應需而變融易致遠 華為Hadoop大數據解決方案
人人都在談論大數據,但是究竟什么是大數據呢?大數據主要來源于互聯網領域和一些垂直行業,數據量達到PB級,甚至10PB以上;它需要更高性能、更大吞吐量、更大擴展能力.據統計,全球80%的數據在近兩年生成,平均年增長率超過50%。數據正從四面八方、各個領域中產生,變得更繁雜、更龐大、更加多樣性,如果將這些海量數據簡單堆加、存儲歸檔,是不能為企業帶來價值的,反而會增加企業投資成本。只有完成對大數據的分析、價值數據提取,才能發揮大數據最大的威力,進一步提高企業決策水平、改善業務模式,從而成為企業成功的關鍵。
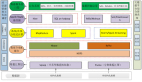
Hadoop是一個分布式計算框架,來源于Apache軟件基金會的開源項目,具有良好的并行處理能力、可擴展性和可伸縮性的特點,更適合處理半結構化、非結構化類數據,是重要的大數據計算和分析平臺。Hadoop因此獲得大多數數據分析廠商的關注和支持,成為當下大數據領域的熱點技術。根據上述大數據的四個特點,系統不僅需要具備超高的性能和超大的存儲空間,還必須將數據存儲與數據分析相結合,由此華為N8000-Hadoop大數據解決方案應運而生。該方案借助華為N8000系統先進的集群架構和企業級存儲功能,集成Hadoop計算框架,提供從密集型數值計算和數據存儲中實時獲取的分析處理結果,幫助客戶提高決策和運營效率,簡化管理并降低組網成本。華為N8000-Hadoop大數據解決方案有以下特性和優勢:
1. 數據互通,承載多業務
首先,我們先分析一下當前集群NAS應用Hadoop的典型數據處理流程。數據通過集群NAS的NFS/CIFS等NAS協議完成數據存取操作,而Hadoop是架構在HDFS協議之上,這意味著集群NAS的數據不能被Hadoop計算框架直接使用,必須通過異構數據源之間進行數據交換的工具,將異構數據源的數據抽取到中間層進行轉換,最后加載到數據倉庫中,成為Hadoop計算框架能夠分析處理的數據。而華為N8000-Hadoop方案提出一種創新的思路,消除了這個桎梏,實現在不同的數據處理系統之間進行數據交換,在同一個存儲空間中,數據可以自由流通,所見即所得,并且不需要改變傳統NAS用戶使用習慣和組網方式,無縫對接Hadoop計算框架,實現數值計算、數據存儲以及即時的數據分析和事務處理等多業務的承載。
2. 提高存儲利用率,降低TCO
使用開源Hadoop的默認配置,一種典型的犧牲存儲空間換取數據可靠性和讀寫效率的方式,其最大存儲空間利用率是33%。而華為N8000-Hadoop大數據解決方案充分利用了N8000產品企業級存儲功能特性的優勢,通過選擇各種RAID級別技術來實現不同級別的冗余、錯誤恢復和數據保護功能,存儲空間利用率可達80%,從而降低系統總體擁有成本TCO。
3. 企業級Hadoop整體解決方案
在使用開源Hadoop時的第一個問題是如何為Hadoop集群選擇合適的硬件,這需要考慮各種影響因素,往往根據使用經驗來決定配置,這使得構建系統存在很大不確定性。華為N8000-Hadoop大數據解決方案可為一個給定的工作負載選擇合理的硬件配置來實現性能和經濟的最佳平衡。華為N8000集群系統作為企業級存儲產品,采用多節點全Active集群技術,所有部件均為冗余設計,無單點故障,系統提供數據保險箱技術和文件系統鏡像等軟件技術進一步提高系統可靠性。
4. 海量小文件處理性能
目前,很多用戶開始利用Hadoop處理海量數據,并取得很好的效果,但隨著數據量增加,尤其是小文件數目的增多,逐漸發現Hadoop能夠高效自如地處理大文件,卻在處理海量小文件時由于Name Node占有率高而導致訪問效率低的問題。而華為N8000-Hadoop方案是基于共享集群文件系統,消除了Name Node的限制,具有多任務處理的功能,元數據可被分段管理,不會出現性能瓶頸,從而提高了對海量小文件處理的效率。