













VMware籌備Serengeti項目 欲推Hadoop虛擬工具
作為一家像VMware這樣的服務器虛擬化供應商,其眼中恐怕沒有哪種工作負載不能(或者說不應該),被以抽象形式剝離底層硬件、從而使其變得更具可塑性與便攜性。從這個角度出發,VMware理所當然地把Hadoop作為下一個進軍目標——順便賺點經濟回報。
過去幾年,VMware一直建議稱Hadoop不應運行于x86服務器裸機當中。直到一年前,VMware的這種言論才有所止息,并開始著手通過代號為Serengeti的項目開發一整套工具,旨在最終加快Hadoop的部署與實施速度。
Serengeti項目最初亮相于去年六月的Hadoop World大會,它采用Spring Java框架(目前已經歸EMC與VMware的子公司Pivotal所有)。這套框架由Java編寫,專門用于Hadoop調整工作。
服務器虛擬化技術在效率方面的優勢可謂眾所周知,而且目前已經被廣泛應用于企業級數據中心領域。Hadoop方案的效果卻未得到如此廣泛的認同,這主要是因為與其它以CPU利用率為主要難點的通用服務器工作負載不同、大數據處理有著自己的一套資源要求。大家都知道,Hadoop對于I/O及存儲容量的要求更嚴苛(CPU要求則相對較低),因此提高CPU利用率無法給Hadoop方案帶來任何幫助;事實上,這可能反而會擾亂Hadoop集群節點中磁盤驅動器與CPU核心間的平衡關系。
不過虛擬化技術卻正是解決這一難題的良方。它不僅能夠維持計算與存儲之間的平衡,而且能夠取代處理數據所需要的龐大物理設備——這將顯著提升企業的運營效益,也正是虛擬化技術的最大優勢。
將Hadoop集群中的管理、查詢、數據抽象工具以及各種節點設備匯總在同一套虛擬機系統中絕對是個好語音,這樣一來整個體系將可以像其它虛擬基礎設施一樣實現復制與故障轉移功能。而對開發人員來說,Serengeti項目則足以幫助他們將整套虛擬Hadoop集群安裝在單一物理設備上,從而簡化編碼、測試等流程,何樂而不為呢?
Serengeti項目概述
更重要的是,我們可以通過對Hadoop進行虛擬化將工作負載轉移至其它虛擬化服務器池當中,從而使Hadoop集群使用與網絡、應用以及數據庫相同的基礎設施,這對于企業用戶接納新生方案來說意義非凡。El Reg網站去年就曾撰文指出,優秀的虛擬化Hadoop集群應用將擁有兩套不同的Task Tracker與JobTracker節點,從而實現兩套不同Hadoop集群共享同一組數據節點,并與單一NameNode協同運作。
NameNode是幫助Hadoop分布式文件系統實現對整個集群內非結構化數據塊追蹤任務的關鍵所在;它類似于磁盤驅動器中的文件分配表。一旦失去NameNode,我們就失去了整個HDFS;正如沒有FAT,也就沒有磁盤驅動器上的數據一樣。
舉例來說,大家可以讓一號虛擬集群使用物理節點上的一組副本數據而讓二號虛擬集群使用另一組數據,這樣整個集群的數據吞吐量就瞬間翻了一倍。
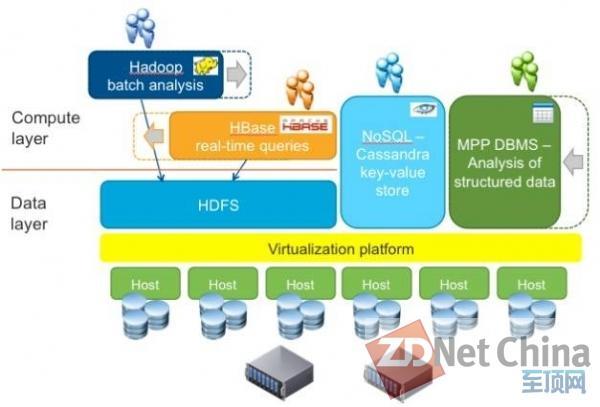
Serengeti項目結構圖
Serengeti項目不僅了解如何對核心Hadoop服務器進行虛擬化及復制,在處理HDFS之上的HBase數據庫倉儲系統方面同樣得心應手。它能以主動及熱備份副本方式處理HMaster節點的數據倉儲內容,更能在數據倉儲與HDFS相結合時實現HBase RegionaServer的向外擴展。這些功能都已經在今年四月Serengeti 0.8.0版本中出現。
