用KNIME進行情感分析 | 上
這個案例展示了如何利用KNIME對社交媒體數據進行情感分析。
案例中的數據抓取的是Slashdot網站首頁內容,由FundaciónBarcelona Media4提供。Slashdot是1997年成立一家非常受歡迎的科技新聞站。Slashdot網站首頁的主要內容就是網友發布的新聞以及網友在評論區展開的討論。案例使用的數據共包含約41337條評論,這些評論主要是11000多名Slashdot用戶對163篇政治報道的討論。
圖1
研究思路
我們的研究目的是區分不同用戶的情感取向。我們將通過對用戶撰寫的評論和文章的詞語進行分析、做出用戶情感取向判斷。也就是說,我們通過測量用戶(非匿名)撰寫的評論和文章時使用的正面的情感、態度、觀點詞匯的數量以及負面情感、態度和觀點詞匯的數量,來判定該用戶情感取向。用戶使用正面詞匯越多,其情感取向偏向正面,反之亦然。
此處涉及到標記詞匯極性的問題,在這里我們使用MPQA主觀詞庫來標記詞匯的極性。MPQA是一個公開的詞庫,其中包含了關于詞匯極性的數據。
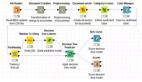
研究流程
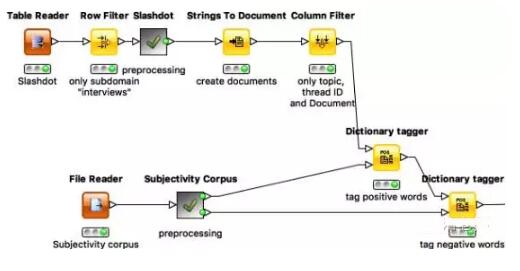
圖2
首先讀取從Slashot上獲取的數據,選取報道主題為“interviews”的評論,刪除匿名文章和匿名評論。然后將剩下的非匿名評論轉化為文檔方便之后的分析。與此同時,另外一邊首先讀取MPQA主觀詞匯,提取出詞匯和極性,并且拆分為正面詞匯和負面詞庫方便之后的標記。***,DictionaryTagger節點將每個情感標記到評論中每個詞語上。
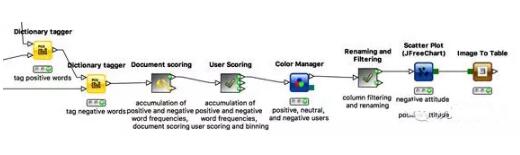
圖3
現在所有評論中的詞匯都被標記成了正面或負面,我們就可以開始計算工作。我們要計算每個評論中的正面或負面詞匯數量和每個用戶共使用的正面或負面詞匯數量。通過user id我們可以整合每個用戶不同評論中的正面詞匯和負面詞匯。在流程圖中對應的是Documentscoring和User scoring。***,我們為不同情感取向的用戶標注顏色,整理數據并制成散點圖。
結果展示
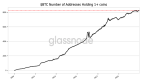
下圖是用戶使用詞匯的散點圖,縱坐標是正面詞匯,橫坐標是負面詞匯。綠色的用戶情感取向正面;灰色代表用戶情感取向既不是正面,也不是負面;紅色代表情感取向負面。
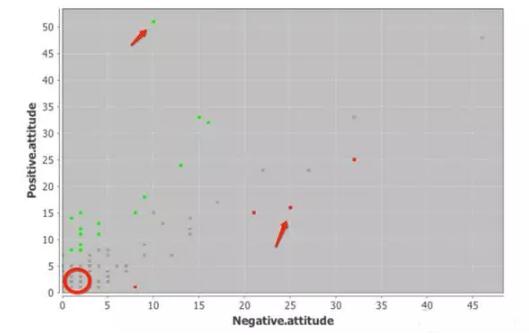
圖4
左上角紅箭頭指的用戶是Duc Ruby,他是情感取向最正面的用戶,也是經常在Slashdot上發表評論的用戶。他使用的正面詞匯數量是51,負面詞匯數量是10,我們用正面詞匯數量減去負面詞匯數量得出其情感指數是40,即情感取向最正面的用戶。
右下角紅箭頭指的用戶是whytakemine,他是情感取向最負面的用戶,也是經常在Slashdot上發表評論的用戶。他使用的正面詞匯數量是16,負面詞匯數量是25,我們用正面詞匯數量減去負面詞匯數量得出其情感指數是-9,即情感取向最負面的用戶。
左下角圓圈部分代表了大部分中立用戶,他們在Slashdot上發表的評論很少,這也是無法判斷其情感取向的可能原因。
總體而言,本次案例介紹的是如何利用社交媒體UGC內容對用戶進行情感分析。其實,情感分析只是對用戶進行了歸類,它主要還是用于后續的其他研究,如結合社會網絡,對其中的Leader和Follower做進一步分析。
點擊查看:
用KNIME進行情感分析 | 中