大數據應用之路——大數據技術大會成功舉行
在當今企業中80%的數據都是非結構化數據,這些數據每年都按指數增長60%。大數據將挑戰企業的存儲架構、數據中心的基礎設施等,也會引發數據倉庫、數據挖掘、商業智能、云計算等應用的連鎖反應。未來企業會將更多的TB級(1TB=1024GB)數據集用于商務智能和商務分析。到2020年,全球數據使用量預計將暴增44倍,達到35.2ZB(1ZB=10億TB)。大數據正在徹底改變IT世界。大數據時代的來臨已經毋庸置疑,尤其是在電信、金融 等行業,幾乎已經到了“數據就是業務本身”的地步。這種趨勢已經讓很多相信數據之力量的企業做出改變。
恰逢此時,為了讓更多的人了解和使用分析大數據,CSDN獨家承辦的大數據技術大會于2011年11月26日在北京中旅大廈隆重舉行。本次大會匯集 Hadoop、NoSQL、數據分析與挖掘、數據倉庫、商業智能以及開源云計算架構等諸多熱點話題。包括百度、淘寶、新浪等業界知名專家與參會者齊聚一堂,共同探討大數據浪潮下的行業應對法則以及大數據時代的抉擇。
大會背景
大數據的浪潮已經影響到了很多企業。淘寶目前每天的活躍數據量已經超過50TB,共有4億條產品訊息和2億多名注冊用戶在上面活動,每天超過 4000萬人次訪問;百度每日新增數據10TB,每天系統需要處理1PB的數據,每天提交10000+ jobs,而每周有近百塊硬盤故障;上海證券交易所每秒處理近9萬筆業務,每日成交筆數達到3億筆以上。
在這其中,還挾裹著一個更為重要的趨勢,即數據的社會化(Socialization of Data)。從博客論壇到游戲社區再到微博,從互聯網到移動互聯網再到物聯網,人類以及各類物理實體的實時聯網已經而且還將繼續產生難以估量的數據。對于時刻關注市場走向的企業來講,他們需要關注的數據顯然已經不僅限于企業內部數據庫中的業務數據,還要包括互聯網(以及未來的物聯網)上各類網絡活動所產生的相關數據記錄。
與此同時,在“大數據”時代出現了不少新興的數據挖掘技術,使得對數據財富的儲存、處理和分析變得比以往任何時候都更便宜、更快速了。只要有了好的計算環境,那么大數據技術就能被眾多的企業所用,從而改變很多行業經營業務的的方式。
大會三大亮點
本次大會包含最受關注的技術話題:Hadoop、NoSQL、數據分析與挖掘、數據倉庫、商業智能、開源云計算架構等最受關注的技術熱點;最資深的技術專家:百度、淘寶、新浪等業界知名數據處理專家齊聚;***行業應用實踐:金融、廣告、SNS、游戲、電子商務行業大數據架構***實踐。九名講師圍繞架構、數據分析、商業智能等話題,深入分享實戰經驗,解析開發中普遍遇到的難點與技術熱點。
大會精彩內容
金融領域大數據處理的專家ymall.com技術總監巨建華表示高頻金融交易數據的主要特點是實時性和大規模,目前滬深兩市每天4個小時的交易時間 會產生3億條以上逐筆成交數據,隨著時間的積累數據規模非常可觀,與一般日志數據不同的是這些數據在金融工程領域有較高的分析價值,金融投資研究機構需要 經常對歷史和實時數據進行挖掘創新,以創造和改進數量化交易模型,并將之應用在基于計算機模型的實時證券交易過程中,因此一般的數據庫系統無法滿足如此大 規模和實時性,靈活性的要求。
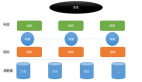
而來自淘寶的兩位專家則分別介紹了淘寶在面臨大數據時代是如何解決存儲和數據處理的難題。淘寶核心系統存儲系統研發專家楊志豐表示淘寶每天大約有 6000萬用戶登錄以及20億PV量。淘寶數據庫對于淘寶來說非常重要。幾乎所有淘寶業務都依賴淘寶數據庫。淘寶數據庫具備數以千計的數據庫服務器同時要 應對單表幾億至幾百億條的記錄以及每天幾億至幾百億次訪問。為了應對大數據的沖擊,淘寶將以前的Oracle、小型機、高端存儲模式轉變到現今的 MySQL、OceanBase、Hbase、MongoDB等數據庫,并使用普通PC服務器。楊志豐表示OceanBase可擴展數千億條記錄、數百 TB數據、數十萬QPS以及數萬TPS。同時具備實時容錯、自動故障恢復和99.999%高可用性。
淘寶數據產品團隊負責人趙昆則表示現今淘寶面臨數據量大;內容多樣(日志型數據、文本數據、關系型數據);維度豐富(涵蓋近100個不同行業的商品 維度,五級商品類目體系、近 80000個品牌、商品維度+賣家維度+買家維度);源數據質量不高(非法交易、惡意評價、用于自定義屬性)等問題。對于淘寶面臨的挑戰,趙昆認為分布式 存儲計算、實時計算、實時流處理、基于云計算的數據挖掘、數據可視化和數據產品實踐等是應對大數據浪潮的關鍵技術。趙昆***向大家介紹了淘寶的數據魔方。 他表示數據魔方是淘寶***個基于全量數據的數據產品。也是***個成熟的、基于海量數據的商業數據產品。數據魔方底層基于云計算,同時明年計劃開放數據給第 三方應用。
Admaster數據挖掘總監謝超作為數據分析領域的專家也闡述了當今大數據下數據分析的形勢。他認為必須分布式存儲(TB/天)、多個海量數據集 (千億行join)、差的數據質量以及不統一的數據格式(結構化、半結構化等、非結構化合并分析數據集的特點)是數據存儲方案面臨的挑戰。謝超表示大數據 BI的新需求包括大量化(多個大數據集并行分析)、多樣化(結構化、半結構化、非結構化)、快速化(Velocity)和價值(易用性)。而計算分層(流 計算、塊計算、全局計算)、快速分析(冗余維度、數據常駐在內存中分析)和接近價值(業務人員易用的命令、靈活的編程框架)是解決新需求的BI方案。
互聯網巨頭新浪的云計算高級技術經理叢磊透露了SAE的相關數據,他表示2011年新浪SAE平臺注冊用戶已達50000,應用超過100000, 日均PV達到1億,活躍開發者達到10000名。叢磊還介紹了新浪自己開發的的KVDB,KVDB用來支持公有云計算平臺上的海量key-value存 儲。KV DB支持的存儲容量很大,對每個用戶支持100G的存儲空間,可支持1000000000條記錄,用戶可以用KV DB存放簡單數據,如好友關系等。KVDB具備存儲引擎可替換、任意模塊水平擴展、支持讀寫分離、支持前綴查找、支持secondary index、支持認證、支持重平衡和無縫遷移等優勢。
***人云科技創始人兼總經理吳朱華表示海量數據呈現“4V + 1C”的特點。既Variety:一般包括結構化、半結構化和非結構化等多類數據,而且它們處理和分析方式有區別;Volume:通過各種設備產生了大量 的數據,PB級別是常態;Velocity:要求快速處理,存在時效性;Vitality:分析和處理模型必須快速變化,因為需求在 變;Complexity:處理和分析的難度非常大。互聯網企業、智能電網、車聯網、醫療行業和安全領域等都充分體現出海量數據的用途和價值。他認為中小 企業面對大數據的解決之道應遵循采集、導入/處理、查詢、挖掘的流程。