現在,VMware正加緊時間將Serengeti投付生產。在今天于圣何塞舉辦的Hadoop峰會上,虛擬化巨頭將公布一套ESXi管理程序子集的測試版本以及名為Big Data Extensions的vSphere插件(這是第一款針對Serengeti的商用支持方案)。VMware公司產品管理高級主管Fausto Ibarra在接受El Reg網站采訪時指出,Big Data Extensions將以免費形式出現在vSphere的下一個版本中——“免費”這個詞從VMware嘴里說出來可有點新鮮。預計vSphere新版本(可能是5.2)將在8月底的VMworld大會上亮相,并于秋末正式上市。
大家可以點擊此處下載該插件,并將其與ESXi及vSphere 5.1配合使用。
根據Ibarra的說明,商用Serengeti軟件無需VMware的分布式資源調度(簡稱DRS)插件的支持即可直接與ESXi或者vCenter控制機制協作,從而在HDFS及HBase上實現彈性功能。但配合DRS,“它將可以更好地發揮作用。”其中含義目前尚不明確。
Big Data Extensions已經確定可與開源Apache Hadoop 1.2堆棧、Cloudera CDH 3.X與4.2、MapR 2.1.3、Hortonworks Data Platform 1.3以及Pivotal 1.3全系列并行協作。#p#
零售商、高科技客戶以及金融機構已經開始使用該項目
Ibarra同時指出,有趣的是客戶們已經開始通過兩種途徑接納Serengeti。那些對ESXi較為熟悉的客戶利用它對服務器進行虛擬化,從而將Hadoop引入虛擬存儲池。而另一些擁有物理Hadoop集群的客戶則開始嘗試利用VMware的管理程序及工具對Hadoop及其它工作負載進行虛擬化。
Ibarra并未透露將Serengeti作為原型方案或引入生產系統的企業客戶的具體數量,但大型零售商、高科技產品制造商、金融服務企業以及新興企業已經開始在商業版本推出之前著手嘗試。
鑒于Hadoop的開源特性,Serengeti在起步階段的表現至關重要。開源項目對于客戶往往具備強大的吸引力,而Hadoop發行商Hortonworks、Linux發行商紅帽以及OpenStack云控制器發行商Mirantis已經準備聯手推出Svanna項目,旨在以OpenStack及KVM管理程序為基礎實現Hadoop虛擬化。
除了帶來生產級Serengeti工具前瞻之外,VMware還將在今天公布大型大數據處理方案Pivotal HD 1.0發行版,這是VMware開發的首個支持Hadoop Virtual Extensions(簡稱HVE)代碼的商用版本,可以算作贈予Apache Hadoop項目的一份厚禮。HVE不僅能使Hadoop模塊實現虛擬化識別能力,更是Serengeti良好起效的必要前提。
下面我們通過實例看看HVE的工作機制。如果大家在Hadoop集群中擁有兩個虛擬數據節點,且二者處于同一臺物理服務器當中,那么它們彼此能夠識別出對方的存在;這意味著它們可以通過內存總線進行通信,從而獲得比傳統虛擬化網絡端口更快的溝通速度。
再來看另一個例子。Hadoop習慣為數據塊保留三份副本,這主要是出于性能及可靠性的考量。HVE會將其中兩份數據副本保存在同一臺物理服務器當中,但對于第三份副本則會刻意保存在另一臺位于其它機架中的服務器端。
Ibarra表示,HVE代碼是Apache Hadoop項目的一部分,所有發行版都將在未來幾個月內將其納為自身方案的組成部分。我們還不清楚HVE會對Savanna項目造成何種影響,但它也許能夠以相同的方式與KVM及OpenStack相對接。
通過上周MapR Hadoop發行版及數周前Cloudera的認證,Pivotal HD 1.0已經確定能夠運行在ESXi環境下。目前Hortonworks發行版是否受到支持還沒有定論,但鑒于Savanna項目與Serengeti/BDE的競爭關系,二者之間恐怕很難攜起手來。










