numpy:python數據領域的功臣

前言
numpy對python的意義非凡,在數據分析與機器學習領域為python立下了汗馬功勞。現在用python搞數據分析或機器學習經常使用的pandas、matplotlib、sklearn等庫,都需要基于numpy構建。毫不夸張地說,沒有numpy,python今天在數據分析與機器學習領域只能是捉襟見肘。
什么是一門好的數據分析語言
數據分析面向的數據大多數是二維表。一門好的數據分析語言,首先需要能夠直接有個數據結構存下這個二維表,然后要配上一套成熟的類SQL的數據操作接口,***要有一套好用的可視化工具。R語言就是一個極好的典范:用內置的data.frame結構做數據的存儲;data.frame本身提供足夠強大的數據操作能力,另有dplyr、tidyr、data.table、plyr、reshape2等庫提供更好用更高效的數據操作能力;在繪圖上,除了基本的plot功能外,還提供了ggplot2這樣一套優雅的繪圖語言,還通過htmlwidget庫與javascript各種繪圖庫建立了緊密的聯系,讓可視化的動態展示效果更進一步。Excel也是一個極好的例子,有單元格這種靈活的結構為數據存儲做支撐,有大量的函數實現靈活的操作,也有強大的繪圖系統。
python目前在數據分析領域也已經具備了相當可觀的能力,包括pandas庫實現的DataFrame結構,pandas本身提供的數據操作能力,matplotlib提供的數據可視化能力,而這一切都離不開numpy庫。
什么是一門好的機器學習語言
一般來講,一門好的機器學習語言在數據分析上也一定很吃得開,因為數據分析往往是機器學習的基礎。但是機器學習的要求更高,因為在模型訓練階段往往需要較為復雜的參數估計運算,因此語言需要具備較強的科學計算能力。科學計算能力,最核心的就是矩陣運算能力。關于矩陣運算能力,這篇文章對各種語言有很好的比較。
如果沒有numpy,python內部只能用list或array來表示矩陣。假如用list來表示[1,2,3],由于list的元素可以是任何對象,因此list中所保存的是對象的指針,所以需要有3個指針和三個整數對象,比較浪費內存和CPU計算時間。python的array和list不同,它直接保存數值,和C語言的一維數組比較類似,但是不支持多維,表達形式很簡陋,寫科學計算的算法很難受。numpy彌補了這些不足,其提供的ndarray是存儲單一數據類型的多維數組,且采用預編譯好的C語言代碼,性能上的表現也十分不錯。
python***的機器學習庫sklearn構建在numpy之上,提供了各種標準機器學習模型的訓練與預測接口,其中模型訓練接口的內部實現是基于numpy庫實現的。比如很常見的線性回歸模型,參數估計調用的是numpy.linalg.lstsq函數。
numpy的核心結構:ndarray
以下內容摘錄自用Python做科學計算
- a = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32)
ndarray是numpy的核心數據結構。我們來看一下ndarray如何在內存中儲存的:關于數組的描述信息保存在一個數據結構中,這個結構引用兩個對象,一塊用于保存數據的存儲區域和一個用于描述元素類型的dtype對象。
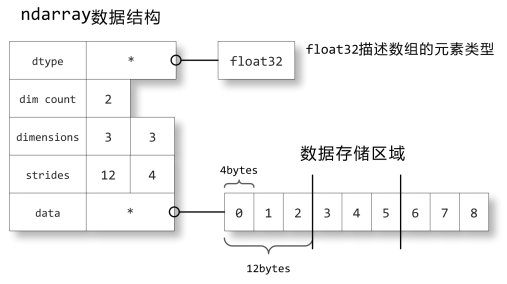
數據存儲區域保存著數組中所有元素的二進制數據,dtype對象則知道如何將元素的二進制數據轉換為可用的值。數組的維數、大小等信息都保存在ndarray數組對象的數據結構中。
strides中保存的是當每個軸的下標增加1時,數據存儲區中的指針所增加的字節數。例如圖中的strides為12,4,即第0軸的下標增加1時,數據的地址增加12個字節:即a[1,0]的地址比a[0,0]的地址要高12個字節,正好是3個單精度浮點數的總字節數;第1軸下標增加1時,數據的地址增加4個字節,正好是單精度浮點數的字節數。
以下內容總結自Numpy官方文檔Numpy basics
