Java延時(shí)實(shí)例分析:Lock vs Synchronized
這篇文章通過(guò)實(shí)例討論了:
- java.concurrent.Lock創(chuàng)建的垃圾
- 比較Lock和synchronized
- 如何通過(guò)編程方式計(jì)算延時(shí)
- Lock和synchronized競(jìng)爭(zhēng)帶來(lái)的影響
- 延遲測(cè)試中由于遺漏(co-ordinated omission)可能對(duì)結(jié)果的影響
回到我最喜歡的一個(gè)主題:垃圾的創(chuàng)建與分配。可以從我以前的文章(如:性能優(yōu)化的首要法則和重視性能優(yōu)化首要法則:逃逸分析的效果)獲取更多關(guān)于這個(gè)議題的細(xì)節(jié)。尤其弄懂在性能問(wèn)題上,為什么分配是如此重要的因素。
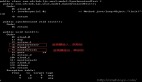
幾天前,當(dāng)我診斷一些 JIT 編譯期間奇怪的分配問(wèn)題時(shí),發(fā)現(xiàn) java.util.concurrent.locks.ReentrantLock 的分配有問(wèn)題,不過(guò)這只在競(jìng)爭(zhēng)條件下出現(xiàn)。(這一點(diǎn)很容易證明,只要運(yùn)行一個(gè)在 Lock 上建立競(jìng)爭(zhēng)并指定 –verbosegc 參數(shù)測(cè)試程序(類似下面的程序))。
示例是在有 Lock 競(jìng)爭(zhēng)時(shí) GC 的輸出結(jié)果:
- [GC (Allocation Failure) 16384K->1400K(62976K), 0.0016854 secs]
- [GC (Allocation Failure) 17784K->1072K(62976K), 0.0011939 secs]
- [GC (Allocation Failure) 17456K->1040K(62976K), 0.0008452 secs]
- [GC (Allocation Failure) 17424K->1104K(62976K), 0.0008338 secs]
- [GC (Allocation Failure) 17488K->1056K(61952K), 0.0008799 secs]
- [GC (Allocation Failure) 17440K->1024K(61952K), 0.0010529 secs]
- [GC (Allocation Failure) 17408K->1161K(61952K), 0.0012381 secs]
- [GC (Allocation Failure) 17545K->1097K(61440K), 0.0004592 secs]
- [GC (Allocation Failure) 16969K->1129K(61952K), 0.0004500 secs]
- [GC (Allocation Failure) 17001K->1129K(61952K), 0.0003857 secs]
我懷疑是否是在垃圾回收時(shí)必須對(duì)清理 Lock 上分配的空間,在高度競(jìng)爭(zhēng)的環(huán)境下,將會(huì)選擇一種比內(nèi)建的 ‘synchronized‘ 更壞的同步策略。
當(dāng)然,這個(gè)問(wèn)題比其他任何問(wèn)題都更加學(xué)術(shù)。如果你確實(shí)非常關(guān)心延遲,你會(huì)發(fā)現(xiàn)自己從來(lái)不會(huì)(或者絕不應(yīng)該)有這樣一種情況會(huì)需要這么多的線程鎖。不過(guò),請(qǐng)繼續(xù)跟我一起探究這個(gè)問(wèn)題,因?yàn)檫@個(gè)過(guò)程和結(jié)果都非常有趣。
簡(jiǎn)史:鎖是2004年,在Java 1.5中引入的。由于對(duì)簡(jiǎn)單并發(fā)結(jié)構(gòu)的迫切需要,鎖以及其他并發(fā)工具因此而誕生。在這之前,你不得不通過(guò)內(nèi)建的 synchronized 和 Object 的 wait()、notify() 方法來(lái)控制并發(fā)。
ReentrantLock 提供許多比 synchronized 更好的功能,下面是一些例子:
-
變得非結(jié)構(gòu)化——比如,不會(huì)受塊或方法的限制,允許你跨多個(gè)方法持有鎖。
-
輪詢鎖
-
等待鎖超時(shí)
-
配置失敗策略
但是它們?cè)谘舆t測(cè)試中有什么作用呢?
