













幾種XML基準測試的比較與分析
作者:錢茛南 馬子明 曹曉芳
摘 要 XML基準測試已經成為流行的XML文檔管理技術的測試方法。文章從測試場景、測試數據和對XQuery支持三方面,對主流的五種XML基準測試:Xmach-1、Xmark、Xbench、XOO7和TpoX進行了比較與分析。并闡明了這五種測試方法當前所存在的問題。
引 言
隨著XML技術在各種應用領域中廣泛的使用,越來越多的數據以XML文檔形式呈現。如何對海量的XML文檔進行有效管理,已成為人們所研究的熱點。目前,主要有兩類技術來管理大批量XML文檔,分別是XML原生數據庫技術和關系數據庫擴展技術。前者主要以開源軟件居多,且內部多依靠Xpath、XQuery技術實現,現已有eXist、MonetDB/XQuery和BaseX等十余款產品;后者基本上是成熟的商業關系數據庫,通過附加插件的方式,以增加對XML文檔管理的能力,代表產品有IBM的PureXML、Oracle的XDK等。
伴隨著XML文檔管理技術的發展,衡量各種技術的處理效率的要求也日益增長。XML基準測試是一種衡量XML文檔管理技術的測試方法。對開發者而言,通過XML基準測試,可以衡量已有技術的處理效率,對未來的開發有指導意義;對用戶來說,它的結果是選擇XML文檔管理產品時的可靠依據。
XML基準測試簡介
從1999年FK提出XML 數據向關系數據庫映射效率問題起,到2001年首個開源產品Xmach-1面世,再到2007年首個有工業支持背景的TpoX,其間出現了多種XML基準測試。截止2010年,共有Xmach-1、Xmark、MBench等十余款產品面世。其設計出發點、測試重點、實現機制各不相同。本文挑選了在實際應用中獲得廣泛使用的五種主流基準測試作為研究對象進行闡述。
Xmach-1是萊比錫大學E. Rahm與T. Böhme在2000年研發的一款多用戶基準測試。其系統框架包括XML數據庫、應用服務器、數據負載器和用戶端瀏覽器。其不僅是第一款開源產品,也是第一款面向多用戶的基準測試。
Xmark是CWI小組的R. Busse、M. Carey等人在2003年提出的。它是單用戶級別的基準測試。它模擬了一個網絡拍賣的應用環境。與其他測試不同的是,它只采用了一個容量可伸縮,最大可達10GB的XML文件,作為測試基礎數據。
Xbench是滑鐵盧大學B.Yao與M. Tamer Özsu等人與2002年提出。其將實際中的XML文檔應用,按單、多文檔和數據集中、文本集中等特征進行交叉劃分,分為四類應用類型。基于各種類型,有不同的測試策略。
XOO7是在完善的OO7基準測試的基礎上,U. Nambiar等人在2001年擴充完成的。其出發點是測試基于面向對象技術的數據庫管理系統,對XML文檔的處理能力。
TpoX是M. Nicola和A. Gonzalez等人在2007年提出的。與前述基準測試不同,TpoX項目的參與人員均來自商業公司,是第一款有工業背景的基準測試。它模擬了一個多用戶的金融應用環境。
比較與分析
盡管各種測試的研發出發點和實現技術各不相同,但其執行流程都遵循如下順序:先生成測試場景,再基于場景生成測試基礎數據,最后再使用XQuery對數據進行操作,即輸出最終的測試用例。以下也從該三方面進行比較與分析。
測試場景
測試場景是與待測試軟件的執行相對應的一個活動場景,由一系列活動按照一定的順序組成,它描述了系統的典型活動過程,是系統業務特性的一種體現。一個設計優秀的測試場景,將使測試更符合實際使用情況,揭示出產品在現實應用中的真實表現。
Xmach-1的測試場景是構建了一個多用戶的圖書論文管理系統,共有目錄文檔和受管文檔兩類文檔,其各自又包含結構化數據和文本數據兩種數據類型。測試場景映射為數據庫的ER圖后,包含文檔、題目、章節、作者名等共8個實體,及這些實體之間的18個相互關系。
Xmark的測試場景是構建了一個單用戶的網絡拍賣站點,模擬一個注冊用戶從挑選拍賣品開始,到出價定拍結束的整個流程。其主要實體有注冊用戶、拍賣品、出價等共6個,其之間交互關系有9個。
Xbench將測試場景依據應用特性和數據特性分為四類:DC/SD、DC/MD、TC/SC和TC/MD。其分別模擬不同的在線應用,如DC/SD模擬一個在線購物網站,DC/MD為B2B系統。但總體來說,其性質還是偏向電子商務類的應用系統。四類中最為復雜的DC/SD,其實體包括日期、發布者等十余個,關系也達到了數十個。從數量上來說,是五種基準測試中最多的。
XOO7可以說是OO7基準測試的XML版,其測試場景也是依據OO7而設定。構建了一個用戶交互頻繁的電子商務系統。實體包括用戶信息、基本匯集信息等共11個,關系也達到了42條。是本次比較中,實體數僅次于Xbench的。
TpoX是五種基準測試中面世最晚的,其在場景設計中,也借鑒了先前各種方法的經驗。它仍然是構建一個基于Web的電子商務系統,但其實體數只有用戶、賬戶等共5個,其關系沒有事先指定,而是封裝在了41個外部的XSD文件中。這樣,在測試過程中,可以從XSD文件中靈活地選擇搭配,來組合出符合測試者關注點的測試場景。