關于ndarray的索引方式,有以下幾個重點需要記住:
- 雖然x[0,2] = x0,但是前者效率比后者高,因為后者在應用***個索引后需要先創建一個temporary array,然后再應用第二個索引,***找到目標值。
- 分片操作不會引發copy操作,而是創建原ndarray的view;他們所指向的內存是同一片區域,無論是修改原ndarray還是修改view,都會同時改變二者的值。
- index array和boolean index返回的是copy,不是view。
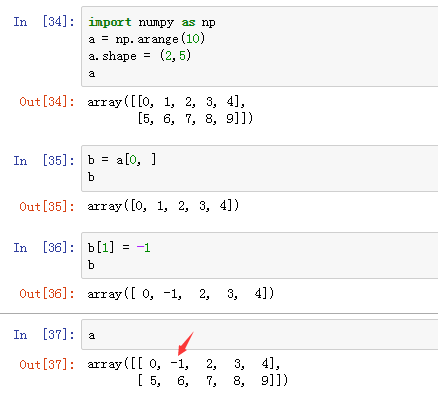
關于上面列舉的分片操作不會引發copy操作,我們來進一步探討一下。先看一下numpy的例子:
再來看一下R的例子:
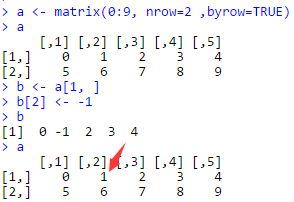
可以看到numpy和R在矩陣的分片操作有不同的設計理念:在R里分片操作會引起數據的復制,在numpy里不會。事實上,R的設計理念很多時候可以用一句話來概括:copy on modify,一旦對數據有修改就會引起內存上的復制操作,這個操作要花不少時間,因此經常會聽到人們抱怨R費內存且速度慢。所以,我們可以看到numpy在處理這件事情上明顯要用心很多,根據場景設計了不同的策略,不是簡單地采用R的一刀切方式。當然,這也帶來了一些學習成本,需要對numpy足夠熟悉才能避免踩坑。R社區里對copy on modify的哲學也有詬病并在努力改變,比如同是data.frame操作庫的data.table和dplyr,data.table性能比dplyr高很多,部分原因也是data.table規避了copy on modify的方式。
Structured Array
根據numpy的官方文檔,定義結構化數組有四種方式。本文采用字典方法,通過定義一個dtype對象實現,需要指定的鍵值有names和formats。
- persontype = np.dtype({
- 'names': ['name', 'age', 'weight'],
- 'formats': ['S32', 'i', 'f']
- })
- a = np.array([("Zhang", 32, 75.5), ("Wang", 24, 65.2)], dtype=persontype)
我們用IPython的計時函數看一下提取數據的效率:
- %timeit a[1]
- %timeit a['name']
- %timeit a[1]['name']
- %timeit a['name'][1]
輸出結果如下:
- The slowest run took 46.83 times longer than the fastest. This could mean that an intermediate result is being cached.
- 1000000 loops, best of 3: 153 ns per loop
- The slowest run took 34.34 times longer than the fastest. This could mean that an intermediate result is being cached.
- 10000000 loops, best of 3: 174 ns per loop
- The slowest run took 13.00 times longer than the fastest. This could mean that an intermediate result is being cached.
- 1000000 loops, best of 3: 1.08 µs per loop
- The slowest run took 9.84 times longer than the fastest. This could mean that an intermediate result is being cached.