我寫了一個(gè)簡(jiǎn)單的測(cè)試來(lái)比較 Lock 和 synchronized 的性能。
這段代碼允許改變線程的數(shù)量(1個(gè)線程意味著不存在競(jìng)爭(zhēng))及競(jìng)爭(zhēng)的數(shù)量。通過(guò)有遺漏(coordinated omission)和沒(méi)有遺漏來(lái)衡量。
采用 Lock 或者 synchronised 來(lái)運(yùn)行測(cè)試。
為了記錄結(jié)果,我使用了 Histogram 類。該類是 Peter Lawrey 創(chuàng)建的。你可以在 Chronicle-Core 的工具類中找到該類。
- import org.junit.Test;
- import java.util.concurrent.locks.Lock;
- import java.util.concurrent.locks.ReentrantLock;
- public class LockVsSync {
- private static final boolean COORDINATED_OMISSION = Boolean.getBoolean("coordinatedOmission");
- //Either run testing Lock or testing synchronized
- private static final boolean IS_LOCK = Boolean.getBoolean("isLock");
- private static final int NUM_THREADS = Integer.getInteger("numThreads");
- <a href='http://www.jobbole.com/members/madao'>@Test</a>
- public void test() throws InterruptedException {
- Lock lock = new ReentrantLock();
- for (int t = 0; t < NUM_THREADS; t++) {
- if (t == 0) {
- //Set the first thread as the master which will be measured
- //設(shè)置***個(gè)線程作為測(cè)量的線程
- //The other threads are only to cause contention
- //其他線程只是引起競(jìng)爭(zhēng)
- Runner r = new Runner(lock, true);
- r.start();
- } else {
- Runner r = new Runner(lock, false);
- r.start();
- }
- }
- synchronized(this){
- //Hold the main thread from completing
- wait();
- }
- }
- private void testLock(Lock rlock) {
- rlock.lock();
- try {
- for (int i = 0; i < 2; i++) {
- double x = 10 / 4.5 + i;
- }
- } finally {
- rlock.unlock();
- }
- }
- private synchronized void testSync() {
- for (int i = 0; i < 2; i++) {
- double x = 10 / 4.5 + i;
- }
- }
- class Runner extends Thread {
- private Lock lock;
- private boolean master;
- public Runner(Lock lock, boolean master) {
- this.lock = lock;
- this.master = master;
- }
- @Override
- public void run() {
- Histogram histogram = null;
- if (master)
- histogram = new Histogram();
- long rate = 1000;//expect 1 every microsecond
- long now =0;
- for (int i = -10000; i 0){
- if(!COORDINATED_OMISSION) {
- now += rate;
- while(System.nanoTime() =0 && master){
- histogram.sample(System.nanoTime() - now);
- }
- }
- if (master) {
- System.out.println(histogram.toMicrosFormat());
- System.exit(0);
- }
- }
- }
- }
結(jié)果如下:
這是沒(méi)有遺漏(co-ordinated omission)的結(jié)果:
-
采用微秒來(lái)衡量。
-
圖形的頂部就是延遲的分布。
-
這是有競(jìng)爭(zhēng)的測(cè)試,使用四個(gè)線程執(zhí)行該程序。
-
這個(gè)測(cè)試是在8核的 MBP i7 上運(yùn)行的。
-
每次測(cè)試迭代200,000,000次,并有10,000次預(yù)熱。
-
根據(jù)吞吐率為每微妙迭代一次來(lái)調(diào)整遺漏。

如我們所期望的一樣,沒(méi)有競(jìng)爭(zhēng)時(shí),結(jié)果是基本相同的。JIT 已經(jīng)對(duì) Lock 和 synchronized 進(jìn)行了優(yōu)化。在有競(jìng)爭(zhēng)的情況下,占用百分比低的時(shí)候,使用 Lock 會(huì)稍微快一點(diǎn),但是這種差別真的很小。所以,即使存在很多的年青代GC(minor GC),它們也沒(méi)有顯著的降低 Lock 效率。如果都是輕量級(jí)的 Lock,總體上就比較快了。
這是調(diào)整為有遺漏情況后的結(jié)果。

當(dāng)然,在有遺漏的情況下延遲會(huì)更高。
再次可以看到,在無(wú)競(jìng)爭(zhēng)情況下,lock 和 synchronized 的性能是相同——這就沒(méi)什么很驚奇了。
在競(jìng)爭(zhēng)條件下,百分率為99%時(shí),我們看到 synchronized 比 lock 表現(xiàn)好10X。在這之后,兩者的表現(xiàn)基本是一致的。
我猜測(cè)這是因?yàn)镚C回收的效率導(dǎo)致 lock 比 synchronised 要慢,大概每300-1200微妙發(fā)生一次GC回收。尤其是到達(dá)99%之后,慢得就相當(dāng)明顯了。在這個(gè)之后,延遲率可能與硬件和操作系統(tǒng)(OS)相關(guān)。但 是,這只是我個(gè)人的推斷,沒(méi)有做更深入的調(diào)查。
結(jié)論:
這篇文章更多的是怎么去測(cè)量和分析延遲。在競(jìng)爭(zhēng)條件下,Lock的分配是一個(gè)非常有意思的話題,在真實(shí)世界里,這個(gè)問(wèn)題也未必有什么實(shí)際的不同。