測試數據
測試數據是指依據已有的測試場景,遵循實體--關系的定義,自動生成的大批量基礎數據。是在實際測試前,生成并輸入到數據庫中,做為測試用例的數據輸入。衡量測試數據是否有效,一般從數據量和數據生成方式兩方面進行。過小規模的數據量,無法模擬真實的使用環境;通過簡單的隨機方式生成的數據,也無法有效地反映XML文檔管理系統的處理效率。
表1從默認數據集容量、生成方式及種子來源三個方面對五種基準測試進行了比較。
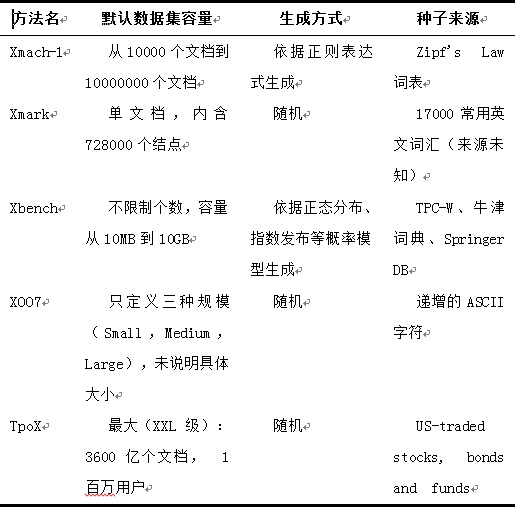
表1 測試數據比較
XQuery支持
W3C于2001年12月提出了XML查詢語言規范—XQuery語言。XQuery是一種對XML結構的文檔和數據進行查詢的語言,它汲取了其它多種查詢語言的優點,適用于各種類型的XML數據源的查詢,而且簡潔靈活易于實現。
當前幾乎絕大多數的XML文檔管理系統,都是基于XQuery來實現對XML文檔的CRUD操作。相應的,五種基準測試均不同程度上使用了XQuery技術,來生成測試用例,以檢驗XML文檔管理的處理效率。
W3C制定的XML Query Use Case中舉出了XQuery操作實例,五種基準測試均借鑒了其操作方式。為便于比較,將操作實例映射為數據庫的增加、查詢、更新與刪除操作(CRUD)。表2給出了各基準測試對XQuery支持的情況。
需要指出的是,所生成的XQuery,依賴于被測的XML文檔管理系統。如TpoX所生成的XQuery查詢語句針對DB2進行了許多優化,使得其七個語句充分擴展后,可以支持CRUD四種操作。

測試數據比較
3 現有問題
XML基準測試目前已經在眾多實際XML數據集中的項目中,得到廣泛應用:Amsterdam大學在ILPS項目中使用了xmach-1;Berkeley大學的B. Yanbin等人的XSet搜索引擎中使用了XBench;TPox在10T數據規模的實驗室環境中,成功地進行了測試。
盡管XML基準測試在實際應用有不錯的表現,但其仍存在一些問題:
1)生成的部分XQuery語句已經過時,與W3C標準不兼容
L. Afanasiev以Galax、SaxonB等以Native XML數據庫存儲XML文檔,進行了XMach-1、XOO7共5款基準測試,發現在總共生成的163個XQuery語句中,有62個不符合W3C標準。XOO7由于開發版本較早,其22個語句竟然無一符合。
由于XML具有高度的自由性,盡管不符合W3C標準,仍能被處理。但W3C標準代表了業界開發標準,越來越多的產品以W3C標準作為開發規范。XML基準測試如不能與W3C標準較好兼容的話,其測試結果將不能真實體現這些產品的實際性能。
2)測試場景單一,與實際使用的系統相差較大
按測試場景的應用領域來分,Xmach-1模擬了圖書論文管理系統,其余四款均是模擬了在線的電子商務系統。但對近年來大規模應用XML的社交網絡、e-learning系統,以上五種測試均未涉及。此外,在已模擬的電子商務場景中,各種測試生成的模擬操作均是成功的流程用例。但實際環境中,存在大量的交易取消和交易失敗的情況。Xbench對場景進行了細分,是五種測試中場景定義最好的,但也存在生成的用例,難以達到復雜應用對系統輸入的要求。
3)測試數據類型只基于ASCII碼;內容缺乏針對性;生成方式單一
五種基準測試生成的測試數據,絕大多數都是基于ASCII字符集的英文語系內容,沒有設計其他語種的文字內容。在軟件開發國際化要求越來越突出的背景下,不支持多語種大字符集(如Unicode)的基準測試,很難得到廣泛應用。
此外,測試數據的內容過于寬泛,缺乏針對性。在使用非隨機數的基準測試中,Xmach-1使用的是純詞頻優先方式,對出現在主流報刊的詞匯進行挑選;Xbench選擇了牛津詞典作為數據來源;Xmark與Xmach-1類似,將常見的詞匯作為數據來源。這樣所選取的數據,內容覆蓋過廣,缺乏代表性,不能較好體現被測系統所面向特定領域的特點。如藥品的拉丁文英文譯名在實際情況下,極少出現在一家出售家用電器的B2B系統中。
生成方式單一也有可能會導致數據質量不高。除Xbench使用了概率模型,其他幾種主要使用了隨機生成方法。由于隨機種子的限制,很難保證數據不出現重復。而數據重復現象,在TB級別的數據生成時,將較大影響測試效果。
結 論
XML基準測試是一種衡量XML文檔管理技術的測試方法。本文從測試場景、測試數據和對XQuery支持三方面對五種主流的XML基準測試進行了比較與分析。此后,指出了其現存的問題。
XML基準測試在實際應用中使用頻率逐漸增加,日益得到人們認可。如能在未來的研發過程中,不斷完善功能,彌補自身現有缺陷,將成為評測XML文檔管理技術的有力工具。
責任編輯:桑丘
來源:
中國軟件評測中心
