- 1000000 loops, best of 3: 412 ns per loop
從上面的結果,我們發現,獲取相同的數據有多種操作,不同的操作性能差別很大。我做了一個推測,純粹是瞎猜:numpy在建立結構化數組時,將整個結構體連續存儲在一起,即按行存儲,因此a[1]的速度最快;但是為了保證提取列的效率,對a['name']建立了索引,因此a['name']的效率也很高;但是這個索引只對整個a起作用,如果輸入只有a的一部分,仍然需要遍歷整個a,去提取出對應的數據,因此a[1]['name']比a['name'][1]的效率差很多。
實例
基于numpy過濾抖動與填補
時間序列數據經常會發現兩種情況:一種是抖得特別厲害,說明數據不穩定不可信,支撐這個結果的數據量不夠;另一種是一動不動的一條直線,這往往是算法填充出來的默認值,不是實際值。這些數據對于挖掘來說是噪音,應該過濾掉。我們使用numpy來完成這個任務。抖動的特點是頻繁跳動,即一階差分有很多值絕對值比0大很多,那么我們將這些跳動的點抓出來,統計下這些點之間的區間長度,如果區間長度過小,認為是抖動過多。填補的特點是數值長期不變,即一階差分有很多值為0,那么我們統計一下連續為0的區間長度分布,如果區間長度過長,比如連續填補了1小時,或者出現多個填補了30分鐘的區間,我們認為是填補過多。
我們需要對跳點進行定義:一階差分的絕對值超過dev_thresh,一階差分/max(基準1,基準2)的絕對值超過ratio_thresh。
- def jump(speed_array, dev_thresh, ratio_thresh):
- diff_array = np.diff(speed_array, axis=0)
- diff_array = diff_array.astype(np.float64)
- ratio_array = diff_array/np.maxium(speed_array[:-1], speed_array[1:])
- ret_array = np.zeros(diff_array.size, dtype=np.int8)
- for i in range(diff_array.size):
- if abs(diff_array[i]) > diff_thresh and abs(ratio_array[i]) > ratio_thresh:
- ret_array[i] = 1
- return ret_array
- def interval(jump_array):
- jump_idx = np.array([0] + [i for i,x in enumerate(jump_array) if x != 0] + [jump_array.size])
- interval_size = np.diff(jump_idx)
- return interval_size
- def is_jump_too_much(interval_size):
- flag = 0
- if np.mean(interval_size) <= 10 or np.max(interval_size) <= 30:
- flag = 1
- return flag
- def is_fill_too_much(interval_size):
- flag = 0
- bin_array = np.bincount(interval_size)
- if ( len(bin_array) >= 30 or
- ( len(bin_array) >= 11 and np.sum(bin_array[10:]) >= 4 ) or
- ( len(bin_array) >= 7 and np.sum(bin_array[6:]) >= 20 )
- ):
- flag = 1
- return flag
基于numpy的局部趨勢擬合
用線性回歸可以得到時間序列的趨勢。
- def get_ts_trend(ts_array):
- x = np.arange(0, len(ts_array), 1)
- y = ts_array
- A = np.vstack([x, np.ones(len(x))]).T
- m, c = np.linalg.lstsq(A, y)[0]
- return m
堵點判別
交通數據比較復雜,不純粹是時間序列問題,而是時空數據,需要同時考慮時間關系和空間關系。本節介紹一個經典特征的提取:堵點判別。
假設我們空間上有5個link,上游2個,自身1個,下游2個;觀察5個時間點的擁堵狀態。判斷當前link是不是堵點——即自身是拓撲中***個發生擁堵的點;發生擁堵后,擁堵是擴散的。
- def detect_congest_point(congest_array):
- first_congest_flag = False
- disperse_congest_flag = True
- idx = np.where(congest_array == 1)
- if idx[1][0] == congest_array.shape[1]/2:
- first_congest_flag = True
- disperse_dict = {}
- for k in range(len(idx[0])):
- if disperse_dict.has_key(idx[0][k]):
- disperse_dict[idx[0][k]].append(idx[1][k])
- else:
- disperse_dict[idx[0][k]] = [idx[1][k]]
- sorted_disperse_list = sorted(disperse_dict.iteritems(), key=lambda d:d[0])
- for i in range(1, len(sorted_disperse_list)):
- if not set(sorted_disperse_list[i-1][1]) <= set(sorted_disperse_list[i][1]):
- disperse_congest_flag = False
- return first_congest_flag and disperse_congest_flag
關于作者:丹追兵:數據分析師一枚,編程語言python和R,使用Spark、Hadoop、Storm、ODPS。本文出自丹追兵的pytrafficR專欄,轉載請注明作者與出處:https://segmentfault.com/blog...