Twilio的經(jīng)驗(yàn)分享:合理設(shè)計(jì)的系統(tǒng)可避免“云震”的傷害
原創(chuàng)【51CTO精選譯文】美國(guó)時(shí)間4月21日凌晨開(kāi)始,Amazon位于東海岸的某個(gè)數(shù)據(jù)中心發(fā)生故障,并直接導(dǎo)致其網(wǎng)絡(luò)服務(wù)經(jīng)歷了數(shù)次嚴(yán)重中斷(51CTO編輯注:本次事件之后被命名為4.21“云震”)。這次停機(jī)事故使得互聯(lián)網(wǎng)上的許多主流網(wǎng)站也相繼陷入癱瘓。這些受到影響的知名網(wǎng)站從一方面證明了云服務(wù)當(dāng)前在推動(dòng)互聯(lián)網(wǎng)整體系統(tǒng)發(fā)展當(dāng)中所獲得的驚人成功,但也從另一方面昭示了構(gòu)建云服務(wù)時(shí)采用穩(wěn)定的分散式設(shè)計(jì)的重要性。
Twilio是一家提供云計(jì)算平臺(tái)上通訊服務(wù)的公司,提供各種API服務(wù)。在本次Amazon服務(wù)中斷事故當(dāng)中,Twilio的API及相關(guān)服務(wù)并未受到太大的影響。下面,Twilio的CTO Evan Cooke在其團(tuán)隊(duì)官方博客上分享了Twilio采取的“防震”策略。以下為譯文:

我們?cè)谌遮叧墒觳⑶覍wilio拓展到Amazon網(wǎng)絡(luò)服務(wù)之上的同時(shí),也嚴(yán)格遵循架構(gòu)設(shè)計(jì)的原則,以盡量減少偶然發(fā)生的底層基礎(chǔ)設(shè)施故障對(duì)業(yè)務(wù)的影響。
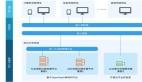
將故障范圍控制于單獨(dú)的主機(jī)之中
如果有可能,選擇一些服務(wù)項(xiàng)目以及基礎(chǔ)設(shè)施來(lái)模擬主機(jī)發(fā)生故障時(shí)的狀況。通過(guò)建立一套簡(jiǎn)單的單主機(jī)服務(wù)系統(tǒng)(而不是引入多臺(tái)主機(jī)),我們就可以構(gòu)建出不受其它主機(jī)工作狀態(tài)影響的獨(dú)立服務(wù)供應(yīng)體系。
例如,如果我們的某個(gè)應(yīng)用程序包含A,B,C三種業(yè)務(wù)邏輯組成部分,那么每一部分都要運(yùn)行于獨(dú)立的主機(jī)之上。我們當(dāng)然可以將服務(wù)群組設(shè)置為(A,B,C),(A,B,C)……或者我們也可以創(chuàng)建一套組件池(A,A,…),(B,B,…),(C,C,…)。如果我們選擇了前一種方案,那么單個(gè)主機(jī)發(fā)生故障將會(huì)使整套系統(tǒng)群組遭到破壞。將資源拆開(kāi)并分配給獨(dú)立的池則能夠在單個(gè)主機(jī)發(fā)生故障時(shí)只會(huì)對(duì)該主機(jī)本身的功能性造成影響。我們會(huì)在另一篇文章中向大家介紹上述方案的其它優(yōu)勢(shì)及存在的缺陷。
極短超時(shí)與快速重試
當(dāng)故障發(fā)生時(shí),我們有相應(yīng)的軟件快速識(shí)別那些失敗及重復(fù)提交的請(qǐng)求。通過(guò)為每項(xiàng)服務(wù)運(yùn)行多個(gè)冗余副本的方式,我們可以使用快速超時(shí)及重試來(lái)對(duì)無(wú)法執(zhí)行或連接失敗的服務(wù)器進(jìn)行路由操作。
1. 提出請(qǐng)求,若該請(qǐng)求返回的是一條暫時(shí)性錯(cuò)誤提示或是短時(shí)間內(nèi)沒(méi)有響應(yīng)(這個(gè)短時(shí)間到底有多短,可以根據(jù)大家的應(yīng)用程序類型而定)
2. 對(duì)另一臺(tái)服務(wù)器重復(fù)上述請(qǐng)求
3. 繼續(xù)對(duì)另一臺(tái)服務(wù)器重復(fù)上述請(qǐng)求
如果不迅速采取上述措施,分布式系統(tǒng)——尤其是那些按序處理或是基于線程的類型——很有可能會(huì)把運(yùn)算資源浪費(fèi)在等待緩慢甚至完全無(wú)響應(yīng)的服務(wù)器上。
冪等服務(wù)接口
構(gòu)建服務(wù)器要求能夠安全地對(duì)某項(xiàng)請(qǐng)求進(jìn)行重復(fù)操作。如果大家對(duì)“冪等”這個(gè)概念不太熟悉,可以先讀讀“冪等領(lǐng)域的精彩世界”一文。
