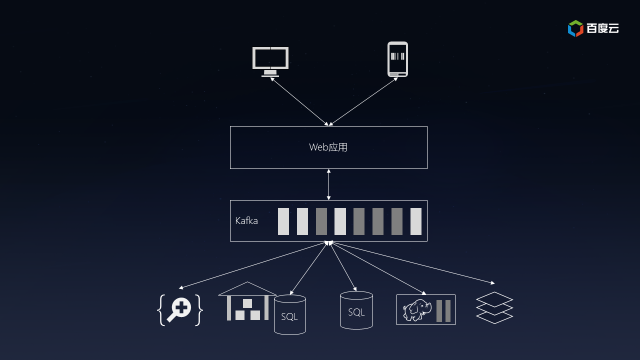
在Kafka的幫助下,你的互聯網應用終于能夠支撐飛速增長的業務,成為下一個BAT指日可待。
2 Apache Kafka
Kafka最早由LinkedIn開發,如今已經成為Apache基金會***項目,被Walmart、Netflix、PayPal、Uber、eBay等采用。
在國內互聯網圈子中Kafka也是大數據圈子中必備的社交貨幣,茶余飯后指點江山說起卡夫卡,聯想到Franz Kafka是文青,聯想到Apache Kafka的才是大數據工程師。
本質上Kafka是分布式的流數據平臺,因為以下特性而著名:
1. 提供Pub/Sub方式的海量消息處理。
2. 以高容錯的方式存儲海量數據流。
3. 保證數據流的順序。
說起Pub/Sub,熟悉企業應用集成(Enterprise Application Integration,EAI)的朋友不會陌生,它是一種處理消息的范式,消息的發布者(Pub)只需要指定消息的類別,而不需要與訂閱者(Sub)打交道。訂閱者對一個或多個類別表達興趣,于是只接收感興趣的消息,而不需要知道什么樣的發布者發布的消息。這種發布者和訂閱者的解耦可以給應用帶來更好的可擴展性。
打個比方,你的公司業務蓬勃發展,前后開發了多個互聯網應用都需要做市場推廣。一種方法是通過電話向客戶推廣產品新特性,不但需要找到每個互聯網應用所對應的客戶名單,還要挨個電話聯系,可是,客戶不一定有空接電話或者已經在通訊中了,長長的客戶名單也會讓你頭疼不已;另一種方法是為每個互聯網應用創建一個微信公眾號(用公眾號分割推廣信息),讓客戶訂閱后推送產品新特性的信息(客戶不用關心到底誰發的),客戶有空的時候看一下(客戶不用立等答復你),信息量太大的話就再加個同事訂閱(水平擴展客戶處理能力),有機會還可以介紹給其他潛在用戶訂閱(你也不必特意通知新客戶)。很明顯,電話這種同步消息交換的方式很容易產生瓶頸,而微信公眾號這類異步消息交換的方式客戶再多也不用擔心。
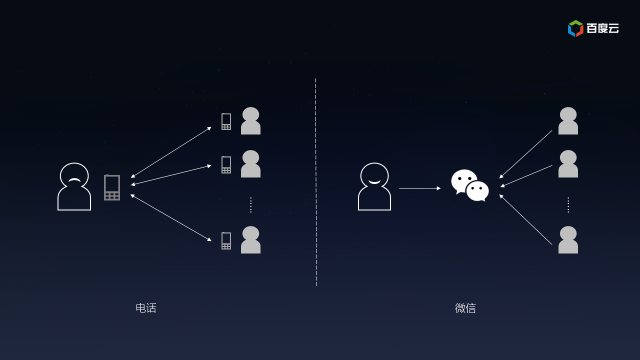
Kafka提供的Pub/Sub就是典型的異步消息交換,用戶可以為服務器日志或者物聯網設備創建不同主題(Topic),之后數據可以源源不斷地發送到各個主題,后端數據倉庫、流式分析或者全文檢索等對接特定主題,服務器或者物聯網設備是無需關心的。
