從AWS遷移到Facebook基礎(chǔ)架構(gòu)時Instagram越過的坎兒
本文介紹了Instagram從AWS遷移到Facebook基礎(chǔ)架構(gòu)的過程中面臨的由多數(shù)據(jù)中心帶來的挑戰(zhàn)和解決方法。
在2013年,大約是我們加入Facebook一周年后,每個月有2億人使用Instagram而且我們存儲了200億照片。毫不猶豫的,我們開始了“Instagration”——從AWS服務(wù)器移動到Facebook的基礎(chǔ)架構(gòu)。
兩年后,Instagram已經(jīng)成長為月活4億有400億照片和視頻的社區(qū),每秒服務(wù)超過100萬請求。為了保持對這種增長的支持和確保社區(qū)在Instagram上有一個可靠的體驗,我們決定在地理上擴(kuò)展我們的基礎(chǔ)架構(gòu)。
本文將討論為什么我們要將基礎(chǔ)架構(gòu)從一個數(shù)據(jù)中心擴(kuò)展到三個,和在擴(kuò)展中遇到的一些技術(shù)挑戰(zhàn)。
動機(jī)
Mike Krieger, Instagram的聯(lián)合創(chuàng)始人和CTO,近期寫了一篇文章,文章中提到了一個故事,大約在2012年的時候,弗吉尼亞州的一場颶風(fēng)癱瘓了將近一半的(服務(wù)器)實例。
在接下來的36小時里,這個小團(tuán)隊重建了幾乎我們?nèi)康幕A(chǔ)架構(gòu),這種體驗是他們永遠(yuǎn)不想重復(fù)的。
像這樣的自然災(zāi)害有可能對數(shù)據(jù)中心造成臨時的和***的傷害——我們需要保證在用戶體驗上有最小的損失。
其他的在地理上擴(kuò)容的動機(jī)包括:
區(qū)域故障的恢復(fù): 比自然災(zāi)害更加常見的是網(wǎng)絡(luò)短線、電力問題,等等。例如在我們擴(kuò)展我們的服務(wù)到俄勒岡州不久,我們的一個基礎(chǔ)構(gòu)件,包括memecache和異步層服務(wù)器,被關(guān)機(jī)了,導(dǎo)致了用戶請求的大規(guī)模一場。
在我們的新架構(gòu)下,我們能夠?qū)⒘髁繌脑搮^(qū)域轉(zhuǎn)移走,以減輕我們在從電力故障中恢復(fù)時的問題。
彈性容量擴(kuò)展: Facebook有不少數(shù)據(jù)中心。當(dāng)我們的基礎(chǔ)架構(gòu)準(zhǔn)備好擴(kuò)展到一個區(qū)域甚至當(dāng)網(wǎng)絡(luò)上有不小的延遲時,可以非常容易的將Instagram的容量擴(kuò)展到所有可用的容量中。這幫助我們快速決定為用戶準(zhǔn)備好新的功能而不用Scramble for基礎(chǔ)架構(gòu)資源來支持他們。
從一到二
所以我們怎么開始這件事情的? 首先讓我們來看一下Instagram的整體基礎(chǔ)架構(gòu)棧。
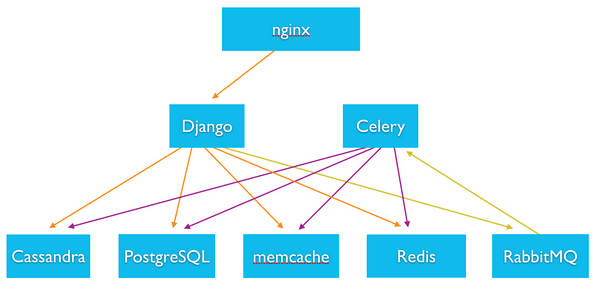
擴(kuò)展到多數(shù)據(jù)中心的關(guān)鍵是區(qū)分全局?jǐn)?shù)據(jù)和局部數(shù)據(jù)。全局?jǐn)?shù)據(jù)需要在不同的數(shù)據(jù)中心間復(fù)制,而局部數(shù)據(jù)在每個區(qū)域可能不同(例如web服務(wù)器創(chuàng)建的異步任務(wù)應(yīng)該只在所在的區(qū)域被看到)。
下一個要考慮的是硬件資源。這個可以粗略的氛圍三中:存儲,計算和緩存。
存儲
Instagram主要是用兩種后端數(shù)據(jù)庫系統(tǒng):PostgreSQL和Cassandra。他們都有成熟的復(fù)制框架來很好的作為全局的一致數(shù)據(jù)存儲。
全局?jǐn)?shù)據(jù)整齊地映射到這些服務(wù)器上存儲的數(shù)據(jù)。目標(biāo)是在不同的數(shù)據(jù)中心間保持這些數(shù)據(jù)的最終一致性,每一個區(qū)域有一個讀復(fù)制,來避免web服務(wù)器的跨數(shù)據(jù)中心讀。
但是,對PostgreSQL的寫入仍然夸數(shù)據(jù)中心,因為他們總是要寫到主服務(wù)集群上。
CPU處理
