Hadoop都2了 大數據應用會邁上一個新臺階嗎
Apache軟件基金會終于推出了最新的Hadoop2數據分析平臺,從而引發了輿論對大數據演進大飛躍的美好憧憬,此前我曾經寫過“Hadoop就是大數據應用又何妨”一文,對國內大數據市場現狀進行了分析。如今Hadoop 2發布,會如輿論所預計一樣刺激大數據應用和發展嗎?
我認為首先要看一下,Hadoop 2進行了哪些改進?從相關報道來看,Hadoop 2最大的改進是發布了YARN數據處理和服務引擎,用于對Map/Reduce進行了改進,同時為Hadoop File System (HDFS)添加高可用特性。
可以看一些技術細節,對Hadoop數據進行訪問,需要開發Java應用實現Map/Reduce,學習起來會有一些困難,除此之外,也可以采用Hbase,用近似數據庫范式來處理數據。其Hive數據倉庫讓你可用類SQL的HiveSQL查詢語言來創建查詢,并轉化為MapReduce任務。不過Hadoop仍受限于單線程性。MapReduce任務、Hive查詢、Hbase操作等等都要輪流進行,這就是局限。
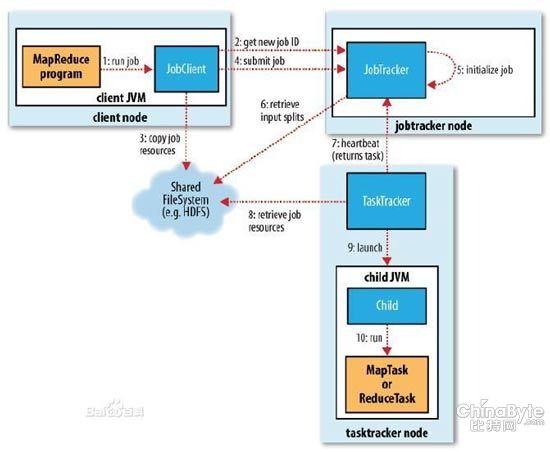
Hadoop開發社區也意識到這個問題,在Hadoop2進行了改進,將Map/Reduce升級為Apache YARN(Yet Another Resource Negotiator)。
YARN項目主管ArunMurthy指出:Hadoop1.0和2.0的區別在于,前者所有的事情都是面向批處理的,而后者則允許多個應用同時在內部訪問數據。
換句話說,相對于當前Map/Reduce系統能處理的事情,把這些功能分開使得Hadoop集群資源的管理更加強大。其主要管理方式類似于操作系統對任務的處理,不再有一次一項操作的限制了。
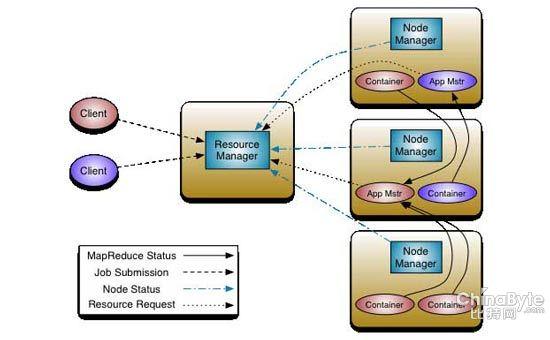
有了YARN,開發者就能夠直接在Hadoop內部來開發應用,而不是像許多第三方工具所做的那樣,在外面把數據篩選出來。
從Hadoop 1.0到2.0對于用戶來說并沒有本質不同,只是從技術的角度,簡化技術開發的難度,是一種量的積累,而不是質的改變。對于最終用戶來說,Map/Reduce也好,YARN也好,不過是一種對資源的調度和使用方式。
因此,無論Hadoop 1.0、2.0其最大的貢獻還在于讓我們有機會使用X86等廉價手段來處理海量結構化數據,這也是大數據應用被廣泛推廣和談及的主要原因。從目前來看,國內大數據應用所需要的還是大數據服務的提供商,至于這些服務商使用Map/Reduce,還是YARN都不重要,重要的不是工具,而是服務和結果。無論是Map/Reduce,還是YARN都不是普通非專業人員可以使用的,它還不想使用PC這么簡單,現在所需要的是會使用Map/Reduce,或者YARN的人,需要他們提供專業化的服務。
Hadoop 2會促進大數據應用和發展,但在國內關鍵化問題仍然沒有解決,因此難以樂觀。