同時,Kafka可以將主題劃分為多個分區(Partition),會根據分區規則選擇把消息存儲到哪個分區中,只要如果分區規則設置的合理,那么所有的消息將會被均勻的分布到不同的分區中,這樣就實現了負載均衡和水平擴展。另外,多個訂閱者可以從一個或者多個分區中同時消費數據,以支撐海量數據處理能力:
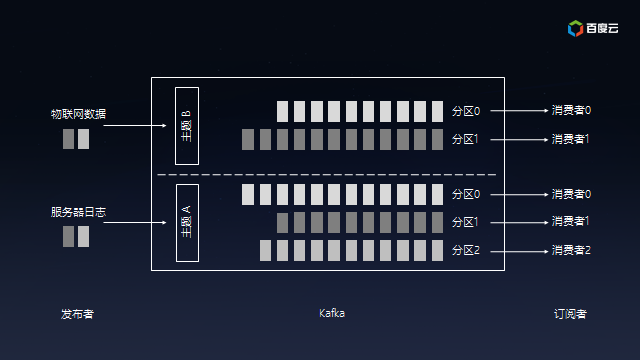
Kafka的設計也是源自生活,好比是為公路運輸,不同的起始點和目的地需要修不同高速公路(主題),高速公路上可以提供多條車道(分區),流量大的公路多修幾條車道保證暢通,流量小的公路少修幾條車道避免浪費。收費站好比消費者,車多的時候多開幾個一起收費避免堵在路上,車少的時候開幾個讓汽車并道就好了,嗯……
順便說一句,由于消息是以追加到分區中的,順序寫磁盤的效率要比隨機寫內存還要高,是Kafka高吞吐率的重要保證之一。
為了保證數據的可靠性,Kafka會給每個分區找一個節點當帶頭大哥(Leader),以及若干個節點當隨從(Follower)。消息寫入分區時,帶頭大哥除了自己復制一份外還會復制到多個隨從。如果隨從掛了,Kafka會再找一個隨從從帶頭大哥那里同步歷史消息;如果帶頭大哥掛了,隨從中會選舉出新一任的帶頭大哥,繼續笑傲江湖。
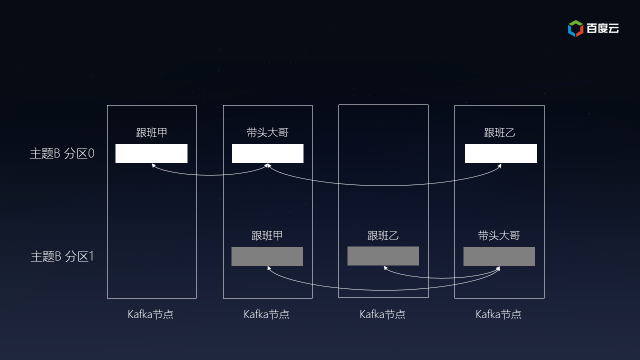
***,每個發布者發送到Kafka分區中的消息是確保順序的,訂閱者可以依賴這個承諾進行后續處理。
3 百度Kafka
Kafka優點種種,但是要把Kafka用好并不容易。開源免費是好事情,但是如何能夠保證24x7的運維保障業務穩定運行是個大問題。同時,初期業務量小的時候,閑置Kafka集群又能造成很大的浪費。
針對以上問題,百度云天算大數據平臺推出了百度Kafka服務。大體上,百度Kafka是社區版本的多租戶全托管服務,與自行運維Kafka集群相比,有以下增強:
1. 開箱即用:可以直接創建主題并使用Kafka服務,專注業務而不用花費精力去安裝、部署、配置、調試和維護集群。
2. 低廉價格:只需為使用的資源而不是虛擬主機付費,同時支持動態擴容。
3. 數據安全:支持SSL加密,保證數據在傳輸的過程中不被竊聽或者篡改。
4. 可靠耐用:獨特的服務高可用性以及數據高可靠性設計。
秉承開源開放的宗旨,百度Kafka與社區的Kafka高度兼容,遷移成本極低且不用擔心被供應商綁定。
附靚照一張:
點擊百度Kafka了解更多,具體玩法請看下集。