













Linux文件讀寫機制及優化方式
本文只討論Linux下文件的讀寫機制,不涉及不同讀取方式如read,fread,cin等的對比,這些讀取方式本質上都是調用系統api read,只是做了不同封裝。以下所有測試均使用open, read, write這一套系統api
緩存
緩存是用來減少高速設備訪問低速設備所需平均時間的組件,文件讀寫涉及到計算機內存和磁盤,內存操作速度遠遠大于磁盤,如果每次調用read,write都去直接操作磁盤,一方面速度會被限制,一方面也會降低磁盤使用壽命,因此不管是對磁盤的讀操作還是寫操作,操作系統都會將數據緩存起來
Page Cache
頁緩存(Page Cache)是位于內存和文件之間的緩沖區,它實際上也是一塊內存區域,所有的文件IO(包括網絡文件)都是直接和頁緩存交互,操作系統通過一系列的數據結構,比如inode, address_space, struct page,實現將一個文件映射到頁的級別,這些具體數據結構及之間的關系我們暫且不討論,只需知道頁緩存的存在以及它在文件IO中扮演著重要角色,很大一部分程度上,文件讀寫的優化就是對頁緩存使用的優化
Dirty Page
頁緩存對應文件中的一塊區域,如果頁緩存和對應的文件區域內容不一致,則該頁緩存叫做臟頁(Dirty Page)。對頁緩存進行修改或者新建頁緩存,只要沒有刷磁盤,都會產生臟頁
查看頁緩存大小
linux上有兩種方式查看頁緩存大小,一種是free命令
- $ free
- total used free shared buffers cached
- Mem: 20470840 1973416 18497424 164 270208 1202864
- -/+ buffers/cache: 500344 19970496
- Swap: 0 0 0
cached那一列就是頁緩存大小,單位Byte
另一種是直接查看/proc/meminfo,這里我們只關注兩個字段
- Cached: 1202872 kB
- Dirty: 52 kB
Cached是頁緩存大小,Dirty是臟頁大小
臟頁回寫參數
Linux有一些參數可以改變操作系統對臟頁的回寫行為
- $ sysctl -a 2>/dev/null | grep dirty
- vm.dirty_background_ratio = 10
- vm.dirty_background_bytes = 0
- vm.dirty_ratio = 20
- vm.dirty_bytes = 0
- vm.dirty_writeback_centisecs = 500
- vm.dirty_expire_centisecs = 3000
vm.dirty_background_ratio是內存可以填充臟頁的百分比,當臟頁總大小達到這個比例后,系統后臺進程就會開始將臟頁刷磁盤(vm.dirty_background_bytes類似,只不過是通過字節數來設置)
vm.dirty_ratio是絕對的臟數據限制,內存里的臟數據百分比不能超過這個值。如果臟數據超過這個數量,新的IO請求將會被阻擋,直到臟數據被寫進磁盤
vm.dirty_writeback_centisecs指定多長時間做一次臟數據寫回操作,單位為百分之一秒
vm.dirty_expire_centisecs指定臟數據能存活的時間,單位為百分之一秒,比如這里設置為30秒,在操作系統進行寫回操作時,如果臟數據在內存中超過30秒時,就會被寫回磁盤
這些參數可以通過 sudo sysctl -w vm.dirty_background_ratio=5 這樣的命令來修改,需要root權限,也可以在root用戶下執行 echo 5 > /proc/sys/vm/dirty_background_ratio 來修改
文件讀寫流程
在有了頁緩存和臟頁的概念后,我們再來看文件的讀寫流程
讀文件
- 用戶發起read操作
- 操作系統查找頁緩存
- 若未***,則產生缺頁異常,然后創建頁緩存,并從磁盤讀取相應頁填充頁緩存
- 若***,則直接從頁緩存返回要讀取的內容
- 用戶read調用完成
寫文件
- 用戶發起write操作
- 操作系統查找頁緩存
- 若未***,則產生缺頁異常,然后創建頁緩存,將用戶傳入的內容寫入頁緩存
- 若***,則直接將用戶傳入的內容寫入頁緩存
- 用戶write調用完成
- 頁被修改后成為臟頁,操作系統有兩種機制將臟頁寫回磁盤
- 用戶手動調用fsync()
- 由pdflush進程定時將臟頁寫回磁盤
頁緩存和磁盤文件是有對應關系的,這種關系由操作系統維護,對頁緩存的讀寫操作是在內核態完成,對用戶來說是透明的
文件讀寫的優化思路
