海量數據實時更新太慢?Lambda架構大法好!
本文將主要介紹如何利用Lambda架構來跟蹤數據實時更新的項目實現,以一個新聞服務功能為例。
當前股票市場的交易者可以了解豐富的股票交易信息。從金融新聞到傳統的報紙和雜志再到博客和社交媒體,匯聚著海量的數據,遠比股票交易者想關注的股 票信息要大得多,這就需要為股票交易者提供信息的有效過濾。這里將開發一個新聞服務功能給股票證券投資交易者使用,并為股票交易者提供個性化新聞。
這個新聞服務就叫"自動獲取金融新聞",輸入各個數據源的金融新聞,也同時輸入用戶實時股票交易信息。不管何時,在股票交易者所擁有資產證券中占比 較大的公司,它們的新聞一到達,將會顯示到股票交易者的儀表板上。隨著大量股票交易者進行交易,相應的交易信息會發送過來,所以希望擁有一個大數據系統來 存儲所有交易者的歷史交易信息作為真實數據源,然而,處理海量數據會非常慢以至于不能進行實時的數據更新。為了達到實時跟蹤和維持數據結果為***這兩個要求,可以采用Lambda架構來實現。
Lambda架構優勢
在傳統SQL系統,更新一個表只是對已存在字段的值進行更改,這在少量的服務器上的數據庫工作的很好,可以水平擴展到從庫或者備份庫。但是當數據庫 擴展到大量數據服務器上時,硬件崩潰等情況下恢復數據到失敗點就比較困難和耗時,而且由于歷史不在數據庫中,僅僅存在log日志,數據崩潰將導致一些不可見的數據錯誤,即臟數據。
而相對應地,一個分布式、多副本消息隊列的大數據系統可以保證數據一旦進入系統就不會丟失,即使在硬件或者網絡失敗的情況下。存儲更新的所有歷史可 以重建真實的數據源,并能保證每次批處理之后結果正確,然而,為了在實時數據更新后得到***完整的數據集,需要重新處理整個歷史數據集,將會耗費太長的時 間。為了解決這個問題,可以在Lambda架構中增加一個實時組件,此組件只存儲數據更新的當前值,可以保證快速實時得到結果,工作過程類似于傳統的 SQL系統。實時處理層的臟數據將會被后續批處理覆蓋掉,這個高可用、最終一致性的系統可以實現準確的結果。當前值的任何錯誤,實時處理層的報告,硬件或 者網絡錯誤,數據崩潰,或者軟件Bug等將會在下一次批處理時自動修復。
自動獲取金融新聞項目的數據管道
整個數據管道流動如圖1:
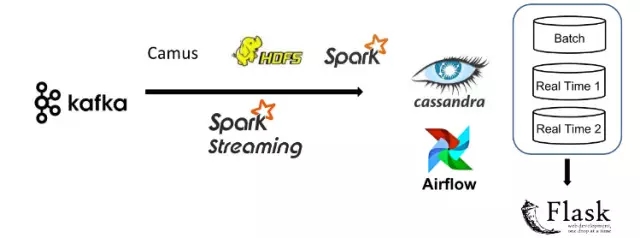
圖1
輸入數據格式為JSON,主要來自綜合交易信息和Twitter新聞。JSON格式的消息會push到Kafka,并被批處理層(batch layer)和實時處理層(real-time layer)消費。使用Kafka作為數據管道的輸入起點,是因為Kafka可以保證即使在硬件或者網絡失敗的情況下,消息也會被傳輸到整個系統。
在批處理層,Camus(Linkin開源的項目,現已更名為Gobblin)消費所有Kafka過來的消息并保存到HDFS上,然后Spark處理所有的交易歷史計算每個股票交易者持有的股票準確數量,對應的結果會寫入Cassandra數據庫。
在流式處理層,Spark Streaming實時消費Kafka消息,但并不像Storm那樣完全實時,Spark Streaming可以達到500ms的micro-batch數據流處理。Spark Streaming可以重用批處理層的Spark代碼,并且micro-batch數據流處理可以得到足夠小的延遲。