Web服務(wù)器,異步服務(wù)器都是無狀態(tài)的容易分布的計算資源,并且只需要訪問本地數(shù)據(jù)。Web服務(wù)器可以創(chuàng)建異步工作,這些異步工作被異步消息代理加入隊列,然后被異步服務(wù)器消費,全都在一個區(qū)域。
緩存
緩存層是web服務(wù)器最常訪問的層,并且它們需要在同一個數(shù)據(jù)中心中來避免用戶請求的延遲。這意味著對一個數(shù)據(jù)中心緩存的更新不會反映到另一個數(shù)據(jù)中心中,因此對遷移到多數(shù)據(jù)中心創(chuàng)建了一個挑戰(zhàn)。
想象一個用戶在你的***發(fā)表的照片上評論。在一個數(shù)據(jù)中心的情況下,服務(wù)這個請求的web服務(wù)器可以僅僅在緩存中更新這個新評論。一個關(guān)注者會從同一個緩存中看到這個新評論。
然而在多數(shù)據(jù)中心的情景下,如果評論者和關(guān)注者被不同的區(qū)域服務(wù),關(guān)注者的區(qū)域緩存將不會被更新,這個用戶就不能看到評論。
我們的解決方法是使用PgQ, 增強(qiáng)它使得插入緩存失效事件到被修改的數(shù)據(jù)庫中。
在主節(jié)點:
- Web服務(wù)器插入一條評論到PostgreSQL數(shù)據(jù)庫中
- Web服務(wù)器在同一個數(shù)據(jù)庫中插入一個緩存失效條目
在從節(jié)點:
- 復(fù)制主數(shù)據(jù)庫,包括新插入的評論和緩存失效條目
- 緩存失效處理讀取緩存失效條目并且使區(qū)域緩存失效
- Django集群從數(shù)據(jù)庫中讀到新插入的評論并且重新填充緩存
這解決了緩存一致性問題。另一方面,相對于單區(qū)域的例子,django服務(wù)器直接更新緩存而不重新讀區(qū)數(shù)據(jù)庫,多區(qū)域時會增加數(shù)據(jù)庫的讀負(fù)載。
為了減輕這個問題,我們使用了兩種辦法:1) 通過冗余計數(shù)器減少每一個讀需要的計算資源;2) 通過緩存租約減少讀的數(shù)量。
冗余計數(shù)器
最常見的緩存鍵是計數(shù)器。例如,我們使用一個計數(shù)器來確定喜歡Justin Bieber的一個具體的帖子的人數(shù)。
當(dāng)只有一個區(qū)域時,我們可以從web服務(wù)器增加memcache的計數(shù)器,所以避免一個“select count(*)”的數(shù)據(jù)庫調(diào)用,這回節(jié)省幾百毫秒。
但是在有兩個區(qū)域和PgQ失效時,每一個新的喜歡對計數(shù)器創(chuàng)建了一個緩存失效事件。這會創(chuàng)建大量的“select count(*)”,尤其是在熱點對象上。
為了減少這些操作每一個需要的資源,我們對這個帖子的喜歡數(shù)量的計數(shù)器進(jìn)行冗余(譯注:即在post的字段中加上likes的計數(shù)器,雖然是反范式的但帶來了性能提升)。當(dāng)一個新的喜歡來到時,這個計數(shù)在數(shù)據(jù)庫中增加,因此,每個對這個計數(shù)的讀會變成一個更有效的簡單的select。
另一個在存儲喜歡這個帖子的人的同一個數(shù)據(jù)庫中進(jìn)行冗余計數(shù)的好處是,更新可以被包含在一個事務(wù)中,似的這個更新總是原子的和一致的。雖然在改變前,緩存的計數(shù)器可能和數(shù)據(jù)庫中存儲的不一致,因為超時或重試等等原因。
Memcache租約
在上面來自Justin Bieber的新的帖子的例子中,在這個帖子的最初的幾分鐘,瀏覽和點贊的都會達(dá)到峰值。對每一個贊,計數(shù)器都從緩存中刪去。非常常見的情況是web服務(wù)器都嘗試從緩存中獲取同一個
計數(shù)器,但是會有“緩存未***”發(fā)生。如果所有的這些web服務(wù)器都去數(shù)據(jù)庫服務(wù)器來獲取數(shù)據(jù),將會導(dǎo)致驚群問題。
我們使用memcache租約機(jī)制來解決這個問題。它像這樣工作:
- Web服務(wù)器發(fā)起一個“租約get”請求,不是通常的“get”請求到memcache服務(wù)器。
- Memcache服務(wù)器在***時返回***的緩存值。在這種情況下和一個通常的“get”請求沒有區(qū)別。