不同的優化方案適應于不同的使用場景,比如文件大小,讀寫頻次等,這里我們不考慮修改系統參數的方案,修改系統參數總是有得有失,需要選擇一個平衡點,這和業務相關度太高,比如是否要求數據的強一致性,是否容忍數據丟失等等。優化的思路有以下兩個考慮點
1.***化利用頁緩存
2.減少系統api調用次數
***點很容易理解,盡量讓每次IO操作都***頁緩存,這比操作磁盤會快很多,第二點提到的系統api主要是read和write,由于系統調用會從用戶態進入內核態,并且有些還伴隨這內存數據的拷貝,因此在有些場景下減少系統調用也會提高性能
readahead
readahead是一種非阻塞的系統調用,它會觸發操作系統將文件內容預讀到頁緩存中,并且立馬返回,函數原型如下
- ssize_t readahead(int fd, off64_t offset, size_t count);
在通常情況下,調用readahead后立馬調用read并不會提高讀取速度,我們通常在批量讀取或在讀取之前一段時間調用readahead,假設如下場景,我們需要連續讀取1000個1M的文件,有如下兩個方案,偽代碼如下
直接調用read函數
- char* buf = (char*)malloc(10*1024*1024);
- for (int i = 0; i < 1000; ++i)
- {
- int fd = open_file();
- int size = stat_file_size();
- read(fd, buf, size);
- // do something with buf
- close(fd);
- }
先批量調用readahead再調用read
- int* fds = (int*)malloc(sizeof(int)*1000);
- int* fd_size = (int*)malloc(sizeof(int)*1000);
- for (int i = 0; i < 1000; ++i)
- {
- int fd = open_file();
- int size = stat_file_size();
- readahead(fd, 0, size);
- fds[i] = fd;
- fd_size[i] = size;
- }
- char* buf = (char*)malloc(10*1024*1024);
- for (int i = 0; i < 1000; ++i)
- {
- read(fds[i], buf, fd_size[i]);
- // do something with buf
- close(fds[i]);
- }
感興趣的可以寫代碼實際測試一下,需要注意的是在測試前必須先回寫臟頁和清空頁緩存,執行如下命令
- sync && sudo sysctl -w vm.drop_caches=3
可通過查看/proc/meminfo中的Cached及Dirty項確認是否生效
通過測試發現,第二種方法比***種讀取速度大約提高10%-20%,這種場景下是批量執行readahead后立馬執行read,優化空間有限,如果有一種場景可以在read之前一段時間調用readahead,那將大大提高read本身的讀取速度
這種方案實際上是利用了操作系統的頁緩存,即提前觸發操作系統將文件讀取到頁緩存,并且操作系統對缺頁處理、緩存***、緩存淘汰都由一套完善的機制,雖然用戶也可以針對自己的數據做緩存管理,但和直接使用頁緩存比并沒有多大差別,而且會增加維護代價
mmap
mmap是一種內存映射文件的方法,即將一個文件或者其它對象映射到進程的地址空間,實現文件磁盤地址和進程虛擬地址空間中一段虛擬地址的一一對映關系,函數原型如下
- void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
實現這樣的映射關系后,進程就可以采用指針的方式讀寫操作這一段內存,而系統會自動回寫臟頁面到對應的文件磁盤上,即完成了對文件的操作而不必再調用read,write等系統調用函數。如下圖所示
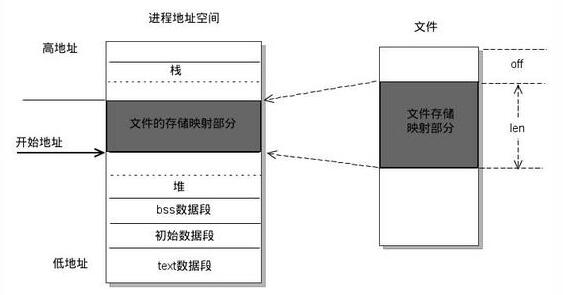
mmap除了可以減少read,write等系統調用以外,還可以減少內存的拷貝次數,比如在read調用時,一個完整的流程是操作系統讀磁盤文件到頁緩存,再從頁緩存將數據拷貝到read傳遞的buffer里,而如果使用mmap之后,操作系統只需要將磁盤讀到頁緩存,然后用戶就可以直接通過指針的方式操作mmap映射的內存,減少了從內核態到用戶態的數據拷貝
mmap適合于對同一塊區域頻繁讀寫的情況,比如一個64M的文件存儲了一些索引信息,我們需要頻繁修改并持久化到磁盤,這樣可以將文件通過mmap映射到用戶虛擬內存,然后通過指針的方式修改內存區域,由操作系統自動將修改的部分刷回磁盤,也可以自己調用msync手動刷磁盤。


