批處理層和實時處理層的結果都會寫入到Cassandra數據庫,并通過Flask提供一個web接口服務。隨著海量交易數據寫入系統,Cassandra數據庫的快速寫入能力基本可以滿足。
如何調度實時處理層和批處理層的結果
當***的消息進入大數據系統,web接口提供的結果服務總能保持***,綜合批處理層和實時層的處理結果。用一個例子來展示如何簡單的使用批處理結果和實時處理結果。
從下圖2看到,有三個數據庫表:一個存儲批處理結果(圖2中Batch表);一個存儲自上次批處理完成時間點到當前時間的實時交易數據,即增量數據(圖2中Real Time 2表);另外一個存儲***數據,即狀態表(圖2中高亮的Real Time 1表)。
任何軟件、硬件或者網絡問題引起批處理結果異常,都通過單獨一個數據庫表記錄數據增量,并在批處理成功后更新為對應的批處理結果數來保證最終數據一致性。
在這個例子中,假設***輪批處理起始時間點為t0,一個交易者做了一筆交易后獲得了3M公司的5000股股票。

圖2
在t0時間點,批處理開始,處理完之后***結果存儲在Real Time 1表,當前值為5000股。

圖3
在批處理過程中,交易者賣掉3M公司1000股股票,Real Time 1表更新數據值為4000股,同時Real Time 2表存儲從t0到當前的增量-1000股,如圖4所示。
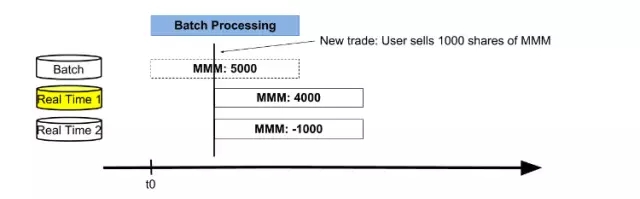
圖4
當批處理結束,三個表的值分別為5000,4000,-1000。這時,交換active數據庫表為Real Time 2表,進行合并批處理結果和實時結果獲得***結果值。然后重置Real Time 1表為0,后續用來存儲從t1時間點開始的增量數據。接下來新的一輪以存儲***數據的Real Time 2表為起點,循環前面的過程。
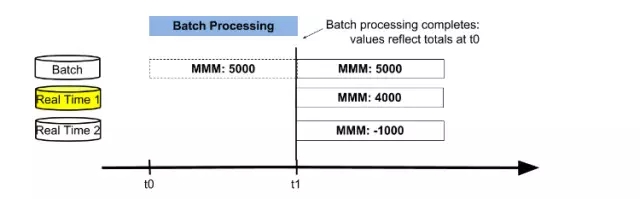
圖5
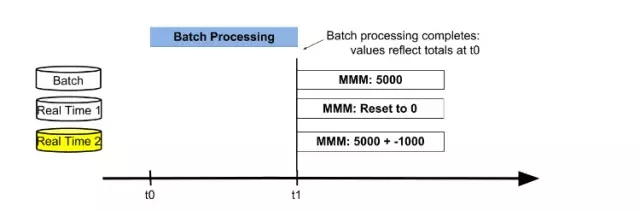
圖6
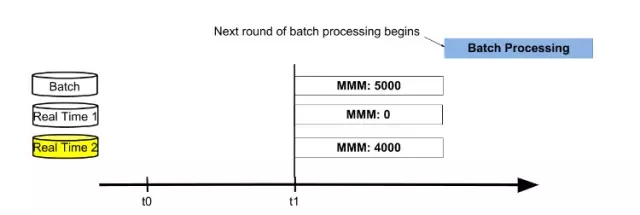
圖7
以上每步處理過程完全成功并寫入數據庫,可以保證展示給交易者的數據準確性。數據集 處理時間取決于數據集大小,處理任務的計劃按序處理而不是按自然天時間。在一個系統中需要工作流支持復雜處理、多任務依賴和資源共享。這里采用 Airbnb的項目Airflow,可以調度程序和監控工作流。Airflow把task和上游各種依賴構建成一個有向無環圖(DAG),基于 Python實現,可以把多個任務寫成Bash腳本,Bash命令能直接調用任何模塊,并且Bash腳本可以被Airflow使用,這樣使得 Airflow易操作。Airflow編程接口比基于XML配置的調度系統Oozie簡單;Airflow的Bash腳本編碼量比Luigi要少很多,Luigi的每個job都是一個python工程。每步合并實時和批量數據的job運行都是前一步成功完成退出后。
***簡單總結一下,Lambda架構涉及批量處理層和實時處理層處理歷史數據以及實時更新的數據。 為了Lambda架構的實現切實可行,數據處理要設計成批處理層和實時處理層結合。本項目中,有一個“備用”數據庫表專門用來存儲輸入的總數,而不從批處 理層讀取數據,并允許對批處理層和實時處理層的結果進行簡單的聚合。以上就是用Lambda架構實現的一個高可用、高數據最終一致性的系統。