- 如果memcache服務(wù)器找不到對應(yīng)的key,它在n秒內(nèi)返回一個“***未***”給這段時間內(nèi)請求的一個web服務(wù)器;這段時間內(nèi)任何其他的“租約get”請求會得到一個“熱未***”。在“熱未***”的情況下,這個key最近從cache中刪除,它會返回過期的值。如果這個緩存的key在n秒內(nèi)沒有被挺沖,它再次對一個“租約get”請求返回“***未***”。
- 當(dāng)一個web server收到“***未***”時,它進(jìn)到數(shù)據(jù)庫中獲取數(shù)據(jù)并且填充緩存。
- 當(dāng)一個web server收到“熱未***”和一個過期的值時,它可以使用這個值。如果它收到一個沒有值的“熱未***”,它可以選擇等待緩存被“***未***”的web server填充。
總之,在以上的實現(xiàn)中,我們可以通過減少訪問數(shù)據(jù)庫的次數(shù)和每次訪問的資源來減少數(shù)據(jù)庫的負(fù)載。
這也提高了我們后端在一些熱計數(shù)器調(diào)出緩存時的可靠性,這種情形在Instagram的早期并非不常見。每次這種情形發(fā)生都會使得工程師趕忙手動修復(fù)緩存。在這樣的改變下,這些事故成為了老工程師的回憶。
從10ms延遲到60ms
目前為止,我們主要關(guān)注了當(dāng)緩存變得有區(qū)域性之后的緩存一致性。數(shù)據(jù)中心之間的網(wǎng)絡(luò)延遲是另一個影響很多設(shè)計的挑戰(zhàn)。數(shù)據(jù)中心之間,一個60ms的網(wǎng)絡(luò)延遲可以導(dǎo)致數(shù)據(jù)庫復(fù)制的問題和web server更新數(shù)據(jù)庫的問題。我們需要解決以下問題來支持無縫擴(kuò)展:
PostgreSQL 讀復(fù)制落后
當(dāng)一個Postgres的主節(jié)點寫的時候,它生成增量日至。寫請求來的越快,這些日志生成的越頻繁。主節(jié)點們?yōu)閺墓?jié)點偶爾的需求存儲最近的日志文件,但是它們歸檔所有的日志到存儲中,來保證日志被保存
并且可以被任何需要更早的主節(jié)點保留的數(shù)據(jù)的從節(jié)點的訪問。這樣,主節(jié)點不會耗盡硬盤空間。
當(dāng)我們創(chuàng)建一個新的讀復(fù)制時,讀復(fù)制開始讀主節(jié)點的一個快照。一旦完成,它需要應(yīng)用從這個快照之后發(fā)生的日志。當(dāng)所有的日志都應(yīng)用之后,它會是***的并且可以持續(xù)的同步主節(jié)點和服務(wù)web服務(wù)器的讀請求。
然而,當(dāng)一個大數(shù)據(jù)庫的寫比率相當(dāng)高時,在從節(jié)點和存儲設(shè)備中會有較多的網(wǎng)絡(luò)延遲,有可能日志被讀取的速率比日志創(chuàng)建的速率要慢,這樣從節(jié)點將會被落的越來越遠(yuǎn)而且永遠(yuǎn)都追不上。
我們的解決方案是在讀復(fù)制開始從主節(jié)點上傳輸基礎(chǔ)快照時就開啟第二個流來傳輸日志并存儲到本地磁盤上,當(dāng)一個快照結(jié)束傳輸時,讀復(fù)制可以在本地讀區(qū)日志,使得恢復(fù)進(jìn)程更加塊。
這不僅解決了我們在全美的數(shù)據(jù)庫復(fù)制問題,也使建造新的復(fù)制的時間減半。現(xiàn)在即使主節(jié)點和從節(jié)點在同一個區(qū)域,操作效率也很大程度的提高了。
總結(jié)
Instagram現(xiàn)在在全美運行了多個數(shù)據(jù)中心,給我們了更彈性的容量規(guī)劃和獲取,更高的可靠性,更好的為2012年發(fā)生的那樣的自然災(zāi)害的準(zhǔn)備。事實上,我們最近在一個計劃的“災(zāi)難”中存活。Facebook
規(guī)律性地測試它的數(shù)據(jù)中心,通過在訪問高峰的時候關(guān)閉它們。大約一個月前,我們剛剛完成遷移我們的數(shù)據(jù)到一個新的數(shù)據(jù)中心,F(xiàn)acebook就運行了一個測試并且關(guān)停了這個數(shù)據(jù)中心。這是一個高風(fēng)險
的模擬,但是幸運的是我們不被用戶注意到的度過了容量損失。Instagram遷移第二部分成功了!