“在計(jì)算機(jī)科學(xué)當(dāng)中,冪等這個(gè)術(shù)語(yǔ)被用來(lái)全面地形容一種在執(zhí)行了一次或是多次的情況下始終產(chǎn)生相同結(jié)果的操作。”
如果某臺(tái)服務(wù)器的API符合冪等定義,那就意味著其在失敗請(qǐng)求進(jìn)行重試的過(guò)程中是安全的(即我們?cè)谇拔牡?條中所描述的內(nèi)容)。例如,如果某臺(tái)服務(wù)器提供這樣一種功能,將指定數(shù)目的資金匯入另一位用戶的賬號(hào)當(dāng)中,那么具備冪等接口也就意味著該項(xiàng)請(qǐng)求若是提交失敗,則無(wú)論重復(fù)提交多少次,都不會(huì)造成預(yù)期之外的負(fù)面效果。關(guān)于這個(gè)話題其實(shí)有很多內(nèi)容可談,我們以后會(huì)就更多細(xì)節(jié)展開(kāi)深入的討論。
小型無(wú)狀態(tài)服務(wù)
將邏輯業(yè)務(wù)獨(dú)立為小型無(wú)狀態(tài)服務(wù)能夠使其更容易地通過(guò)均等的池加以組織。Twilio的基礎(chǔ)設(shè)施中包含了許多分別實(shí)現(xiàn)API不同功能部分的服務(wù)池。例如,當(dāng)大家在TwiML中使用<Record>指令來(lái)進(jìn)行錄音時(shí),對(duì)錄制內(nèi)容進(jìn)行后期處理以改善音質(zhì)并進(jìn)行上傳存儲(chǔ)的工作是由錄制服務(wù)中的某個(gè)池來(lái)完成的。無(wú)狀態(tài)池錄制服務(wù)允許上游服務(wù)通過(guò)不同的錄制服務(wù)器對(duì)失敗的請(qǐng)求進(jìn)行重試。此外,錄制服務(wù)池的大小在負(fù)載進(jìn)行中也很容易加以調(diào)節(jié)。
放寬對(duì)一致性的要求
當(dāng)對(duì)信息的一致性沒(méi)有太高要求時(shí),為復(fù)制及重復(fù)讀取數(shù)據(jù)創(chuàng)建對(duì)應(yīng)的池。大家能在應(yīng)用程序?qū)用嫠渴鸬淖钪匾姆桨钢痪褪菍?shù)據(jù)的讀取與寫入分別處理。例如,如果某個(gè)巨大的數(shù)據(jù)池在寫入方面的操作極少,就應(yīng)該將數(shù)據(jù)的讀取與寫入分別進(jìn)行處理。通過(guò)這種區(qū)分,對(duì)應(yīng)的池就能夠獨(dú)立創(chuàng)建一套可供服務(wù)請(qǐng)求重復(fù)讀取的數(shù)據(jù)副本。例如,當(dāng)服務(wù)器整體的數(shù)據(jù)寫入表現(xiàn)良好而數(shù)據(jù)讀取表現(xiàn)較差時(shí),我們可以通過(guò)增加讀取服務(wù)池的數(shù)量來(lái)改善接收及運(yùn)行讀取請(qǐng)求的效果。
AWS的事故說(shuō)明我們需要認(rèn)真反思一下自己云托管應(yīng)用程序的設(shè)計(jì)是否合理。我們已經(jīng)著重強(qiáng)調(diào)了幾種知名的分布式系統(tǒng)設(shè)計(jì)的亮點(diǎn),而當(dāng)我們決定將其作為外部服務(wù)整合進(jìn)Twilio之后,它們也確實(shí)在工作中起到了良好的作用。
AWS事故的關(guān)鍵癥結(jié)在于Amazon彈性模塊存儲(chǔ)(簡(jiǎn)稱EBS)服務(wù)。我們?cè)赥wilio中使用了EBS方案,但只應(yīng)用于那些不太重要且對(duì)延遲不太敏感的任務(wù)上。我們?cè)趯BS引入自己設(shè)施的核心部分方面一直有所保留,因?yàn)樗环衔覀兯非蟮?ldquo;局部故障只影響某臺(tái)單獨(dú)的主機(jī)”這一原則。如果EBS一旦發(fā)生問(wèn)題,所有相關(guān)的服務(wù)也很可能同時(shí)陷入癱瘓。相反,我們一直堅(jiān)持在每臺(tái)EC2主機(jī)上都部署額外的臨時(shí)硬盤。如果某塊臨時(shí)硬盤出了問(wèn)題,該問(wèn)題也只會(huì)影響硬盤所在的主機(jī)。我還計(jì)劃向大家介紹如何將臨時(shí)硬盤構(gòu)建為RAID0以提高讀寫性能,感興趣的朋友們可以繼續(xù)關(guān)注我們的博客。
原文:Why Twilio Wasn’t Affected by Today’s AWS Issues
【編輯推薦】